部署 DeepScaleR-1.5B-Preview 模型的步骤如下:
1. 安装 Ollama 工具
确保你已安装 Ollama 工具,并正确配置了环境。
2. 选择合适的模型版本
该模型有多个版本,主要区别在于内存占用和硬件要求:
-
默认 fp16 版本:
使用命令:ollama run deepscaler
该版本占用约 3.6GB 内存,适合硬件配置较好的设备。
-
量化版本:
如果设备性能不足,建议使用量化版本,内存占用更低:ollama run deepscaler:1.5b-preview-q8_0,占用约 1.9GB 内存ollama run deepscaler:1.5b-preview-q4_K_M,占用约 1.1GB 内存

3. 部署命令说明
运行相应命令后,Ollama 会自动拉取并部署对应版本的模型。部署后,你就可以利用该模型进行推理任务了。
4. 模型特点概述
- 微调基础:该模型是基于 DeepSeek-R1-Distilled-Qwen-1.5B 进行微调的版本。
- 分布式强化学习:采用了分布式强化学习(RL)技术,可扩展到更长的上下文长度。
- 性能优势:在 AIME 2024 评测中,Pass@1 准确率达到 43.1%,相比基础模型的 28.8% 提升了 15%,仅 1.5B 参数的模型性能已超越 OpenAI 的 O1-Preview。
按照以上步骤操作,即可部署并开始使用 DeepScaleR 模型。
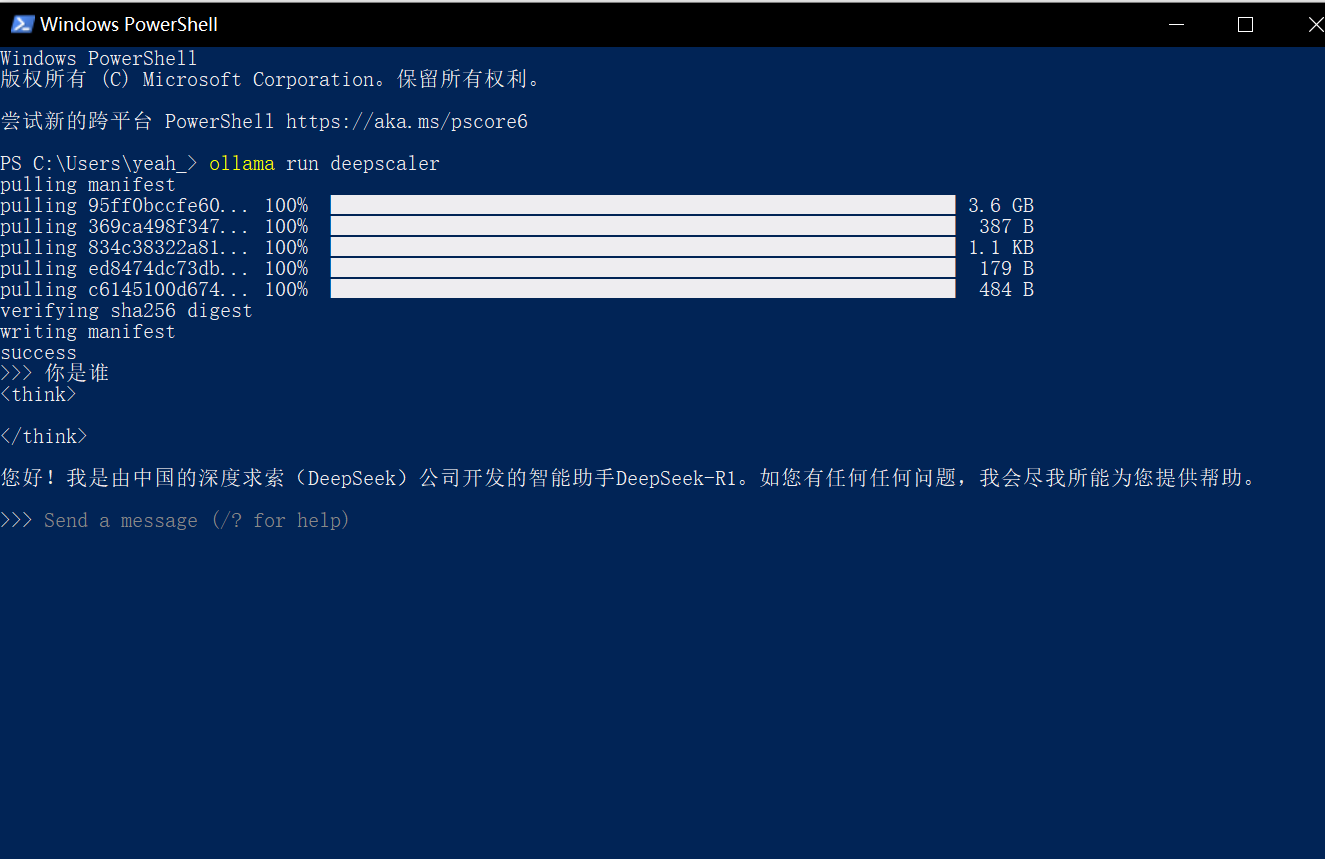
部署成功后的使用方式
部署成功后,你可以通过以下方式来使用这个模型:
1. 命令行交互
使用命令行直接启动模型,例如:
-
如果使用默认的 fp16 版本,可执行:
ollama run deepscaler -
如果设备性能有限,建议使用量化版本:
ollama run deepscaler:1.5b-preview-q8_0或者:
ollama run deepscaler:1.5b-preview-q4_K_M
启动后,终端会进入对话模式,你只需输入问题或指令,模型会根据提示返回回答。
2. API 集成
Ollama 提供 REST API 接口,你可以将模型集成到你的应用中。例如,可以使用 curl 命令向本地服务发送请求:
curl http://localhost:11434/api/chat -d '{
"model": "deepscaler",
"messages": [{"role": "user", "content": "请问今天的天气如何?"}]
}'
这样你就可以在自己的系统或前端界面中调用模型,实现自动化对话和其它任务。
3. 图形界面工具
除了命令行交互,你还可以结合第三方前端工具(如 Ollama 的 WebUI、AnythingLLM 或者 Open WebUI 等)来获得更友好的交互界面。只需确保你的服务已经启动(例如执行 ollama serve),然后通过这些工具连接到本地模型,即可享受类似 ChatGPT 的使用体验。
这些方式可以根据你的具体需求灵活选择。
如何解决英伟达 GPU 无法调用的问题?
安装驱动和 CUDA 工具
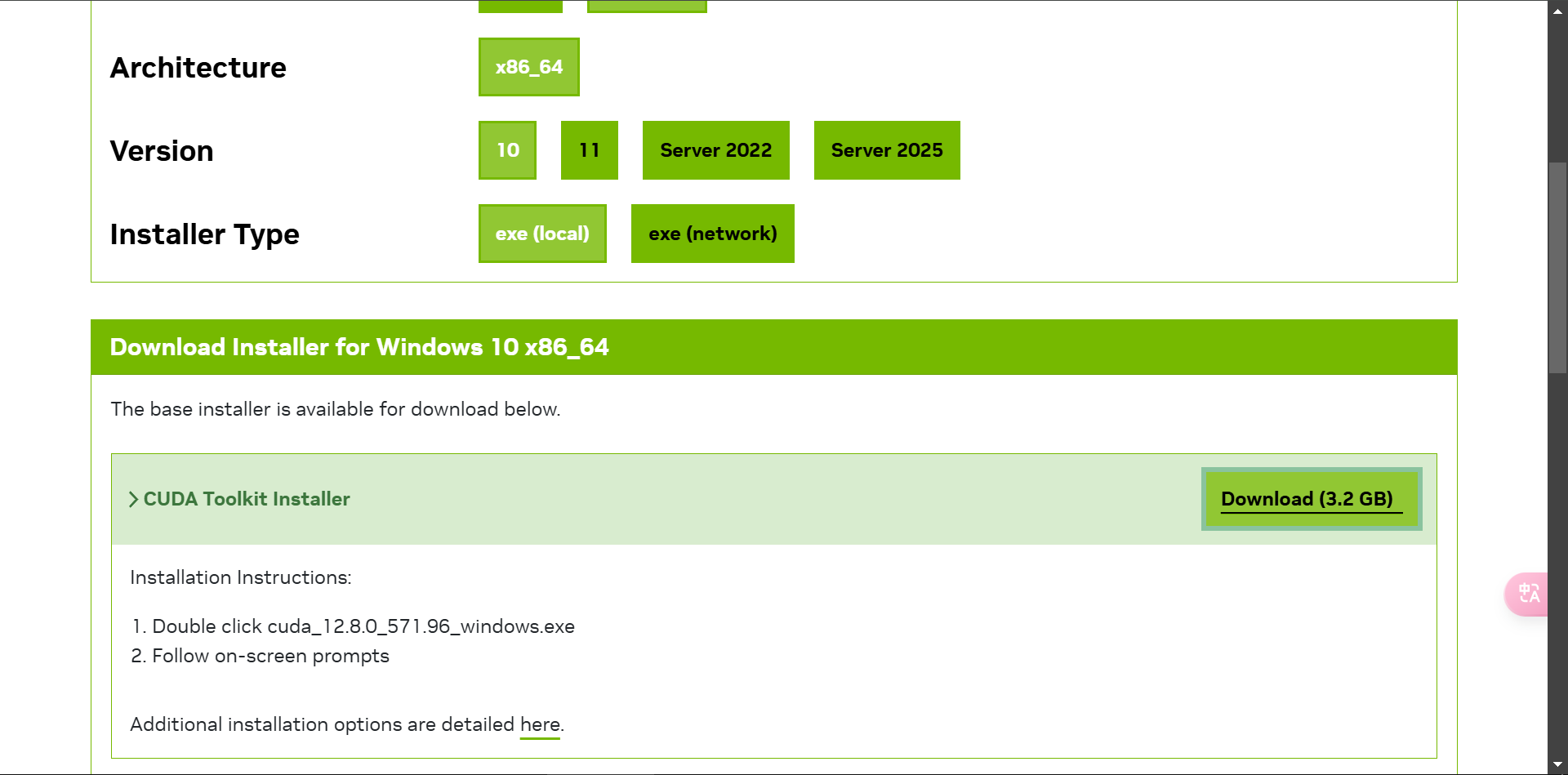

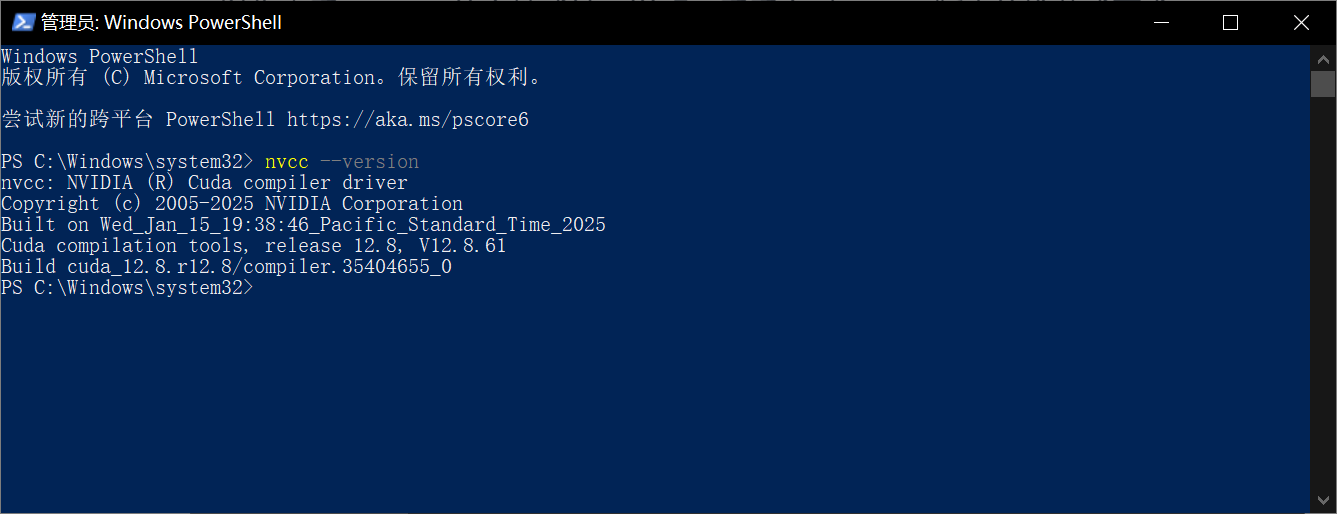
安装后重启,并通过 PowerShell 输入以下命令检查 CUDA 安装是否成功:
nvcc --version
实践测试

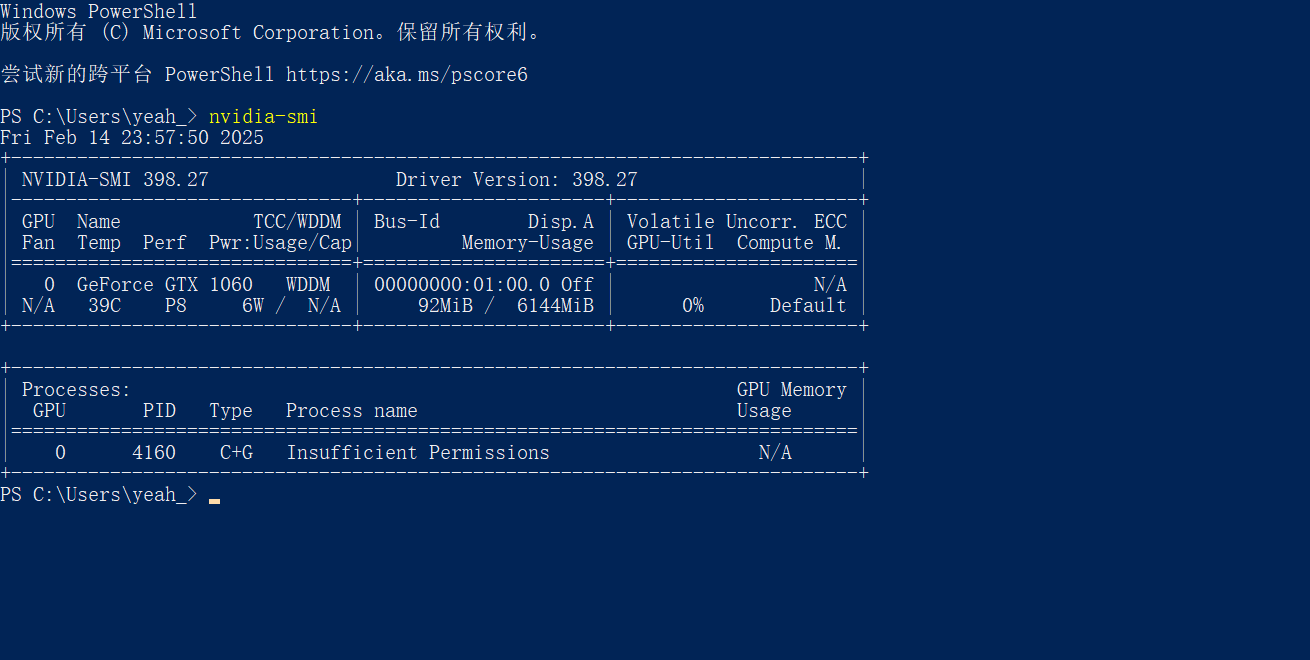
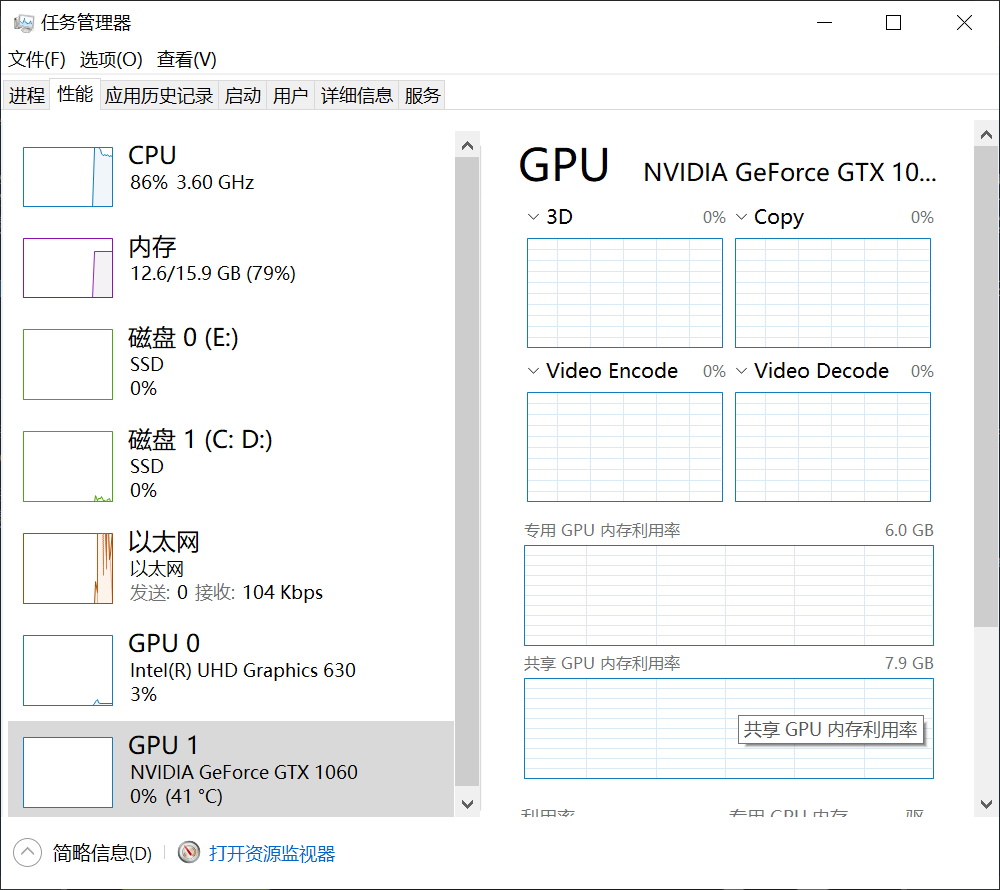
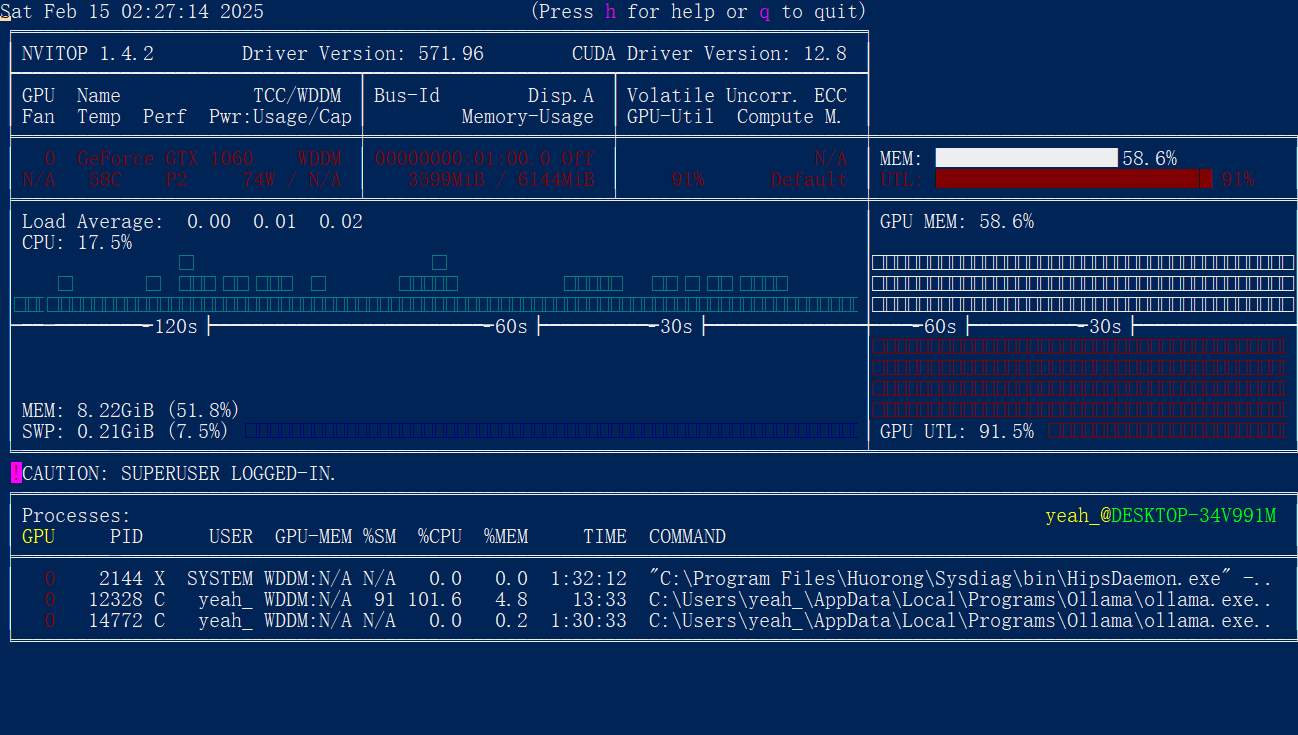
在语言模型输出时,CPU 占用率明显减少,语言模型输出速度明显提升,GPU 温度持续提升,表示已成功调用 GPU,但 GPU 占用率未显示。
建议使用 nvitop 来查看 GPU 占用
建议使用 pip 安装(也可通过 pipx、conda 或从 GitHub 拉取最新版本安装):
pip install nvitop
安装完成后,如果提示找不到命令,请检查 Python 脚本目录是否已添加到 PATH 中,或者直接使用:
python3 -m nvitop
Ollama命令行指令
设置会话变量
/set:设置会话变量。
加载或保存模型
/load <model>:加载会话或模型。/save <model>:保存当前会话。
管理会话
/show:显示模型信息。/clear:清除会话上下文。
退出
/bye:退出。
帮助
/?或/help:显示命令帮助。/? shortcuts:显示键盘快捷键帮助。