很速度,使用很丝滑。而且看训练对话的一些反馈,这位学霸专业且谦虚。 ![]()
![]()
![]()
![]()
![]()
![]()
2 个赞
站长这个称呼怎么有种谍战片的既视感,哈哈。大佬们都很强,很有格局。 ![]()
![]()
![]()
1 个赞
感谢分享
1 个赞
ollama把模型同步加载到显存,开放不同端口代表不同模型对吧,那这消耗显存有点大吧 ![]()
1 个赞
感谢大佬 我就使用在新版体验体验 哈哈哈 站在佬的肩膀上
1 个赞
专业
1 个赞
是,8B模型还好一点,不量化也就是16G,70B量化的也还有40G,比较难搞,现在感觉amd那种计算卡的价值在部署模型上很有优势
1 个赞
llama性能怎么样?比gpt4到底如何?
1 个赞
这个更适合中文,好啊
1 个赞
膜拜
1 个赞
阔以阔以,感谢分享
1 个赞
![]()
![]()
![]()
1 个赞
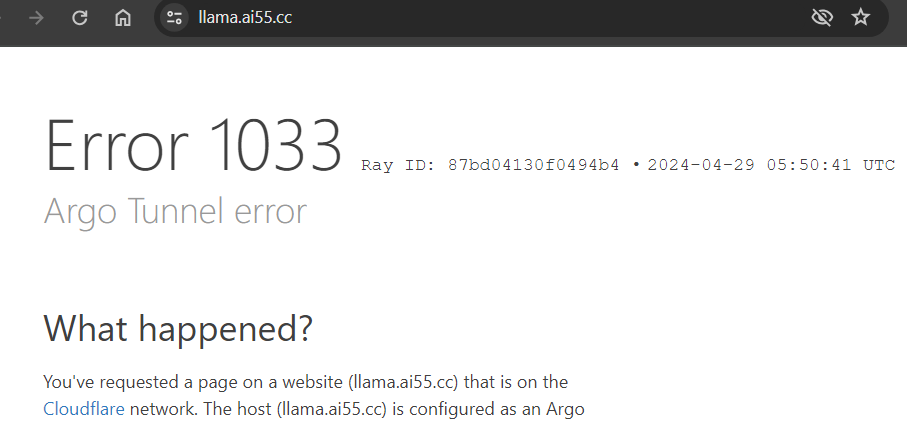
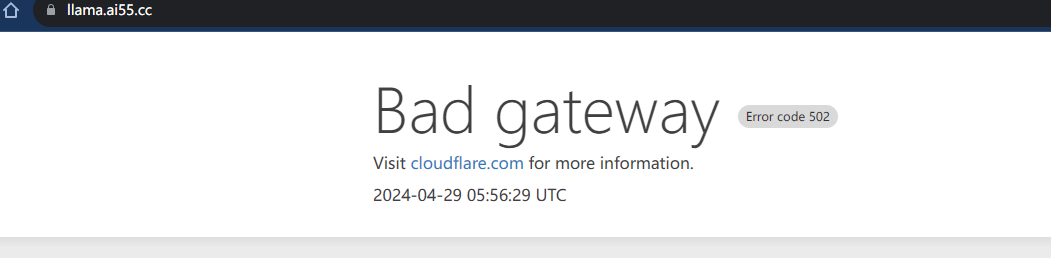
下载一直中断怎么办
1 个赞

感谢分享
1 个赞
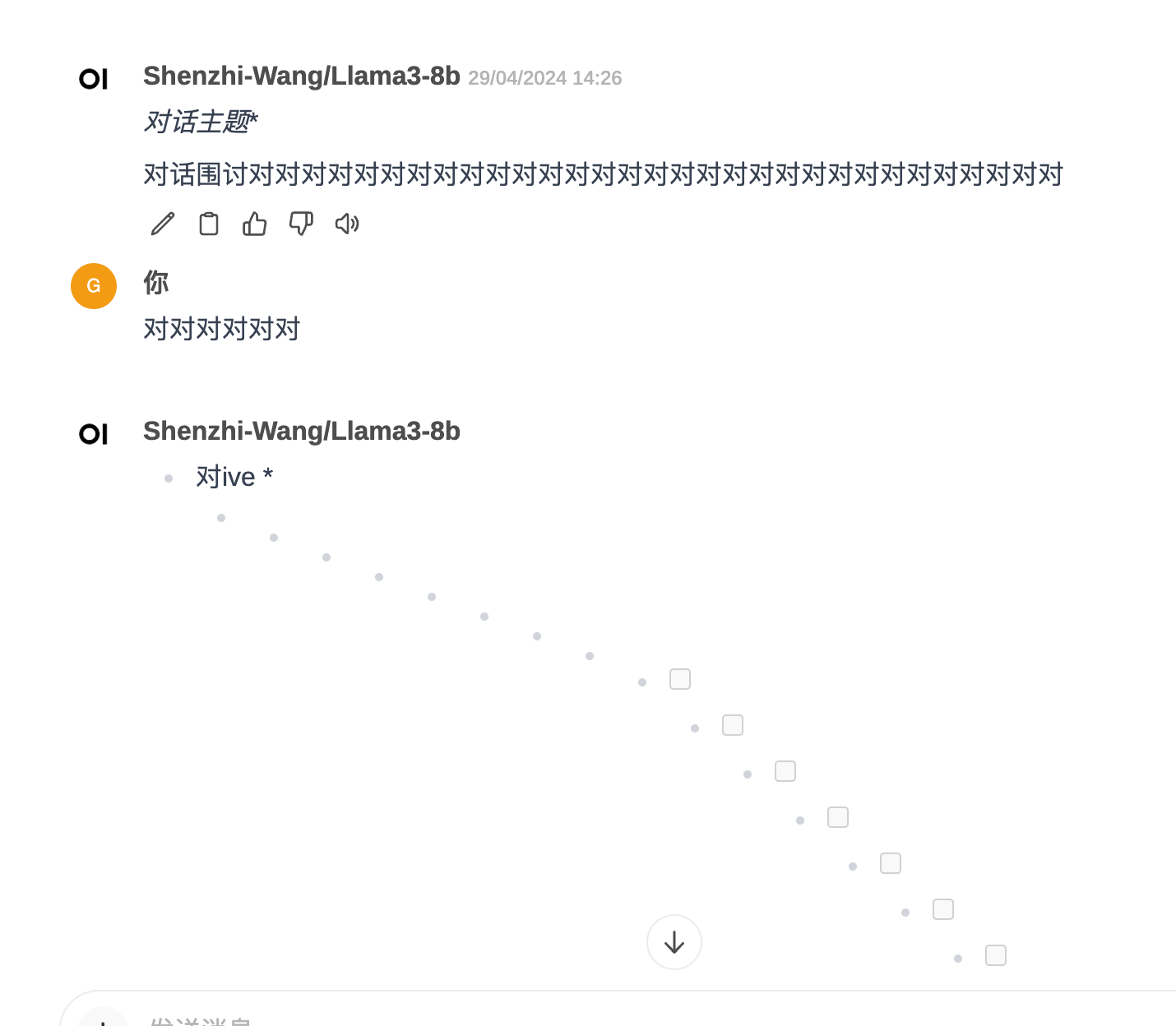
应该是用的人太多,不稳定。早上的时候还很丝滑。
1 个赞