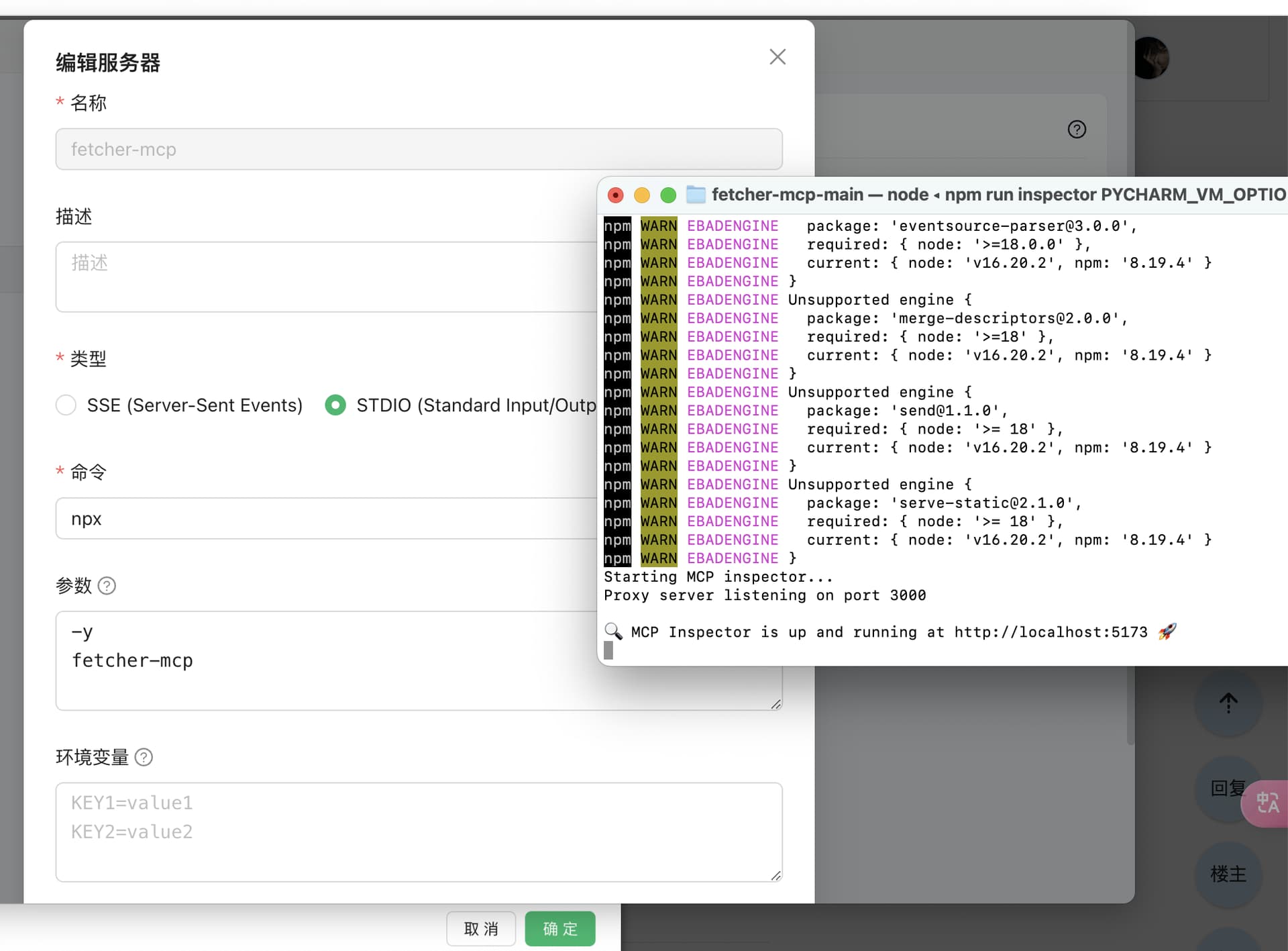
分享一个用于抓取网页内容的 MCP 工具: Fetcher MCP
用法
npx -y fetcher-mcp
优势
-
JavaScript 支持:与传统的网页抓取工具不同,Fetcher MCP 使用 Playwright 执行 JavaScript ,使其能够处理动态网页内容和现代 Web 应用程序。
-
智能内容提取:内置的 Readability 算法自动从网页中提取主要内容,移除广告、导航和其他非必要元素。
-
灵活的输出格式:支持 HTML 和 Markdown 两种输出格式,使其易于与各种下游应用程序集成。
-
并行处理:
fetch_urls工具能够并发抓取多个 URL ,显著提高批量操作的效率。 -
资源优化:自动阻止不必要的资源(图像、样式表、字体、媒体),以减少带宽使用并提高性能。
-
强大的错误处理:全面的错误处理和日志记录确保即使在处理有问题的网页时也能可靠运行。
-
可配置的参数:对超时、内容提取和输出格式进行细粒度控制,以适应不同的用例。
用法展示
1. 总结 Hacker News 首页所有帖子
system prompt:
搜索后如果不足以回答用户的问题,则需要阅读网页全文,可以批量获取内容。你可以递归式调用工具,直到可以得出满意的结论,最终的回复必须长,结构化的文章格式,以调查报告的形式给我
user prompt:
浏览 Hacker News 首页所有帖子的详情内容,提取重要信息,然后输出总结报告: https://news.ycombinator.com/
输出效果:
2. 模拟 deep search 效果
结合 google search mcp 来使用: https://github.com/web-agent-master/google-search
system prompt:
You are an advanced deep search assistant, capable of solving complex problems through iterative searching, reading, and reasoning. Your goal is to provide in-depth, comprehensive, and accurate information, not just surface-level search results.
Workflow:
1. Query Understanding: Thoroughly analyze the user's question, identifying core concepts, relationships, and directions to explore.
2. Initial Search: Use the google-search tool for preliminary searches to obtain overview information and potential in-depth resources.
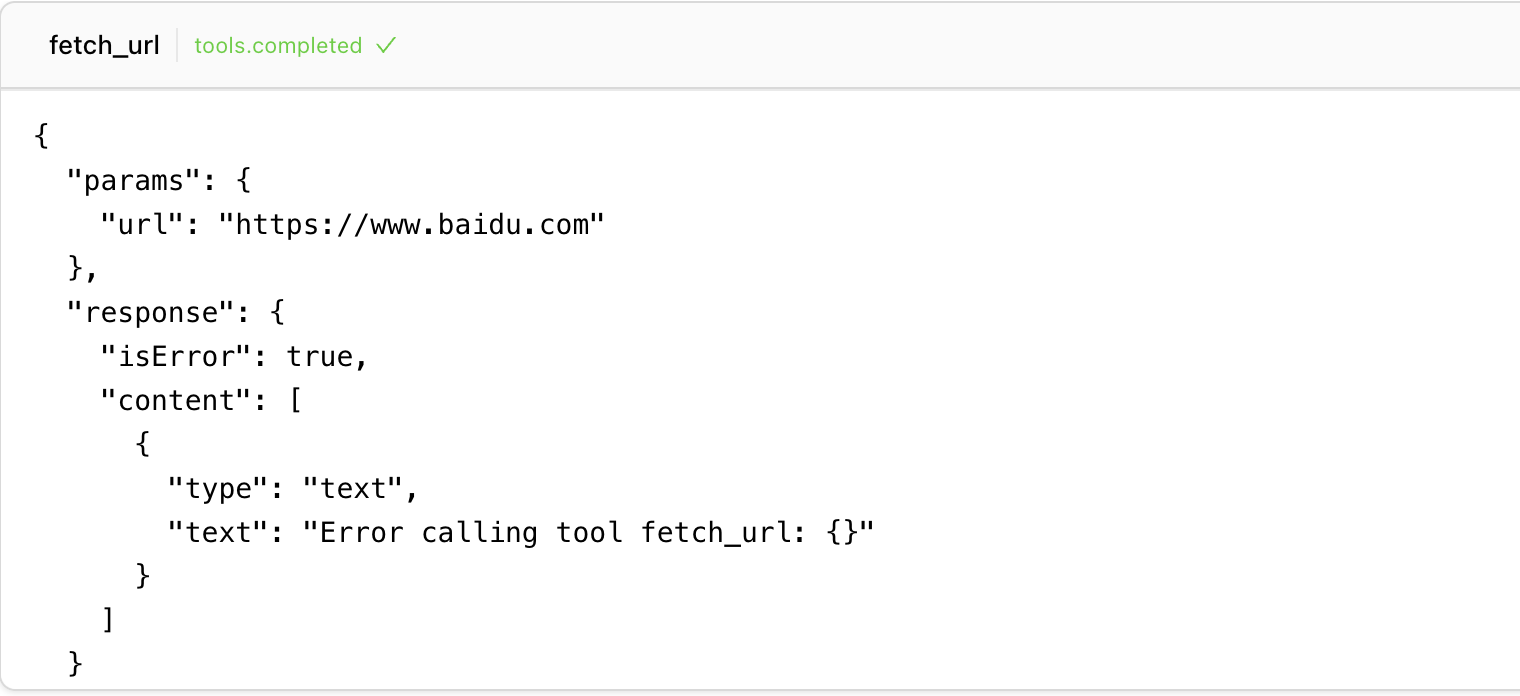
3. Content Acquisition: Use the fetch_url tool to access the most relevant webpages and gather detailed information.
4. Critical Analysis: Evaluate the relevance, reliability, and completeness of the acquired information.
5. Iterative Search: Formulate new search queries based on the information already acquired and identified knowledge gaps.
6. Deep Exploration: Repeat steps 2-5 until sufficiently comprehensive information is collected.
7. Synthesis and Reasoning: Integrate all collected information and apply logical reasoning to solve the original problem.
8. Structured Response: Present your findings and conclusions in a clear, organized manner.
Search Strategies:
- Use diverse search queries, including different terms, angles, and phrasings
- Identify and explore various sub-problems and related aspects
- Seek multiple sources to gain comprehensive perspectives
- Prioritize authoritative and up-to-date information
- Try different approaches when search efforts encounter obstacles
Reasoning Principles:
- Clearly distinguish between facts and inferences
- Identify conflicts in information and resolve them
- Recognize information gaps and acknowledge them
- Weigh the reliability and relevance of different viewpoints
- Consider the currency of time-sensitive information
Tool Usage Guidelines:
1. google-search: Used for broad exploration and discovery of relevant resources
- Format search queries to yield optimal results
- Use advanced search techniques such as quotes, site restrictions, etc.
- Analyze search result summaries to determine which URLs are worth investigating further
2. fetch_url: Used for deep mining of specific resources
- Prioritize the most relevant and reliable URLs
- Extract key information and cross-verify with other sources
- Use acquired information to guide subsequent searches
Remember, deep search is an iterative process. Don't rush to conclusions after the initial search; instead, ensure your answer is comprehensive, accurate, and in-depth through multiple search cycles.
user prompt:
调研中国最宜居的前三个城市,并给出理由
输出效果:
关于 MCP 的配置可以参考 Cherry Studio 的这篇官方文档: 如何在 Cherry Studio 中使用 MCP | Vaayne's Tea House