各位佬友们大家好,我在做一个AI日报,今天是第100期,每次整理都是Markdown格式,打算在咱们社区也发一下,每周一到周五都会发,喜欢的可以点个赞。只要我没发过,链接都是直链,欢迎监督!
我不知道能不能发我自己的网站,先不发了,能发的话下期我发个网站,主要是有搜索功能,好了不多bb,开始 linux do 的第一期!。
今天周一,含周末的内容:
省流:
![]() 字节 LLaVA-OneVision:开源多模态大模型
字节 LLaVA-OneVision:开源多模态大模型
![]() Meta VFusion3D:利用视频扩散模型生成 3D
Meta VFusion3D:利用视频扩散模型生成 3D
![]() Master Comfy:按需求查找 ComfyUI 自定义节点
Master Comfy:按需求查找 ComfyUI 自定义节点
![]() sd-webui-comfyui:将工作流集成到 WebUI
sd-webui-comfyui:将工作流集成到 WebUI
![]() 阿里 Qwen2-Audio:开启语音对话
阿里 Qwen2-Audio:开启语音对话
![]() Deep-Live-Cam:最火实时换脸
Deep-Live-Cam:最火实时换脸
![]() ComfyUI-Veevee:Video2Video 框架
ComfyUI-Veevee:Video2Video 框架
![]() XLabs-AI/flux-lora-collection:Flux LoRA 大集合
XLabs-AI/flux-lora-collection:Flux LoRA 大集合
![]() 大语言模型可视化:3D 交互式 GPT 工作原理
大语言模型可视化:3D 交互式 GPT 工作原理
![]() 谷歌 Imagen 3:现已面向所有人开放使用
谷歌 Imagen 3:现已面向所有人开放使用
字节 LLaVA-OneVision:开源多模态大模型
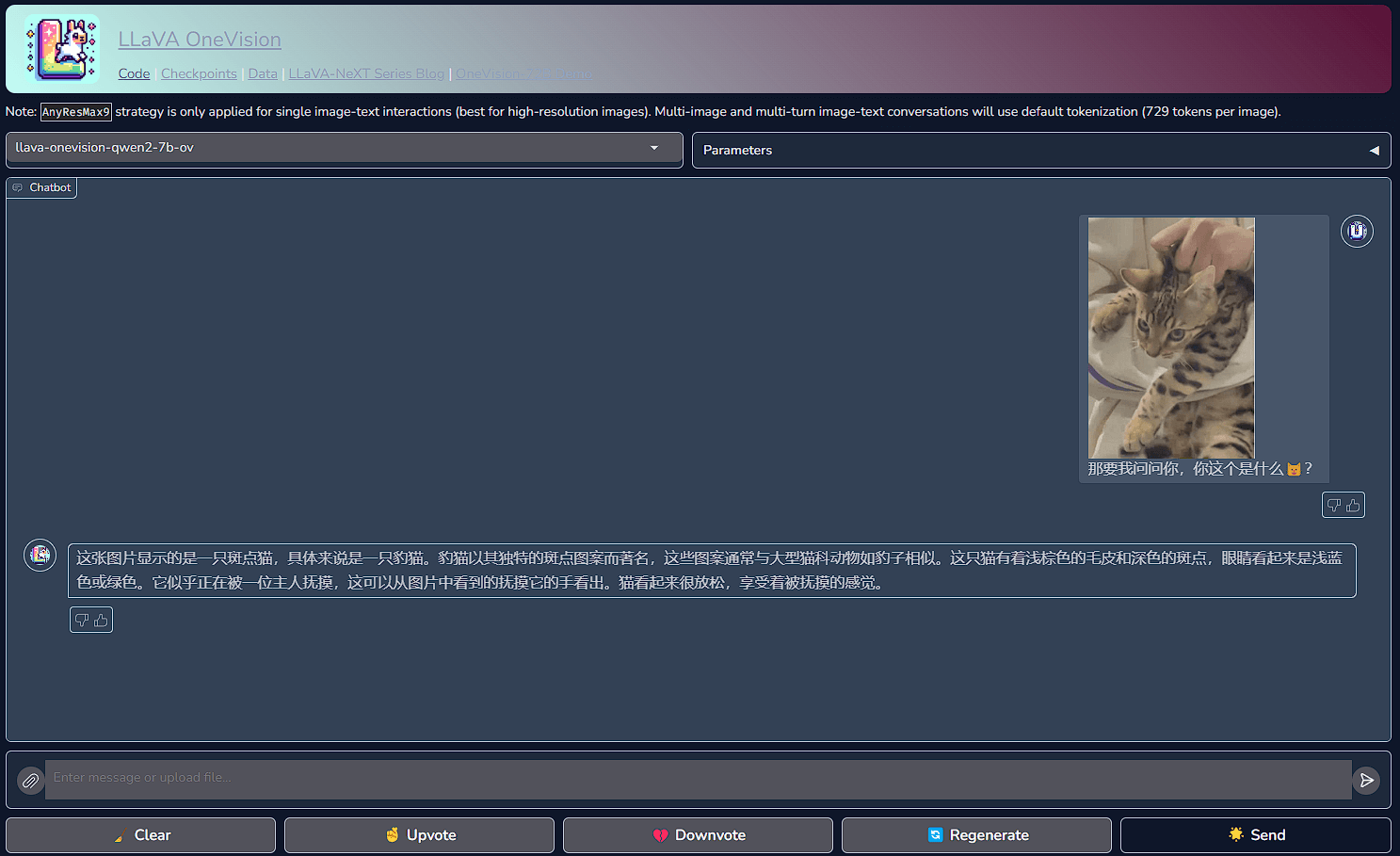
LLaVA-OneVision 是之前介绍的LLaVA-NeXT 的进化版本,支持单图、多图和视频,比上一代实现了显著的性能提升和更广泛的应用能力,在各种基准测试上接近 GPT4,可以在这里免费试用。
Meta VFusion3D:利用视频扩散模型生成 3D
今天这个 VFusion3D 是由 Meta 提出并开源的创新方法,即通过利用大量数据训练的视频扩散模型来解决 3D 数据获取困难的问题,进而训练出一个能够从单图生成 3D 的模型,在用户偏好度测试中,获得了 90% 的选择率,可以在这里免费试用。
Master Comfy:按需求查找 ComfyUI 自定义节点
Master Comfy 是由 ComfyDeploy 推出一个用于查找自定义节点的小工具,你可以直接输入你的需求然后就会返回推荐的自定义节点,当然也可以当作节点文档大集合。
此前我一直在用的是 ComfyUI 作者推荐的一个文档:SaltAI Docs,与上面的不同,这个是传统的基于关键词查找的,当然好处是数据也是开源的,你可以基于它做二次开发,例如做一个你的 Master Comfy
sd-webui-comfyui:将工作流集成到 WebUI
sd-webui-comfyui 是一个开源的 A1111 webui 扩展,它支持将 ComfyUI 的工作流嵌入到 WebUI 的流程中,例如预处理或后置处理等,极大的提升了 WebUI 的可玩性。
阿里 Qwen2-Audio:开启语音对话
阿里 Qwen2-Audio 是 Qwen-Audio 的下一代版本。这个新版本能够接受音频和文本输入,并生成文本输出,可以在Qwen2-Audio Collections下载模型和试用演示。
主要特性如下:
- 语音聊天:使用语音直接向模型发出指令,而无需自动语音识别(ASR)模块。
- 音频分析:支持分析包括语音、声音、音乐等在内的音频信息,并结合文本指令进行处理。
- 多语言支持:支持超过 8 种语言/方言,例如中文、英语、粤语、法语、意大利语、西班牙语、德语和日语。
Deep-Live-Cam:最火实时换脸
Deep-Live-Cam 是这两天最火的一个换脸软件,只需要一张照片即可进行换脸直播,需要 6G 显存。支持 Nvidia 或者 AMD 显卡,GitHub Releases 只提供了 CUDA 版本,DML 版本可以在这里下载,有需要国内网盘的话评论一下我上传下。
ComfyUI-Veevee:Video2Video 框架
ComfyUI-Veevee 是一个用于 ComfyUI 中文本图像模型的 Video2Video 框架。项目目前还非常早期,支持 SD1.5 和 SDXL,有需要的可以尝试下。
XLabs-AI/flux-lora-collection:Flux LoRA 大集合

由 XLabs-AI 训练的 Flux LoRA 大集合,包括福瑞、MJv6、动漫、迪士尼、风景、艺术共 6 个 LoRA 模型
大语言模型可视化:3D 交互式 GPT 工作原理
LLM 可视化允许用户以 3D 交互式观察和理解一个 GPT 风格的大语言模型在进行推理时的工作原理,对学习了解 LLM 非常有帮助,也可用于教学演示。这里还有一个中文版
这个项目源自 llm-viz,作者还有一个正在开发的 CPU 模拟器
谷歌 Imagen 3:现已面向所有人开放使用
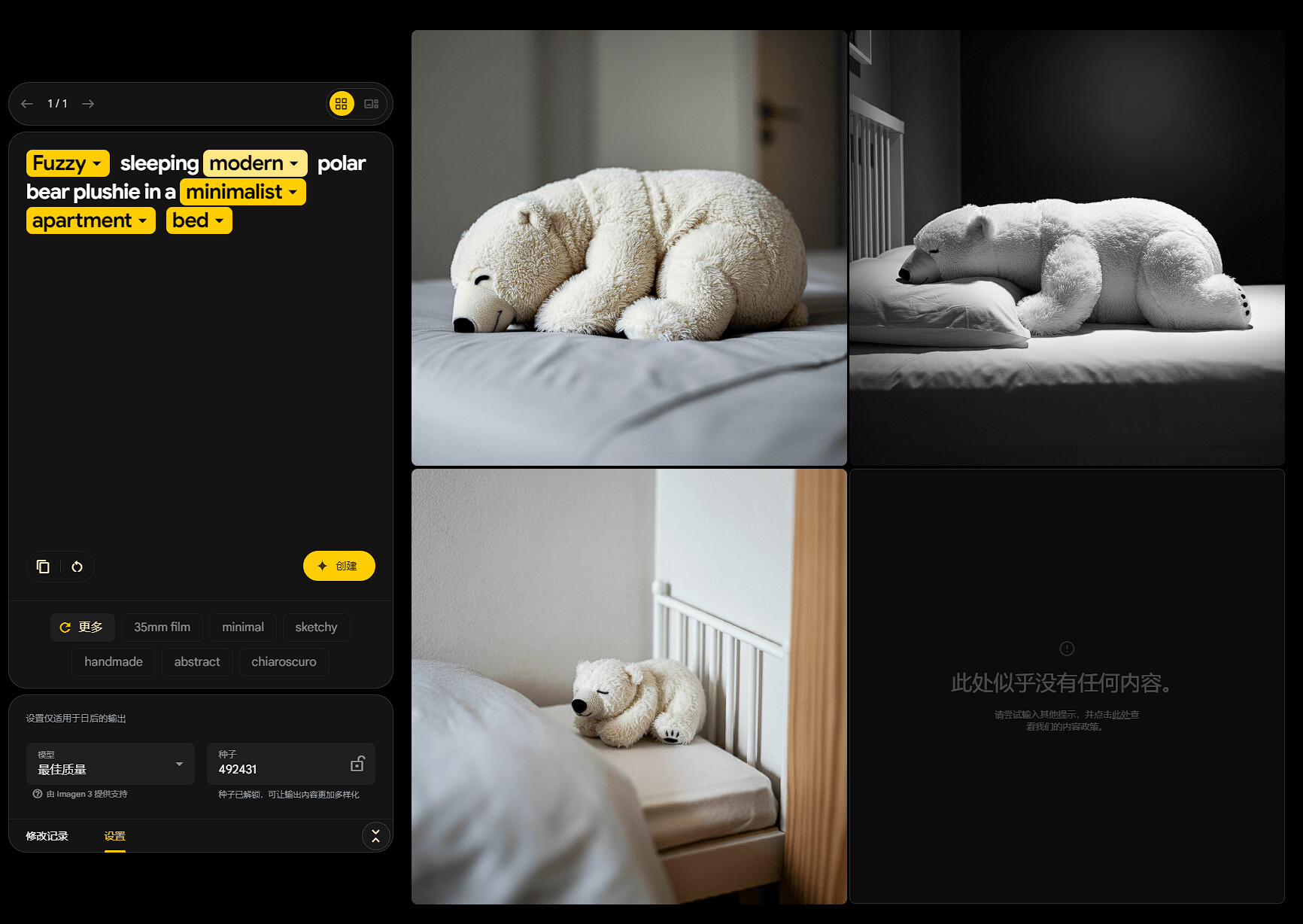
谷歌 Imagen 3,8 月 2 号才收到测试权限,10 号就全面公开了,生成速度非常的快,质量感觉不如测试时的高,支持英文文字,手部效果非常不错,提示词交互也很不错。
似乎还有一个检测模型,如果生成的质量不好或者令人不适就会提示“此处似乎没有任何内容”