app.py
# pylint: disable=line-too-long, missing-module-docstring, missing-function-docstring,broad-exception-caught, too-many-statements
import json
import os
import re
import time
from datetime import datetime, timedelta
from textwrap import dedent
import requests
# from bs4 import BeautifulSoup
from flask import Flask, Response, request, stream_with_context
from loguru import logger
from ycecream import y
y.configure(sln=1)
app = Flask(__name__)
APP_SESSION_VALIDITY = timedelta(days=3)
ACCESS_TOKEN_VALIDITY = timedelta(hours=1)
USERNAME = os.environ.get("USERNAME", "")
PASSWORD = os.environ.get("PASSWORD", "")
AUTHKEY = os.environ.get("AUTHKEY", "")
_ = "Set USERNAME and PASSWORD somewhere (e.g., set/export or secrets in hf space, or you wont be able to fetch sfuff from reka.ai"
assert USERNAME and PASSWORD, _
y(USERNAME[:3], PASSWORD[:2], AUTHKEY[:2])
cache = {
"app_session": None,
"app_session_time": None,
"access_token": None,
"access_token_time": None,
}
y(cache)
# 配置日志记录
# logging.basicConfig(level=logging.DEBUG)
def fetch_tokens():
session = requests.Session()
# 检查并获取 appSession
if (
not cache["app_session_time"]
or datetime.now() - cache["app_session_time"] >= APP_SESSION_VALIDITY
):
logger.info("Fetching new appSession")
login_page_response = session.get(
"https://chat.reka.ai/bff/auth/login", allow_redirects=True
)
if login_page_response.status_code != 200:
logger.error("Failed to load login page")
return None
# soup = BeautifulSoup(login_page_response.text, "html.parser")
# state_value = soup.find("input", {"name": "state"})["value"]
state_value = ""
_ = re.search(r"\w{20,}", login_page_response.text)
if _:
state_value = _.group()
session.post(
"https://auth.reka.ai/u/login",
data={
"state": state_value,
"username": USERNAME,
"password": PASSWORD,
"action": "default",
},
)
cache["app_session"] = session.cookies.get("appSession")
cache["app_session_time"] = datetime.now() # type: ignore
# 检查并获取 accessToken
if (
not cache["access_token_time"]
or datetime.now() - cache["access_token_time"] >= ACCESS_TOKEN_VALIDITY
):
logger.info("Fetching new accessToken")
response = session.get(
"https://chat.reka.ai/bff/auth/access_token",
headers={"Cookie": f'appSession={cache["app_session"]}'},
)
if response.status_code != 200:
logger.error("Failed to get access token")
return None
cache["access_token"] = response.json().get("accessToken")
cache["access_token_time"] = datetime.now() # type: ignore
y(cache)
return cache["access_token"]
@app.route("/")
def landing():
return dedent(
"""
query /hf/v1/chat/completions for a spin, e.g. curl -XPOST 127.0.0.1:7860/hf/v1/chat/completions -H "Authorization: Bearer Your_AUTHKEY"
or hf-space-url e.g.,
curl -XPOST https://mikeee-reka.hf.space/hf/v1/chat/completions -H "Authorization: Bearer Your_AUTHKEY" -H "Content-Type: application/json" --data "{\"model\": \"reka-core\", \"messages\": [{\"role\": \"user\", \"content\": \"Say this is a test!\"}]}"
"""
)
@app.route("/hf/v1/chat/completions", methods=["POST", "OPTIONS"])
def chat_completions():
if request.method == "OPTIONS":
return Response(
"",
status=204,
headers={
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "*",
},
)
if (
request.method != "POST"
or request.path != "/hf/v1/chat/completions"
or request.headers.get("Authorization") != f"Bearer {AUTHKEY}"
):
logger.error("Unauthorized access attempt")
return Response("Unauthorized", status=401)
access_token = fetch_tokens()
if not access_token:
logger.error("Failed to obtain access token")
return Response("Failed to obtain access token.", status=500)
try:
request_body = request.json
except Exception as e:
logger.error(f"Error parsing JSON body: {e}")
return Response("Error parsing JSON body", status=400)
messages = request_body.get("messages", []) # type: ignore
model = request_body.get("model", "reka-core") # type: ignore
conversation_history = [
{
"type": "human" if msg["role"] in ["user", "system"] else "model",
"text": msg["content"],
}
for msg in messages
]
if conversation_history and conversation_history[0]["type"] != "human":
conversation_history.insert(0, {"type": "human", "text": ""})
if conversation_history and conversation_history[-1]["type"] != "human":
conversation_history.append({"type": "human", "text": ""})
i = 0
while i < len(conversation_history) - 1:
if conversation_history[i]["type"] == conversation_history[i + 1]["type"]:
conversation_history.insert(
i + 1,
{
"type": "model"
if conversation_history[i]["type"] == "human"
else "human",
"text": "",
},
)
i += 1
new_request_body = {
"conversation_history": conversation_history,
"stream": True,
"use_search_engine": False,
"use_code_interpreter": False,
"model_name": "reka-core",
"random_seed": int(time.time()),
}
response = requests.post(
"https://chat.reka.ai/api/chat",
headers={
"authorization": f"bearer {access_token}",
"content-type": "application/json",
},
data=json.dumps(new_request_body),
stream=True,
timeout=600, # timeout 10 min.
)
if response.status_code != 200:
logger.error(f"Error from external API: {response.status_code} {response.text}")
return Response(response.text, status=response.status_code)
created = int(time.time())
def generate_stream():
decoder = json.JSONDecoder()
encoder = json.JSONEncoder()
content_buffer = ""
full_content = ""
prev_content = ""
last_four_texts = []
for line in response.iter_lines():
if line:
content_buffer += line.decode("utf-8") + "\n"
while "\n" in content_buffer:
newline_index = content_buffer.index("\n")
line = content_buffer[:newline_index]
content_buffer = content_buffer[newline_index + 1 :]
if not line.startswith("data:"):
continue
try:
data = decoder.decode(line[5:])
except json.JSONDecodeError:
continue
last_four_texts.append(data["text"])
if len(last_four_texts) > 4:
last_four_texts.pop(0)
if len(last_four_texts) == 4 and (
len(last_four_texts[3]) < len(last_four_texts[2])
or last_four_texts[3].endswith("<sep")
or last_four_texts[3].endswith("<")
):
break
full_content = data["text"]
new_content = full_content[len(prev_content) :]
prev_content = full_content
formatted_data = {
"id": "chatcmpl-"
+ "".join([str(time.time()), str(hash(new_content))]),
"object": "chat.completion.chunk",
"created": created,
"model": model,
"choices": [
{
"index": 0,
"delta": {"content": new_content},
"finish_reason": None,
}
],
}
yield f"data: {encoder.encode(formatted_data)}\n\n"
done_data = {
"id": "chatcmpl-" + "".join([str(time.time()), str(hash("done"))]),
"object": "chat.completion.chunk",
"created": created,
"model": model,
"choices": [{"index": 0, "delta": {}, "finish_reason": "stop"}],
}
yield f"data: {json.dumps(done_data)}\n\n"
yield "data: [DONE]\n\n"
return Response(
stream_with_context(generate_stream()),
headers={"Content-Type": "text/event-stream"},
)
if __name__ == "__main__":
app.run(host="0.0.0.0", port=7860)
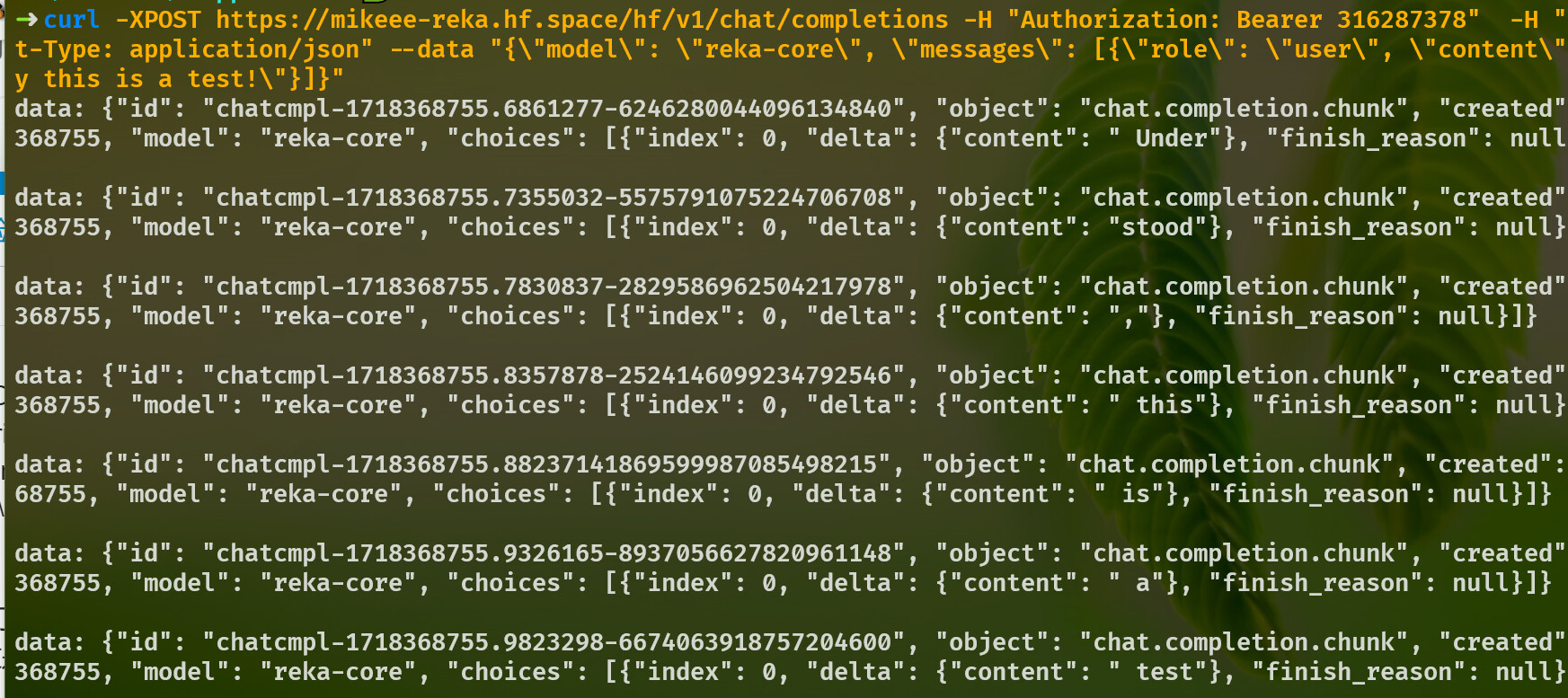
这个薅 reka 的 python 程序(抄某个大佬的)在本地运行没有问题。我把它放到抱抱脸空间 reka - a Hugging Face Space by mikeee 。但
curl -XPOST https://mikeee-reka.hf.space/hf/v1/chat/completions
却连不上,说 Sorry, we can’t find the page you are looking for. 但另一个空间几乎相同的设置访问没有问题:
curl -XPOST https://mikeee-baai-m3.hf.space/embed/
# 输出
# {"detail":[{"type":"missing","loc":["body"],"msg":"Field required","input":null,"url":"https://errors.pydantic.dev/2.6/v/missing"}]}
不知道有没有佬知道是啥原因