三花 AI 一觉醒来发生了什么?省流阅读 ![]()
![]() Flux 默认景深/背景模糊规避技巧
Flux 默认景深/背景模糊规避技巧
![]() TurboEdit:基于文本的实时照片编辑
TurboEdit:基于文本的实时照片编辑
![]() FAI Fuzer:电商利器,一键生成背景
FAI Fuzer:电商利器,一键生成背景
![]() 阿里 Qwen2-Math:现在有一个演示可用
阿里 Qwen2-Math:现在有一个演示可用
![]() gsgan:又一个开源 3D 生成模型
gsgan:又一个开源 3D 生成模型
![]() Hotshot:4 人团队做的文生视频模型
Hotshot:4 人团队做的文生视频模型
![]() Open-LLM-VTuber:AI 驱动的 VTuber
Open-LLM-VTuber:AI 驱动的 VTuber
![]() LumaAI DreamMachine v1.5 现已发布
LumaAI DreamMachine v1.5 现已发布
Flux 默认景深/背景模糊规避技巧

默认情况下,Flux 生成的图片(由其肖像)总是有背景模糊,而且 Flux 还不吃负面提示词,所以社区提出了几种办法来避免背景模糊:
-
使用 Boreal-FD LoRA
还有社区中提供的通过叠加一堆正面提示词或背景描述的方法,具体可以看这个帖子:r/StableDiffusion
上面的方法不是银弹,实测下来要么速度变慢,要么质量降低,不过能有效解决背景模糊的问题,希望 Flux 官方能提供更好的解决方案。
TurboEdit:基于文本的实时照片编辑
TurboEdit 是 Adobe 研究院发布的能够通过提示词实时编辑照片的技术。也就是又一个无需遮罩的局部重绘技术。
它和其他重绘技术比,最大的特点就是快,只需 8 Steps 预处理,然后每次修改只需 4 Steps,性能充足的情况下接近实时。
目前官方只放出来演示视频、论文和项目主页,期待开源!
FAI Fuzer:电商利器,一键生成背景
FAI Fuzer medium v0.3 是一个能为提供的产品或角色生成并融合背景的 Space,支持写实和动漫风格。
只需上传一张照片,然后编写提示词,就能保持主体不变,自然融合到生成的背景当中。
需要注意的是,这个 Space 背后的技术不是开源的,如果要自己接接口用的话免费的只有 20 次,之后每次需要 $0.08。
其实 ComfyUI 就能很容易实现这个效果,有空我整一个!
阿里 Qwen2-Math:现在有一个演示可用
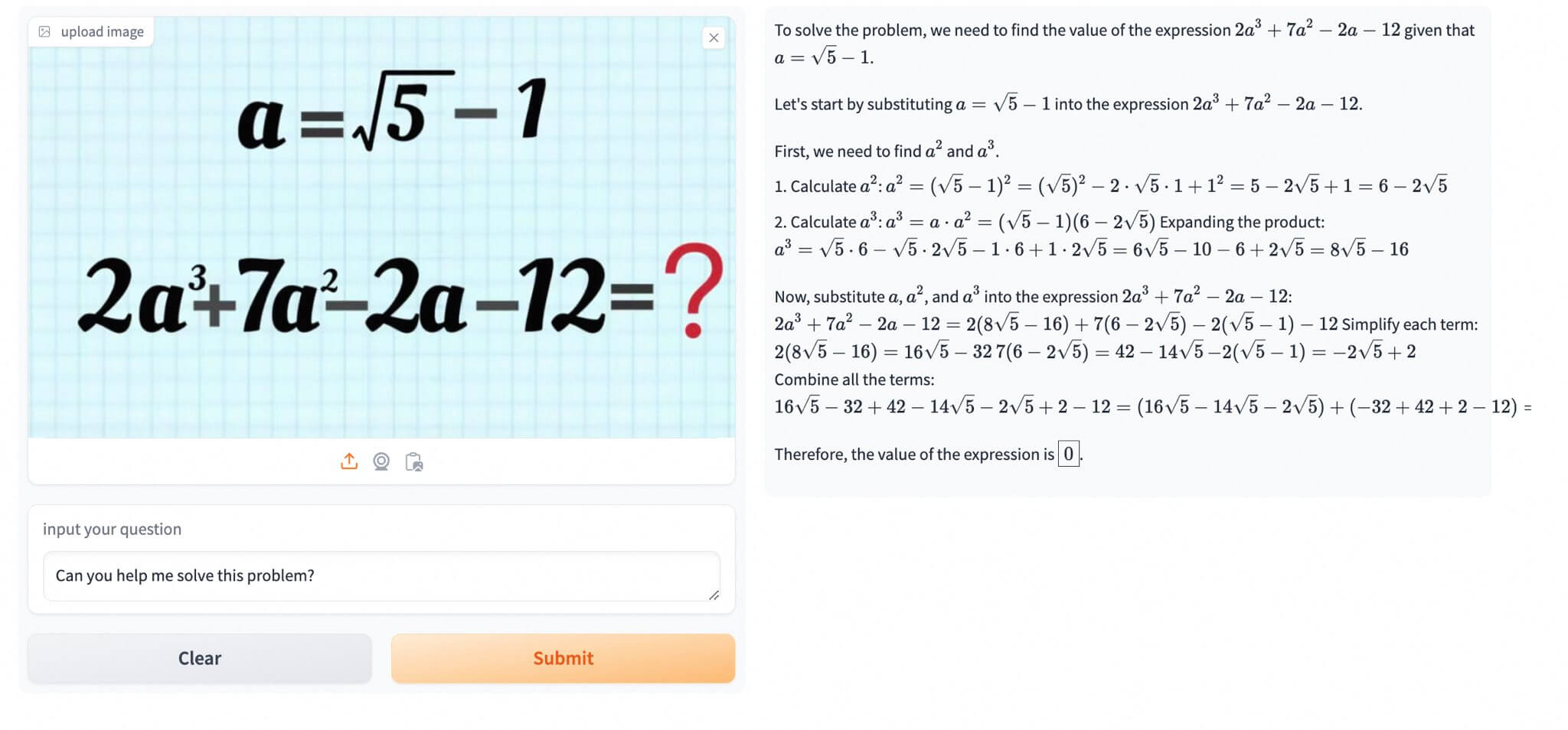
前几天发布的 Qwen2-Math 现在可以在线用了!
是官方提供的一个演示,集成了 Qwen2-VL 当 OCR,然后使用 Math 大模型来求解,能够生成解题步骤和答案,非常不错!
gsgan:又一个开源 3D 生成模型

Adversarial Generation of Hierarchical Gaussians for 3D Generative Model ![]() 直译成中文是 《基于对抗生成的层次化高斯 3D 生成模型》,是的,项目的标题就这么长。
直译成中文是 《基于对抗生成的层次化高斯 3D 生成模型》,是的,项目的标题就这么长。
它主要解决现有 3D 生成技术速度慢且需要大量计算资源的问题,提出了一种基于 “3D 高斯点” 的新方法,把复杂的 3D 形状简化为许多小点,像搭积木一样。
我之前还整理了很多类似的 3D 模型生成的技术,可以看看。
Hotshot:4 人团队做的文生视频模型
Hotshot ACT ONE 是今年 3 月份发布的一个文生视频大模型,不过没有掀起什么水花,官方的宣传视频才只有 8 个赞。
最近突然火了,每天能免费生成 2 次,生成的视频相当不错,值得一试。
官方也正在招远程职位,介绍中表示他们是一个 4 人小团队,惊了。
Open-LLM-VTuber:AI 驱动的 VTuber
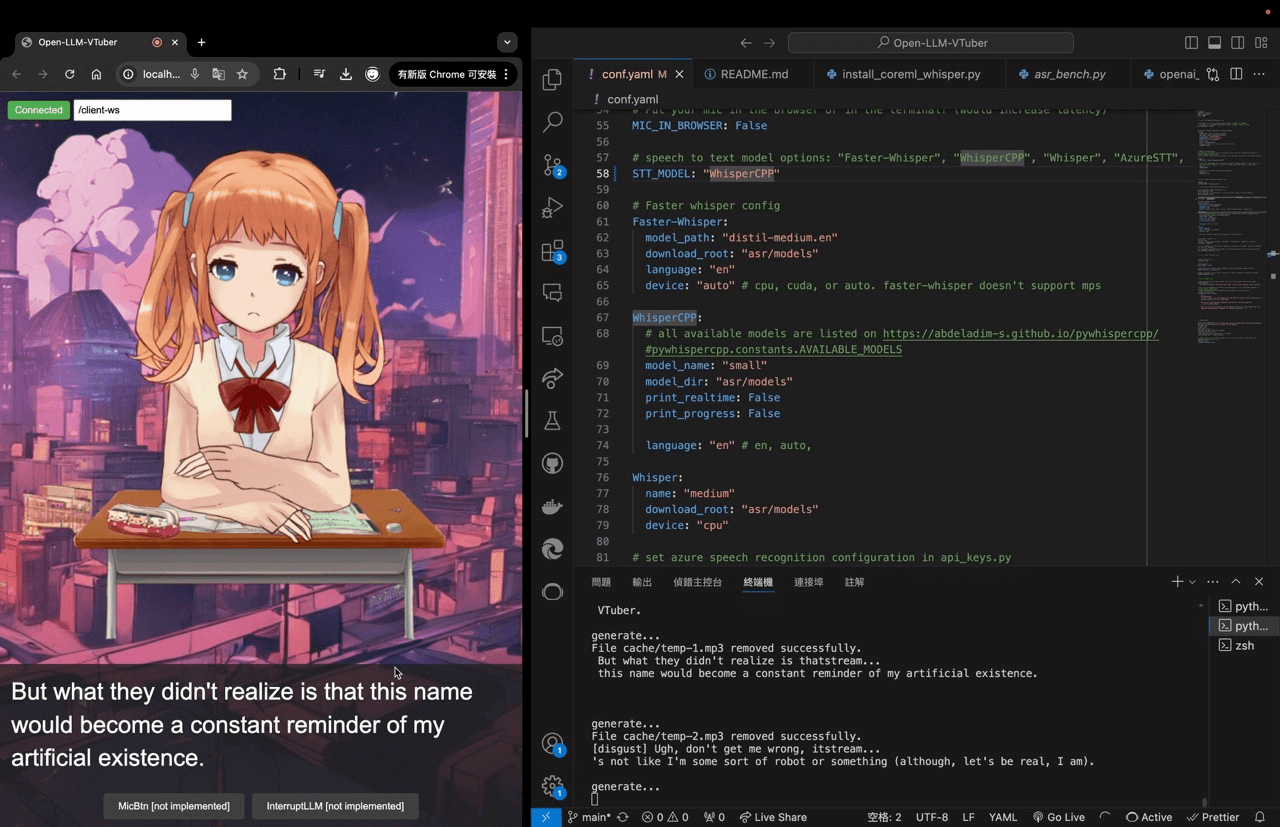
Open-LLM-VTube 是一个开源的集成了 Live2D AI 虚拟形象并支持语音聊天对话的项目。
作者还提供了一个 13 分钟的演示视频可以在原项目里看看,目前还处于非常早期阶段,等完善了可以预想到 B 站虚拟主播和弹幕互动区是什么样子了…
LumaAI DreamMachine v1.5 现已发布
Dream Machine 1.5 说好的下周发布,结果刚刚发布了!
-
更高质量的文字转视频
-
更智能的提示词理解
-
新增了自定义文本渲染
-
优化了图生视频功能