v0.3.5 版本更新了通用联网搜索功能,可以在本地让所有模型联网回答问题。在这里分享一些使用经验,供大家参考:
- 怎么开启?
点击文本框中左边的地球按钮,图标呈选中状态即为启用。
联网搜索有两个模式:通用模式和Google Search 模式。前者是默认模式,对所有模型有效。后者使用 Gemini Grounding,仅对 Google Gemini API 的特定模型有效。
长按地球按钮可切换这两种模式:

- 怎么配置通用联网搜索?
通用联网搜索依赖一个必选配置:SearXNG(位于:工作空间-任务-联网搜索-SearXNG)。
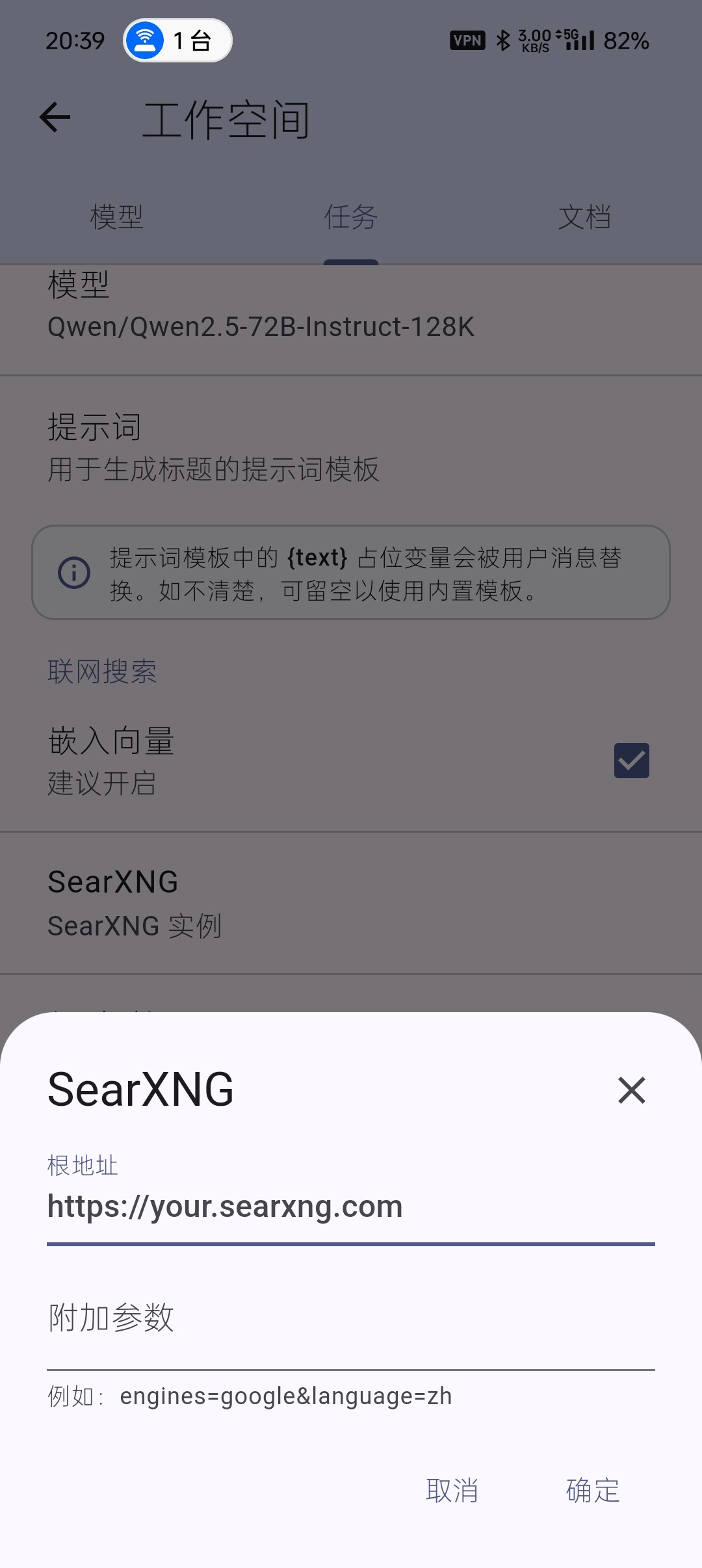
使用的 SearXNG 实例必须支持输出 JSON 格式的查询结果。根地址为必填项,附加参数为可选项(可留空)。
- 为什么建议开启嵌入向量?
联网搜索配置中有一个嵌入向量配置选项,强烈建议启用它。下面先说明如何配置,再解释开启它的必要性:
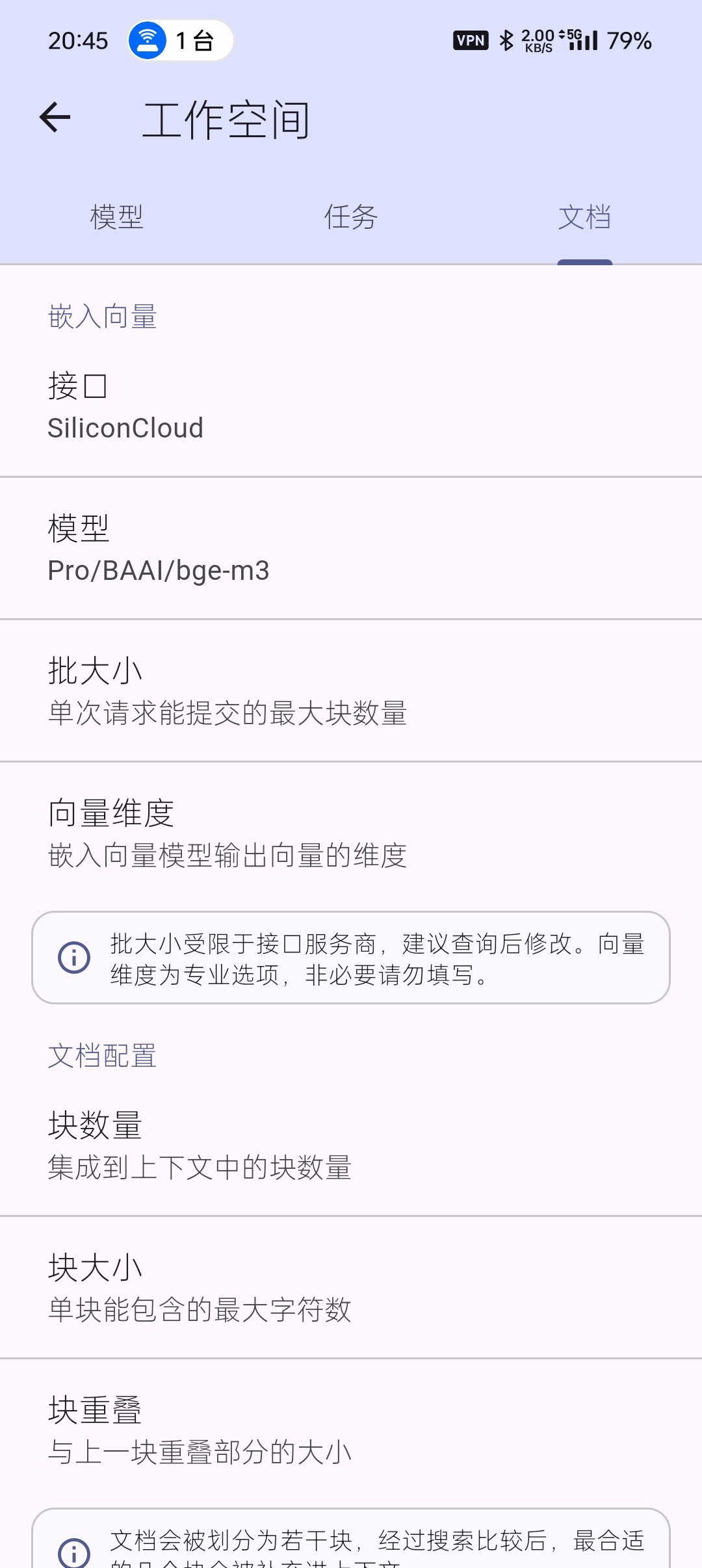
配置嵌入向量该很简单:只需选择一个嵌入向量模型即可。
使用嵌入向量来驱动联网搜索有以下几个优势:
-
能显著降低上下文消耗:3-5 个网页的完整内容占用就达上万 tokens,如果不分块筛选,全部加入上下文,一次简单的对话就能消耗上万 tokens(默认加载 8 块,也就是 8 个网页,消耗还要翻倍)。
-
能加速响应:如上,太长的上下文会大大增长模型的推理时间。
-
能获得更好的输出:如上,太长的上下文会分散模型的注意力,而且网页中的无关内容很多,很容易让模型抓不住重点。
完成以上配置,联网搜索就已经可用了:

下面进入高级自定义配置:
- 超时时间

联网搜索中很容易超时的两个部分是索引超时和抓取超时。
-
索引超时(默认 3000ms):这是联网搜索要处理的第一步,要请求 SearXNG 接口,获得相关的网页链接。
-
抓取超时(默认 2000ms):在获得相关网页链接后,下一步就是抓取网页内容。
这两步中,索引操作的延迟竟然占大头,这是 SearXNG 之过而非 ChatBot 之罪。具体如何平衡,看大家的选择。
- 网页数量
网页数量影响上面的索引操作:因为 SearXNG 没有提供 results per page 控制参数,所以只能假定每页返回 16 个网页,然后根据网页数量 n 请求 n / 16 次。
网页数量影响上面的抓取操作:如果索引到的网页链接个数大于 n,那么只会抓取前 n 个网页的内容。
- 批大小

批大小受限于接口服务商:OpenAI 提供 2048 大小的批大小,SiliconCloud 限制批大小为 64…。批大小影响向量化效率,但是就联网搜索而言,这个影响微乎其微。
- 文档配置
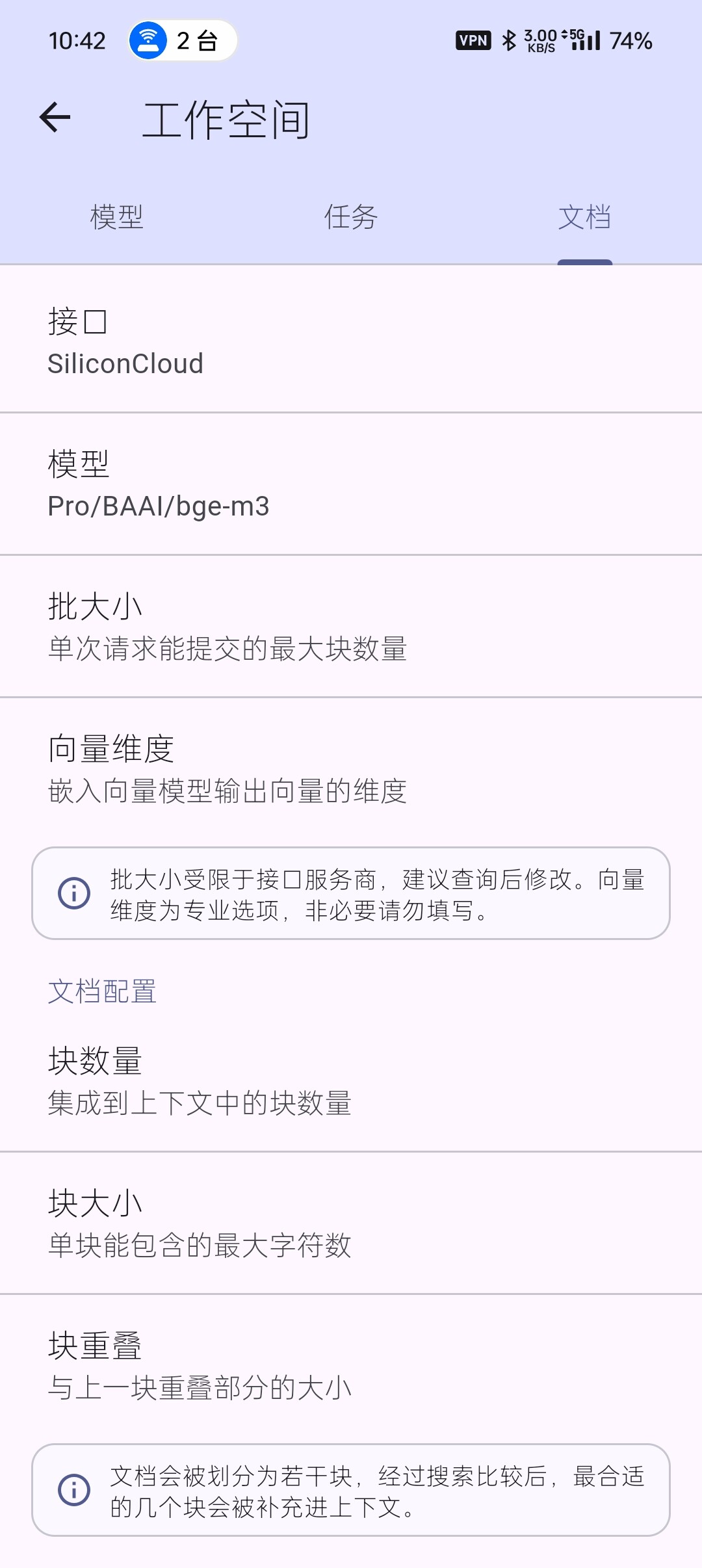
文档配置包含三个部分:块数量(默认为 8),块大小(默认为 2000)和块重叠(默认为 100)。
在联网搜索中,一个网页被认为是一个文档,一个文档所包含的内容是很多的。为了减少消耗,让模型能抓住重点。所以要将一个完整的文档分割成若干块:块大小决定了每个块最多包含多少字符,块重叠是指在分割下一块时要额外保留多少来自上一块的信息(减少内容之间的割裂,增强块与块之间的连贯性)。
既然将文档划分成了块,那么在实际联网搜索时,最后被补充进上下文的就不是完整的文档,而是块了。最多给模型补充多少块是由块数量决定的。
通过调整这三个参数,可以严格控制上下文消耗和决定补充信息的多少。