用了很久的一个音乐mp3 下载网站,无网盘中间操作,毛子爱心网站
完全无套路的带你你回到mp3尽情下载的00,10年代
https://hayqbhgr.slider.kz/
未防止迷路,可以使用永久域名关注毛子本人twitter: www.slider.kz
用了很久的一个音乐mp3 下载网站,无网盘中间操作,毛子爱心网站
完全无套路的带你你回到mp3尽情下载的00,10年代
https://hayqbhgr.slider.kz/
未防止迷路,可以使用永久域名关注毛子本人twitter: www.slider.kz
请大家多给点赞,多回复,想升级用户级别
有华语的吗?
直接搜索中文即可
https://hayqbhgr.slider.kz/#周杰伦
直接搜索中文哦,比如刀郎
去瞧瞧,感谢分享
感谢分享
去瞧瞧,标记下
这个站我很早之前就关注了,没想到这里也有佬友推荐。顺便贴一个我自用的爬虫小工具:
import requests
from urllib.parse import quote
import json
import os
from tqdm import tqdm
import socket
def check_proxy():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(1)
proxy_address = ("127.0.0.1", 7890)
try:
sock.connect(proxy_address)
sock.close()
return True
except socket.error:
return False
def search_music(keyword):
payload = {'q': keyword}
encoded_payload = {k: quote(v) for k, v in payload.items()}
url = "https://hayqbhgr.slider.kz/vk_auth.php"
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'DNT': '1',
'Host': 'hayqbhgr.slider.kz',
'Referer': 'https://hayqbhgr.slider.kz/',
'Sec-Ch-Ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
}
use_proxy = check_proxy()
proxies = {"http": "http://127.0.0.1:7890", "https": "http://127.0.0.1:7890"} if use_proxy else None
response = requests.get(url, headers=headers, params=encoded_payload, proxies=proxies)
if response.status_code == 200:
response_list = json.loads(response.text)
if 'audios' in response_list and response_list['audios'].get(''):
response_list = response_list['audios']['']
for index, song in enumerate(response_list):
title = song.get('tit_art', 'Unknown Title')
print(f"Index:{index+1:<4} Title: {title}")
return response_list
else:
return(f"Request failed with status code: {response.status_code}")
return False
def download_music(music_url, music_title, dirs):
use_proxy = check_proxy()
proxies = {"http": "http://127.0.0.1:7890", "https": "http://127.0.0.1:7890"} if use_proxy else None
music_file = requests.get(music_url, stream=True, proxies=proxies)
file_path = f"{dirs}/{music_title}.mp3"
total_size = int(music_file.headers.get('content-length', 0))
with open(file_path, "wb") as file, tqdm(
desc=file_path,
total=total_size,
unit='B',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in music_file.iter_content(chunk_size=1024):
size = file.write(data)
bar.update(size)
if __name__ == "__main__":
search_keyword = input("请输入歌曲搜索关键词(歌手/歌曲名称): ")
music_list = search_music(search_keyword)
print("正在搜索,请等待...")
if(music_list):
choose_music = int(input("请输入歌曲数字: "))
print("正在下载歌曲,请等待...")
dirs = "./downloaded_music"
if not os.path.exists(dirs):
os.makedirs(dirs)
music_url = music_list[choose_music - 1].get('url', 'Unknown URL')
music_title = music_list[choose_music - 1].get('tit_art', 'Unknown Title')
download_music(music_url, music_title, dirs)
print("歌曲下载完成")
else:
print("没有找到歌曲")
下载相对有点慢,效果还可以
毛子的,正常
必须点赞
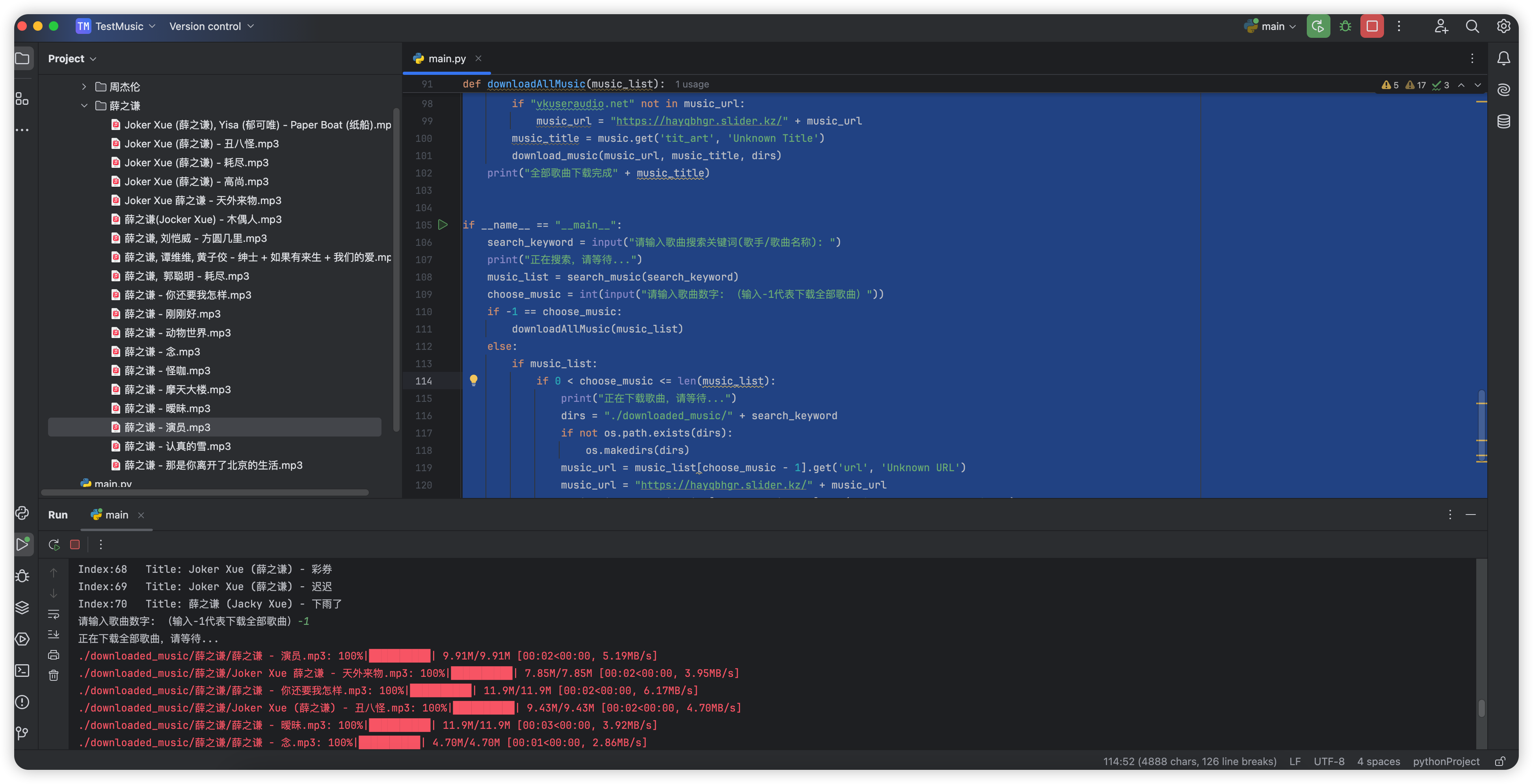
基于马克思大佬的代码,做了一下改良:
import requests
from urllib.parse import quote
import json
import os
from tqdm import tqdm
import socket
def check_proxy():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(1)
proxy_address = ("192.168.0.253", 7890)
try:
sock.connect(proxy_address)
sock.close()
return True
except socket.error:
return False
def search_music(keyword):
payload = {'q': keyword}
encoded_payload = {k: quote(v) for k, v in payload.items()}
url = "https://hayqbhgr.slider.kz/vk_auth.php"
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'DNT': '1',
'Host': 'hayqbhgr.slider.kz',
'Referer': 'https://hayqbhgr.slider.kz/',
'Sec-Ch-Ua': '"Not_A Brand";v="8", "Chromium";v="120", "Microsoft Edge";v="120"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36 Edg/120.0.0.0',
'X-Requested-With': 'XMLHttpRequest',
}
use_proxy = check_proxy()
proxies = {"http": "http://192.168.0.253:7890", "https": "http://192.168.0.253:7890"} if use_proxy else None
try:
response = requests.get(url, headers=headers, params=encoded_payload, proxies=proxies)
response.raise_for_status() # 添加这行来捕捉HTTP错误
response_list = response.json()
if 'audios' in response_list and response_list['audios'].get(''):
response_list = response_list['audios']['']
for index, song in enumerate(response_list):
title = song.get('tit_art', 'Unknown Title')
print(f"Index:{index+1:<4} Title: {title}")
return response_list
else:
print("No audios found in response.")
return False
except requests.exceptions.RequestException as e:
print(f"请求错误: {e}")
return False
def download_music(music_url, music_title, dirs):
# 确保 URL 以 http:// 或 https:// 开头
if not music_url.startswith('http://') and not music_url.startswith('https://'):
music_url = 'http://' + music_url
use_proxy = check_proxy()
proxies = {"http": "http://192.168.0.253:7890", "https": "http://192.168.0.253:7890"} if use_proxy else None
try:
music_file = requests.get(music_url, stream=True, proxies=proxies)
music_file.raise_for_status() # 添加这行来捕捉HTTP错误
except requests.exceptions.RequestException as e:
print(f"下载错误: {e}")
return
file_path = f"{dirs}/{music_title}.mp3"
total_size = int(music_file.headers.get('content-length', 0))
try:
with open(file_path, "wb") as file, tqdm(
desc=file_path,
total=total_size,
unit='B',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in music_file.iter_content(chunk_size=1024):
size = file.write(data)
bar.update(size)
except OSError as e:
print(f"文件操作错误: {e}")
def downloadAllMusic(music_list):
print("正在下载全部歌曲,请等待...")
dirs = "./downloaded_music/" + search_keyword
if not os.path.exists(dirs):
os.makedirs(dirs)
for music in music_list:
music_url = music.get('url', 'Unknown URL')
if "vkuseraudio.net" not in music_url:
music_url = "https://hayqbhgr.slider.kz/" + music_url
music_title = music.get('tit_art', 'Unknown Title')
download_music(music_url, music_title, dirs)
print("全部歌曲下载完成" + music_title)
if __name__ == "__main__":
search_keyword = input("请输入歌曲搜索关键词(歌手/歌曲名称): ")
print("正在搜索,请等待...")
music_list = search_music(search_keyword)
choose_music = int(input("请输入歌曲数字: (输入-1代表下载全部歌曲)"))
if -1 == choose_music:
downloadAllMusic(music_list)
else:
if music_list:
if 0 < choose_music <= len(music_list):
print("正在下载歌曲,请等待...")
dirs = "./downloaded_music/" + search_keyword
if not os.path.exists(dirs):
os.makedirs(dirs)
music_url = music_list[choose_music - 1].get('url', 'Unknown URL')
music_url = "https://hayqbhgr.slider.kz/" + music_url
music_title = music_list[choose_music - 1].get('tit_art', 'Unknown Title')
download_music(music_url, music_title, dirs)
print("歌曲下载完成")
else:
print("无效的选择")
else:
print("没有找到歌曲")
mark,谢谢
你怎么知道我要用它来听刀郎
感谢佬的分享