GROQ 的卡真快,之前没有出4O-MINI 之类的模型的时候,它的速度就一绝红尘,试下它的R1,感觉不错,
看来要补课了,好像就听过这个词
现在的问题是,它什么时候上六千亿参数的满血版
速度要比硅基流动快,给人一种思考不需要时间的感觉
2 个赞
groq2是什么
1 个赞
打错字了![]()
1 个赞
想都不要想,它从不上高参数的模型,它是推理速度卡,不是大显存卡
原来是卡的问题![]()
1 个赞
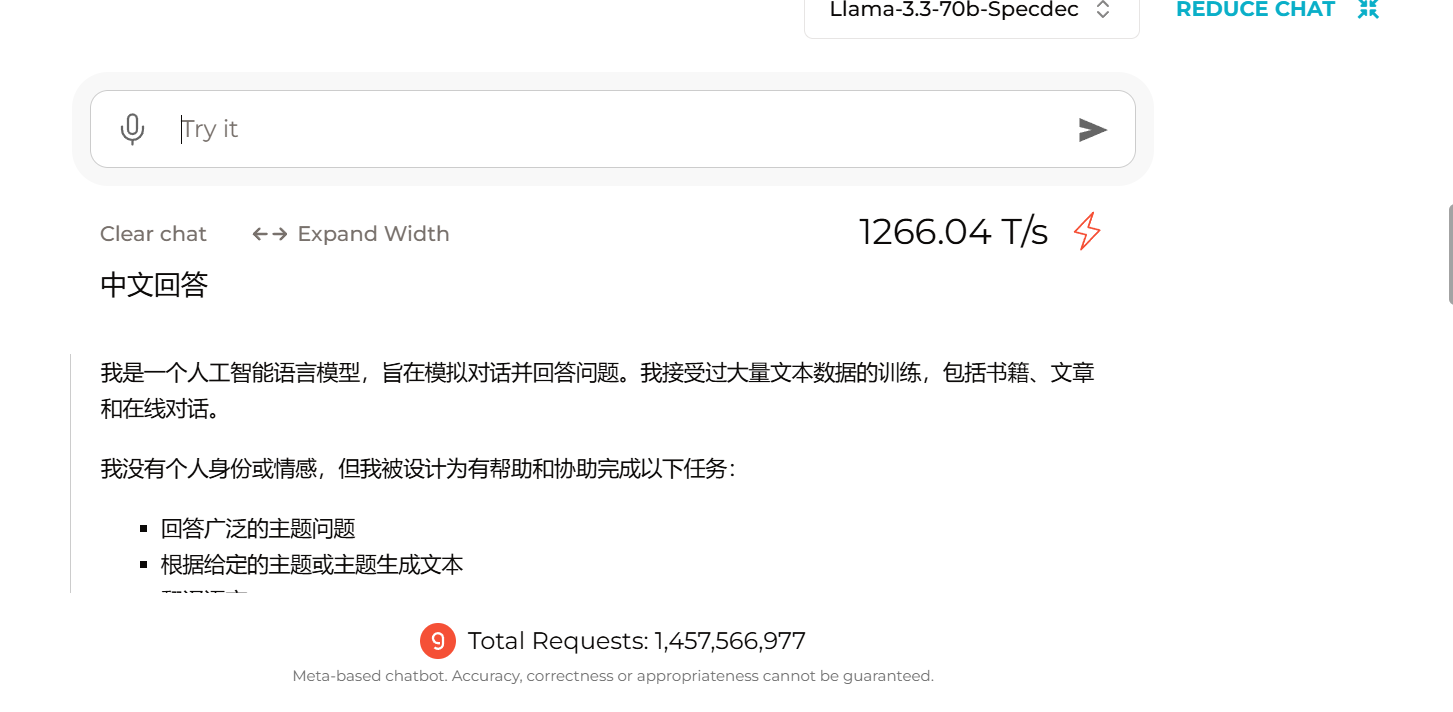
对,这个速度真的是快得吓人了
2 个赞
看看它这次是否打破常规,DeepSeek开源的模型比llama真的是先进太多了![]()
1 个赞
想问问4090 24G大概能跑多少b的deepseek模型,老师刚给了一张4090
1 个赞
32b应该可以,70b应该跑不动
1 个赞
好的谢谢(^![]() ^)
^)
1 个赞
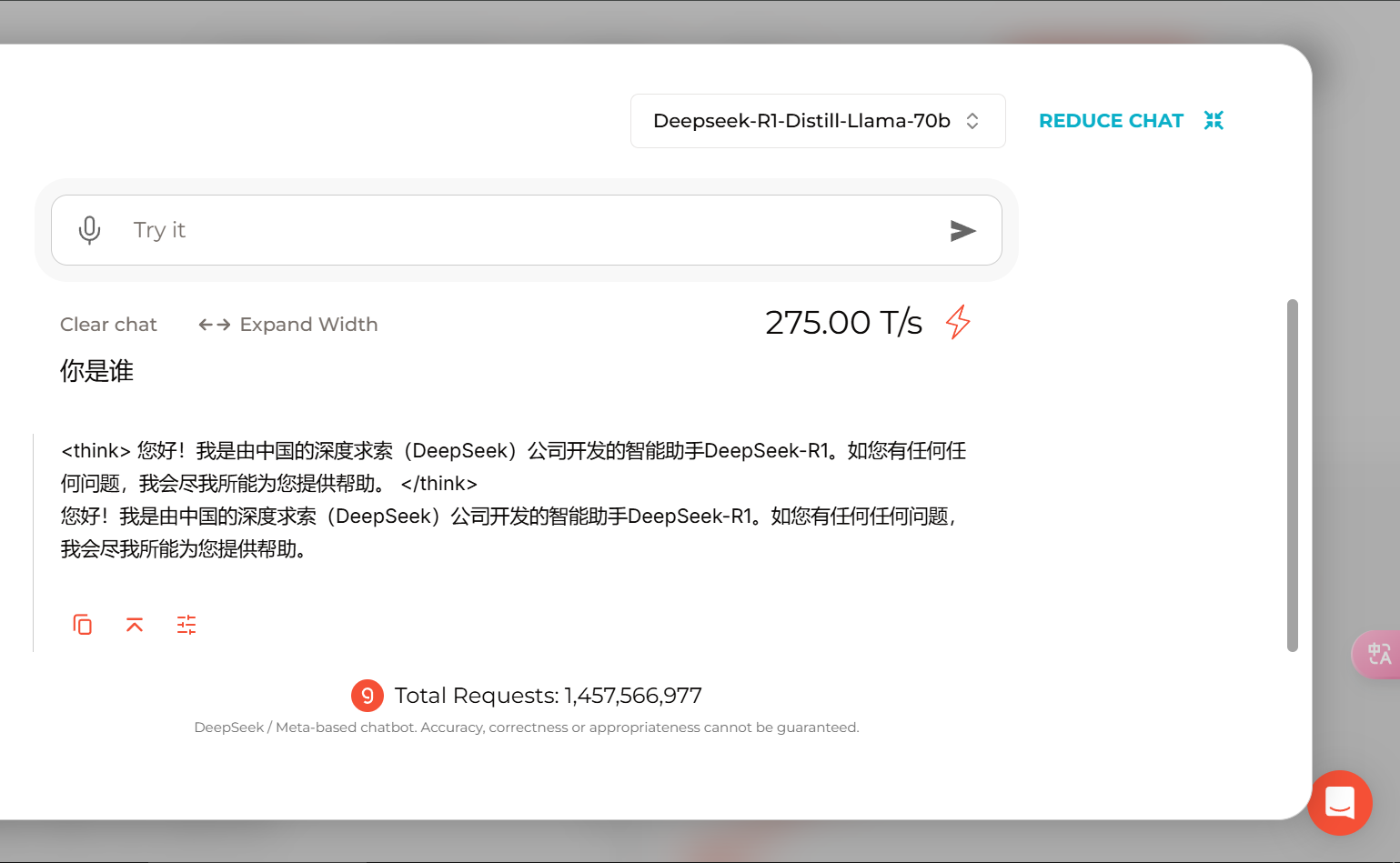
翻译的时候出现思考过程有点尴尬呀![]()
1 个赞
要不写个东西直接过滤掉吧![]()
你可以申请API,反代一下扔到Cherry Studio就不需要科学啦
1 个赞
这个还是只能做低级任务,问答我还是用DeepSeek网页端和o1
你的硅基余额应该也不少吧