前段时间看到 “ShowMeAI研究中心”,整理了一份超级详细的LLM性能价格和评测排行榜的网站清单,再加上最近网上冲浪![]() 看到的新榜单,一并整理分享给大家
看到的新榜单,一并整理分享给大家![]()
![]()
无论是对AI从业者还是爱好者来说,这份清单能帮你快速搞懂当前各大模型的「性价比」和「能力边界」![]()
整理不易,新人发帖,希望能得到大家的点赞和留言,感谢🩷
分两段来给大家介绍,以下是【大模型价格对比】网站合集![]()
(一)大模型价格对比
 Cloud LLM
Cloud LLM 
一份开发者最实用的大模型「性价比」计算手册
- 这是 Harlan Lewis 整理的大语言模型 (LLM) 对比清单,从capability 能力、cost 成本、throughput 吞吐量 三个指标,对国外最新主流大模型进行了打分。
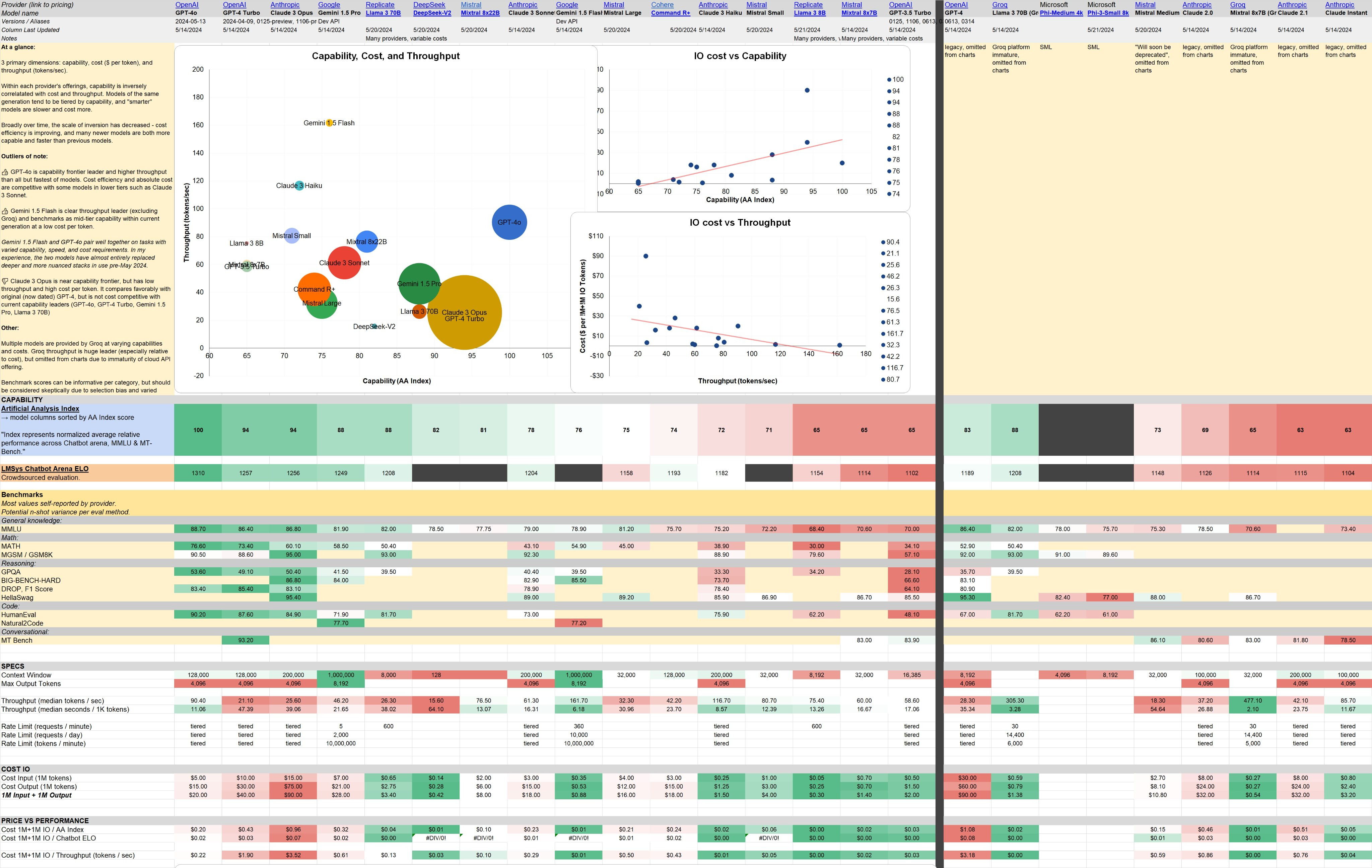
 Artificial Analysis
Artificial Analysis
一份更完备、更客观的 AI大模型购物指南
- Artificial Analysis 是目前看到最完备的大模型性能对比网站啦!
- 不仅基于数据进行了大量分析和可视化,还给出了 质量、价格、性能、速度、上下文窗口等关键指标的 详细排名。

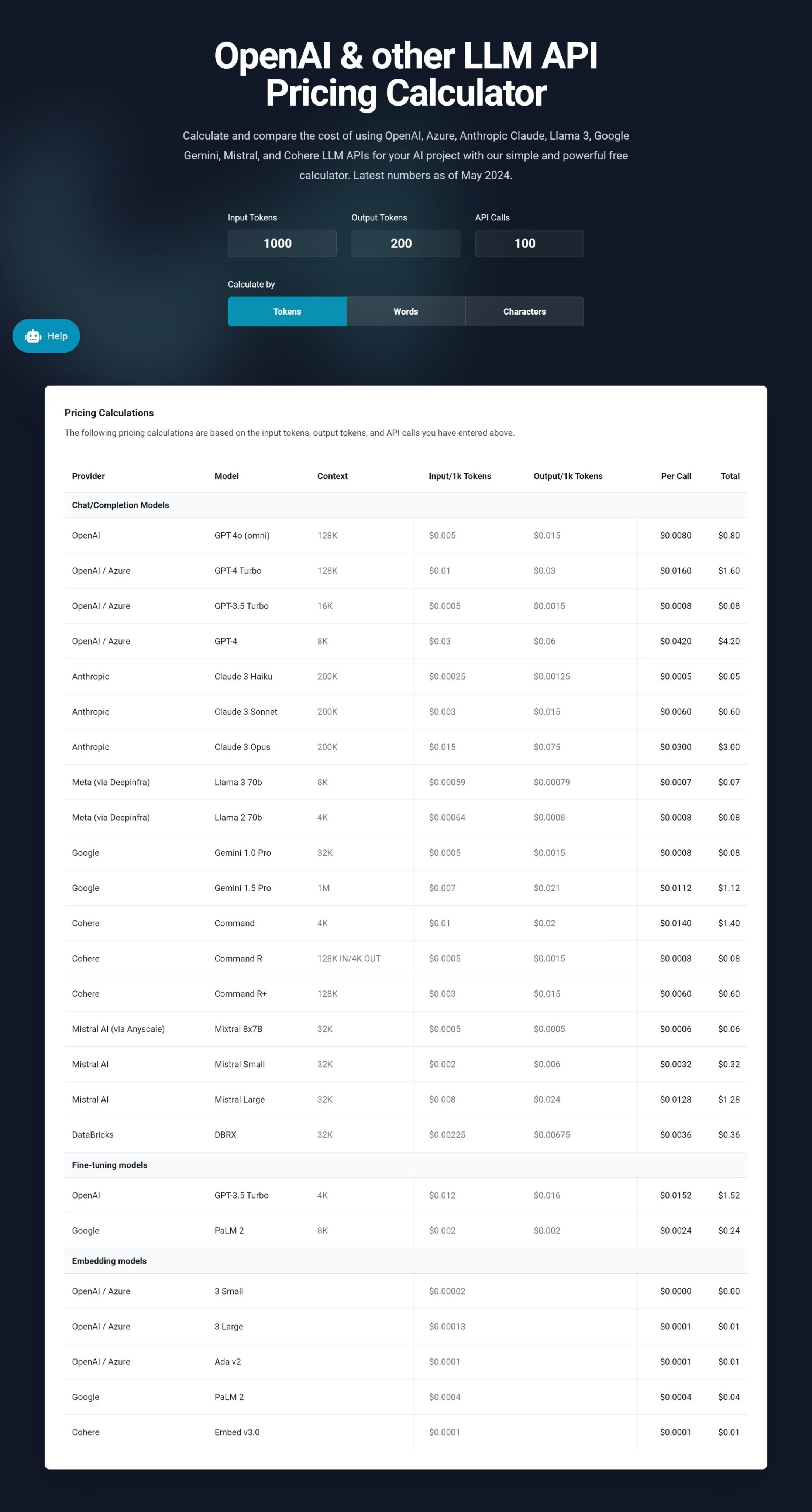
 LLM API Pricing Calculator
LLM API Pricing Calculator
大模型 API 价格计算器,一步到位的价格计算助手
- 这个网站非常有意思!
- 可以手动设定大模型的输入& 输出值,网站下方可以直接显示各个大模型的费用额度。
- 网站还支持 tokens、Words、Characters 这三种不同的计算类型。
 The Fastest AI
The Fastest AI
各大模型 token 生成速度对比网站,三个指标综合测评
- 这是一个专门对比各大模型 token 生成速度的网站,并且非常科学地设定和* 计算了3个指标的得分。而且表单顶部还支持交互筛选。

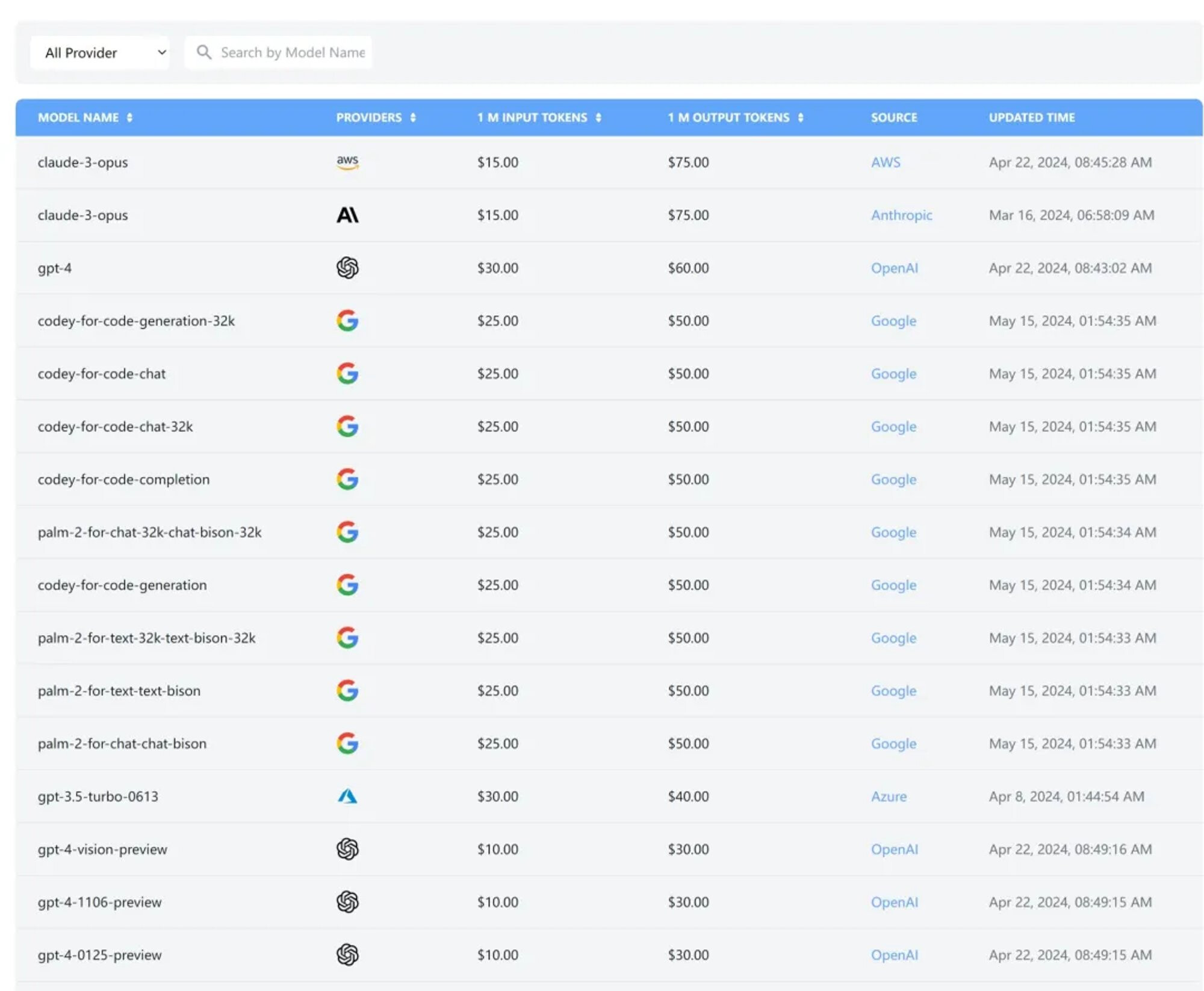
 LLM Pricing
LLM Pricing
包含最多大模型&供应商的比价网站,简明清晰
- LLM Pricing 应该是传播度最广泛的比价网站之一。
- 网站整合了大模型官网、云服务供应商等多种渠道的价格信息,并对输入&输出价格进行了比较。
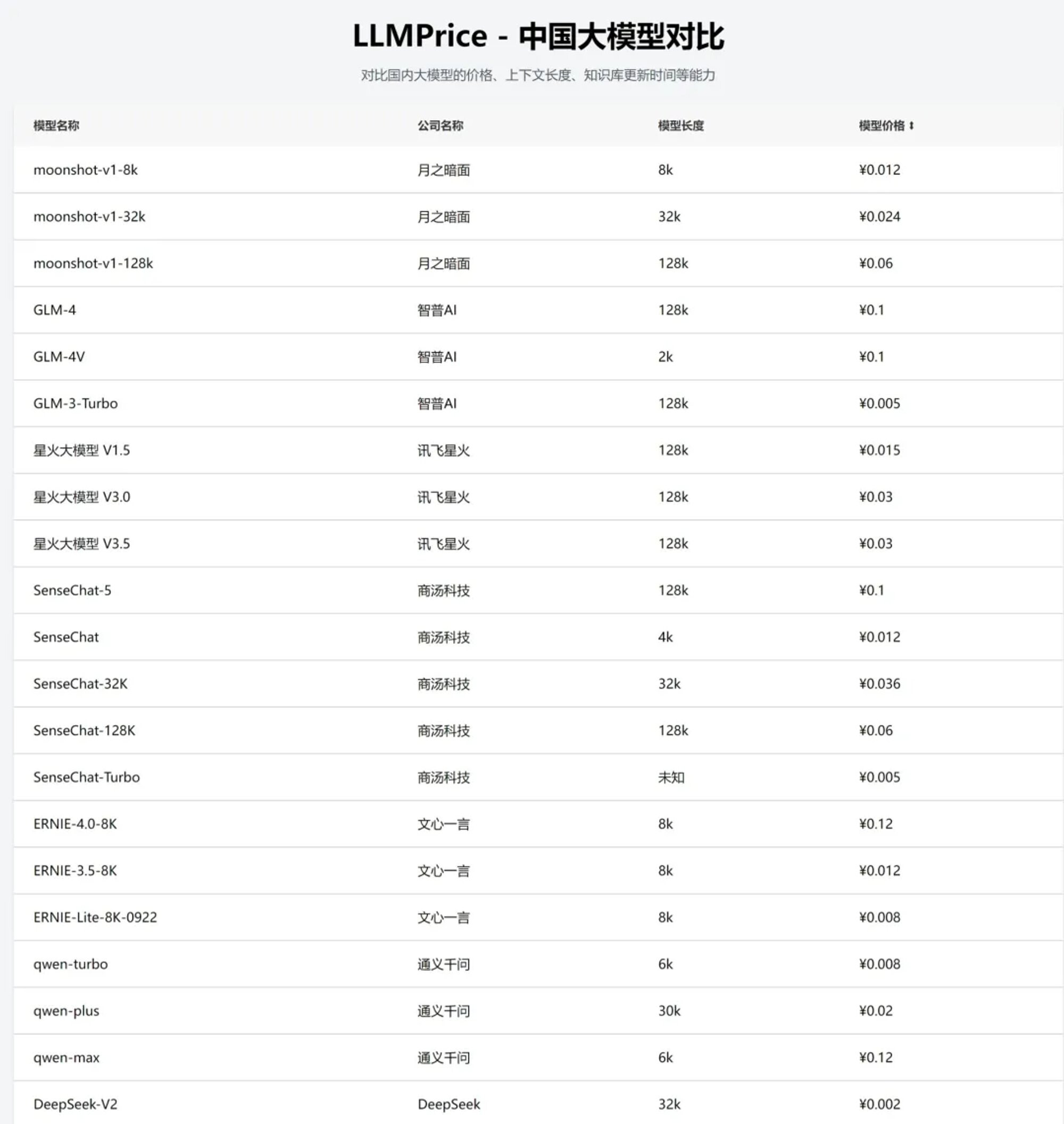
 LLMPrice
LLMPrice
中国大模型对比:对比国内大模型的价格、上下文长度等
- 终于!有一个中国大模型的对比网站了!不过,作者近期更新需要更密集一点了 。

- 国内各家大模型公司都在宣布降价甚至免费,这些还没在网站上体现出来。
接下来给大家罗列【LLM性能测评排行榜】网站![]()
整理的时候发现国内大模型的比较网站还比较少,大家要是有资源也可以留言分享一下。![]()
(二)LLM性能测评排行榜
lifearchitect.ai
应该是最权威、最全面的LLM性能排行榜了
- 网站提供了一个包含超过 300 个大型语言模型(LLM)的详尽列表和性能得分,更新还非常及时。
- 还用一个行星图具象化地表现了大模型参数大小区别,非常直观有趣。
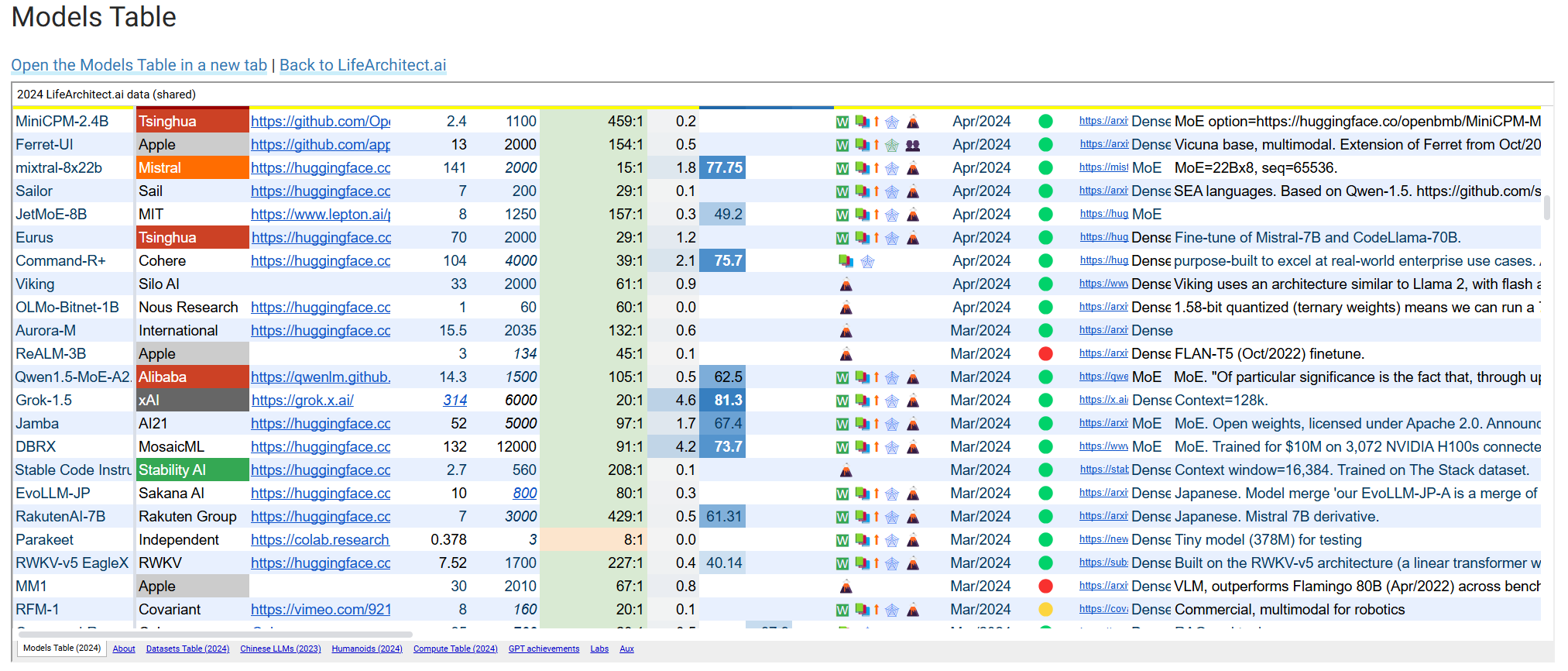

大模型性能报表(飞书文档)
上文第一个排行版的飞书版本,由“FishAI”公众号维护
https://langgptai.feishu.cn/wiki/HteYwsIMpimxO8kFqJ8cylqEnoe?table=blkxAzUVuUw1KjeT
- 飞书中还有个“通用大模型库”的列表和直达链接。
- 大部分数据来自 Models Table – Dr Alan D. Thompson – LifeArchitect.ai 相比原Lifearchitect表格,删除部分字段。
- 新增"模型规模"、“上下文窗口”、“模型规模”、“模型类型、“模型介绍(Gemini 1.5总结的)”、“API价格”等字段。细化发布时间、补充细分模型等。
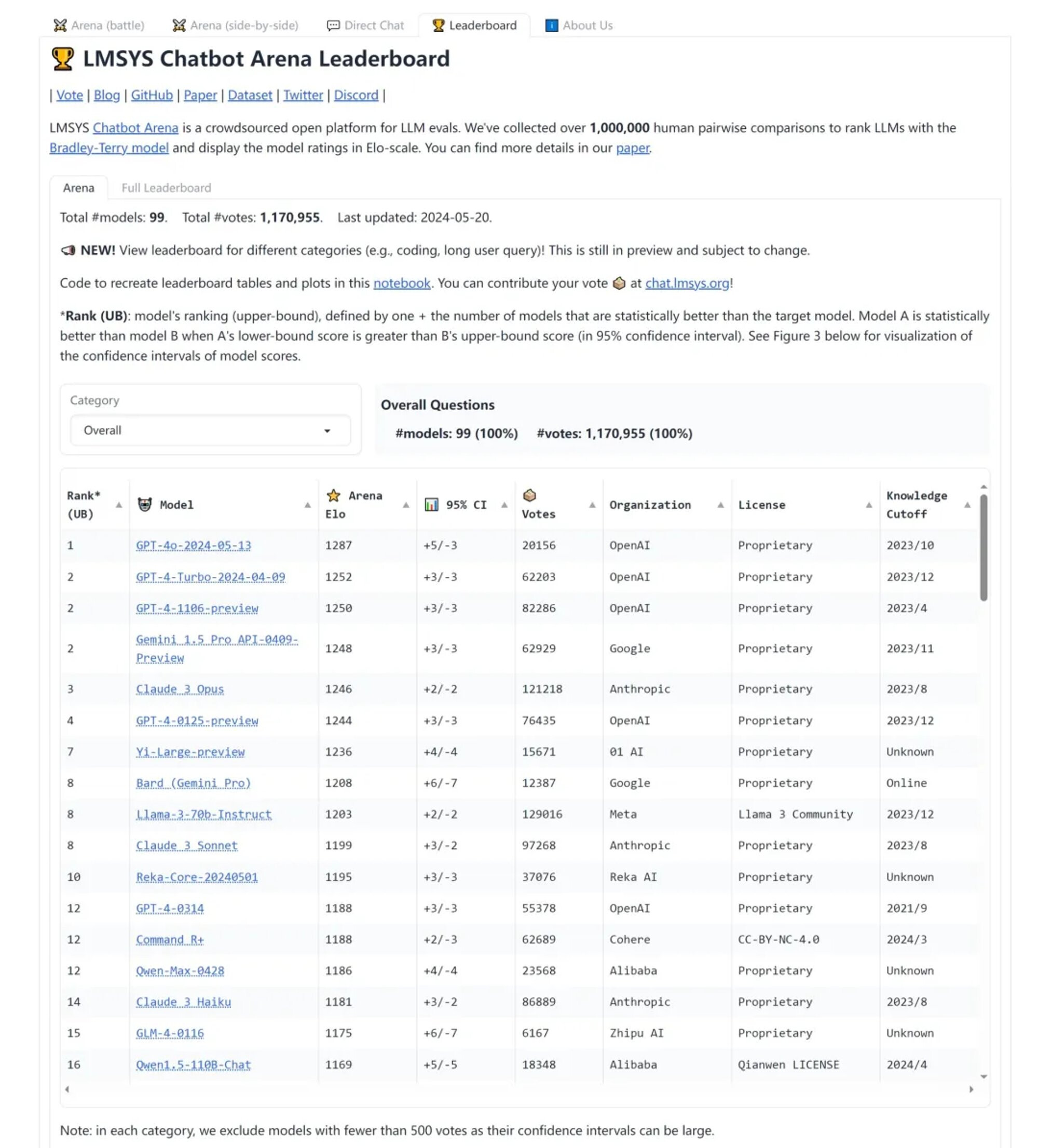
LMSYS Chatbot Arena Leaderboard
全球最知名和权威的盲测大语言模型测评排行榜
https://chat.lmsys.org/?leaderboard
- LMSys Chatbot Arena Leaderboard 是一个由 LM-SYS 组织发布的大语言模型评测排行榜。
- 它采用众包的方式对大模型进行匿名评测。用户根据自己的期望对效果进行投票,最终形成大模型的评测榜单。
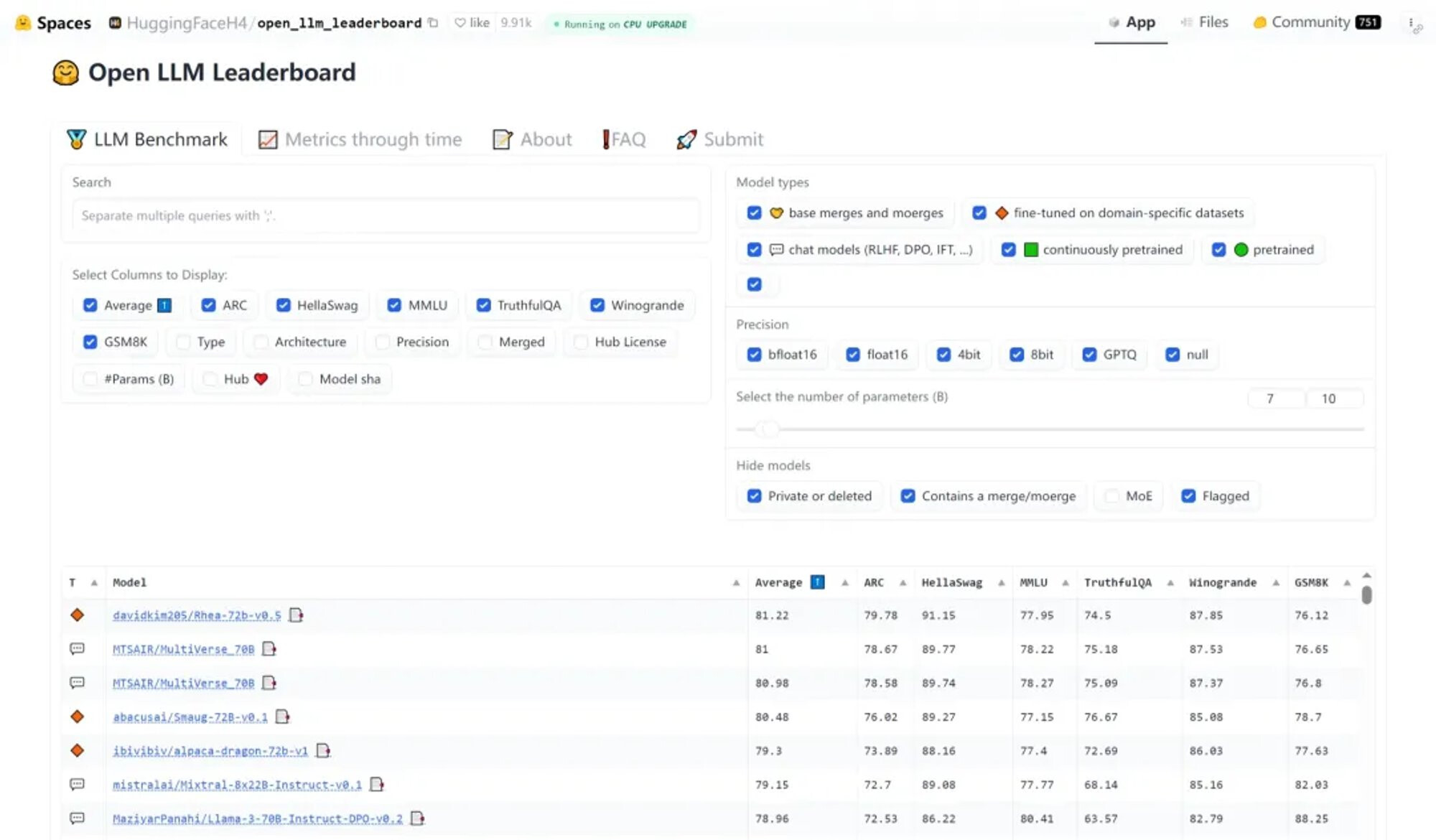
Open LLM Leaderboard
HuggingFace 官方推出的开源 LLM 排行榜
- HuggingFace 官方推出了这份排行榜,帮助评估和展示开源大模型的实际表现。
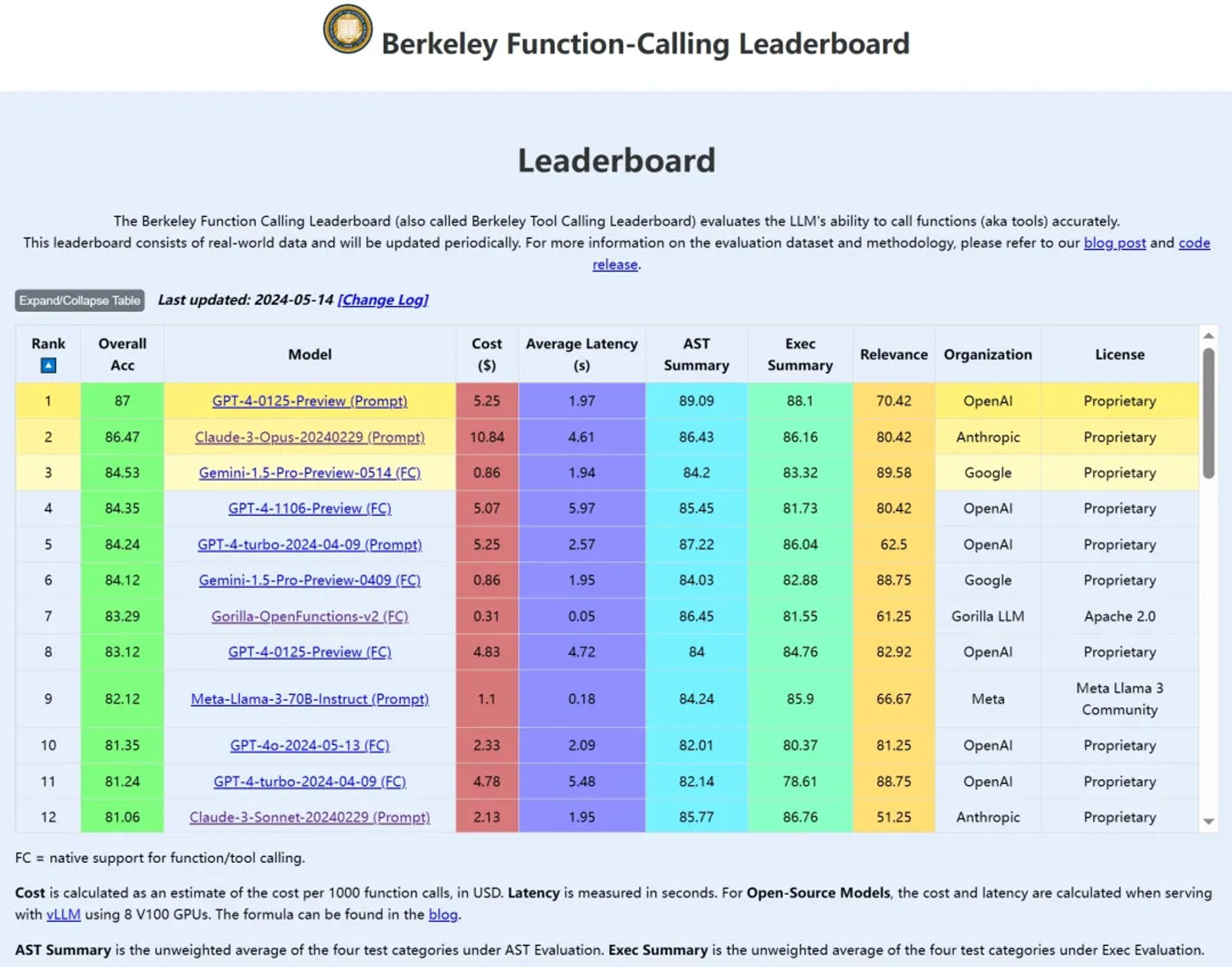
Berkeley Function-Calling Leaderboard
伯克利推出的大模型函数调用能力榜
- Berkeley Function Calling Leaderboard (也被称作 Berkeley Tool Calling Leaderboard) 是伯克利大学发布的一份榜单,用于评估大模型在函数 (工具) 调用方面的表现。
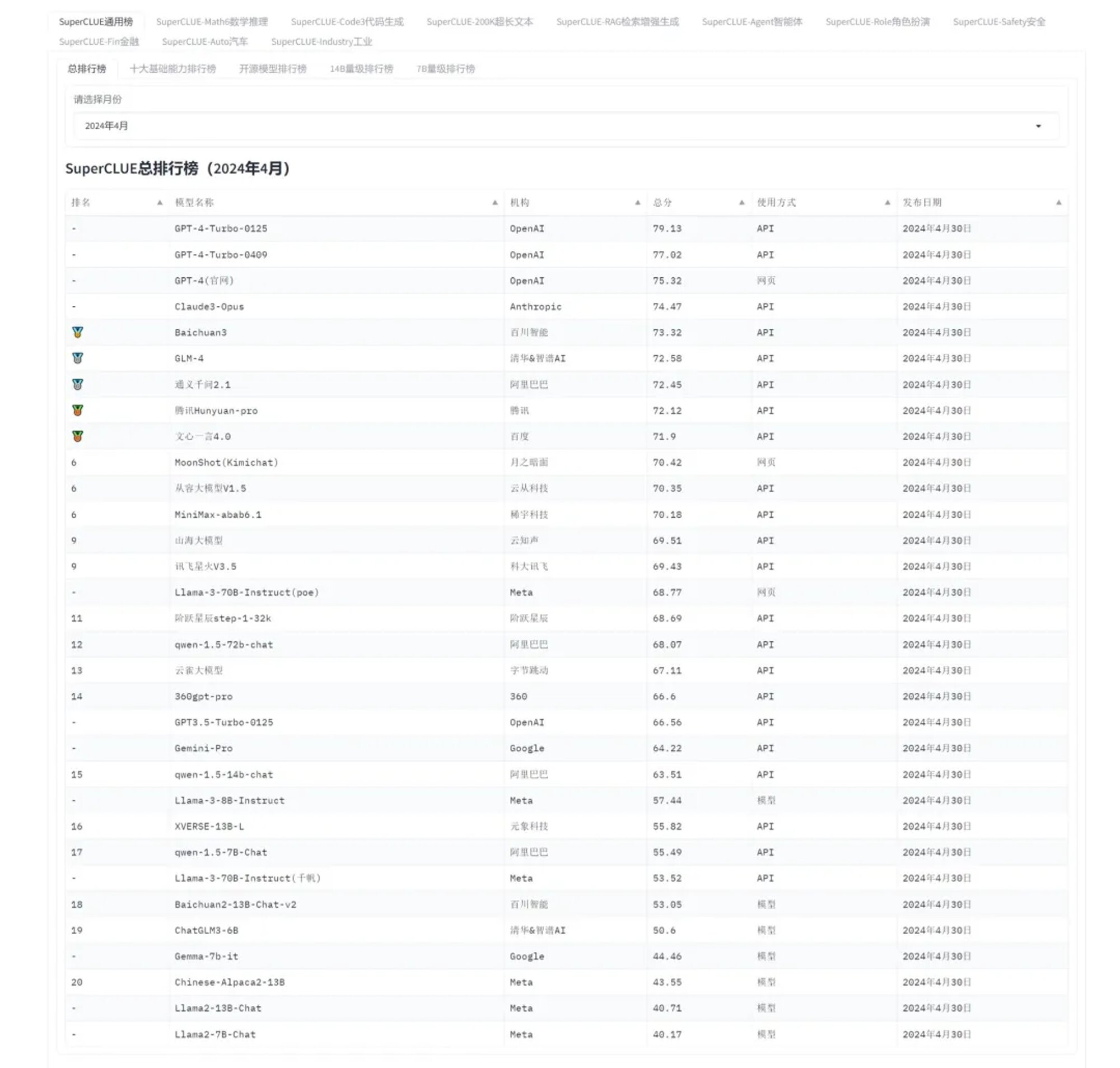
SuperCLUE总排行榜
中文通用大模型综合测评榜,每月持续更新中
- SuperCLUE 是专注于中文通用大模型的综合性测评平台,提供了一系列的测试和评估工具,衡量大模型在不同任务和能力上的表现。
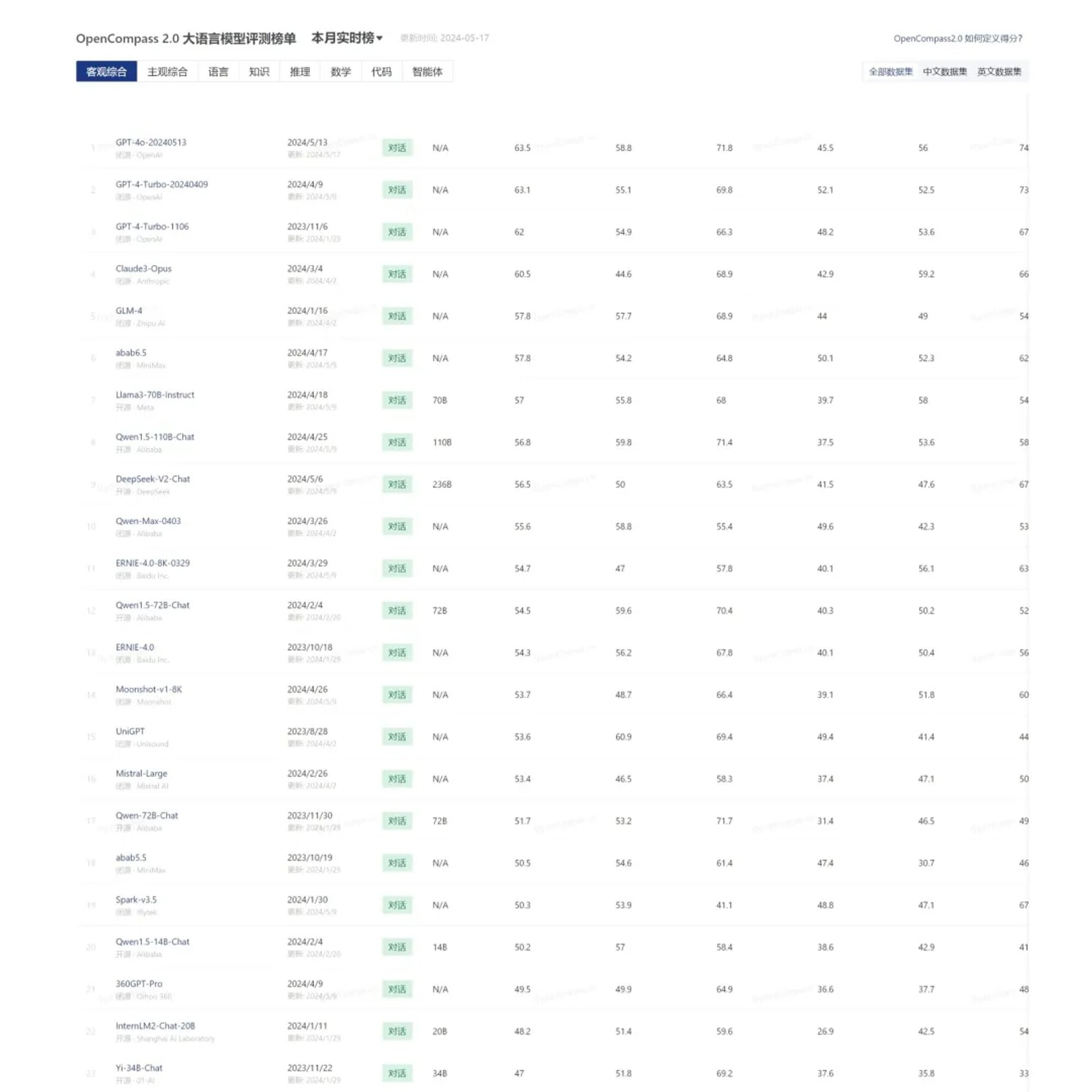
 OpenCompass
OpenCompass
综合测评国内外主流大模型,分成大语言模型 & 多模态模型2份榜单
- OpenCompass 是一个专注于大模型能力评测的平台,包括权威的评测榜单、高质量的评测基准社区和大模型评测全栈工具链。
测评模型有国内也有国外,有开源也有闭源,还覆盖了多个细分领域。
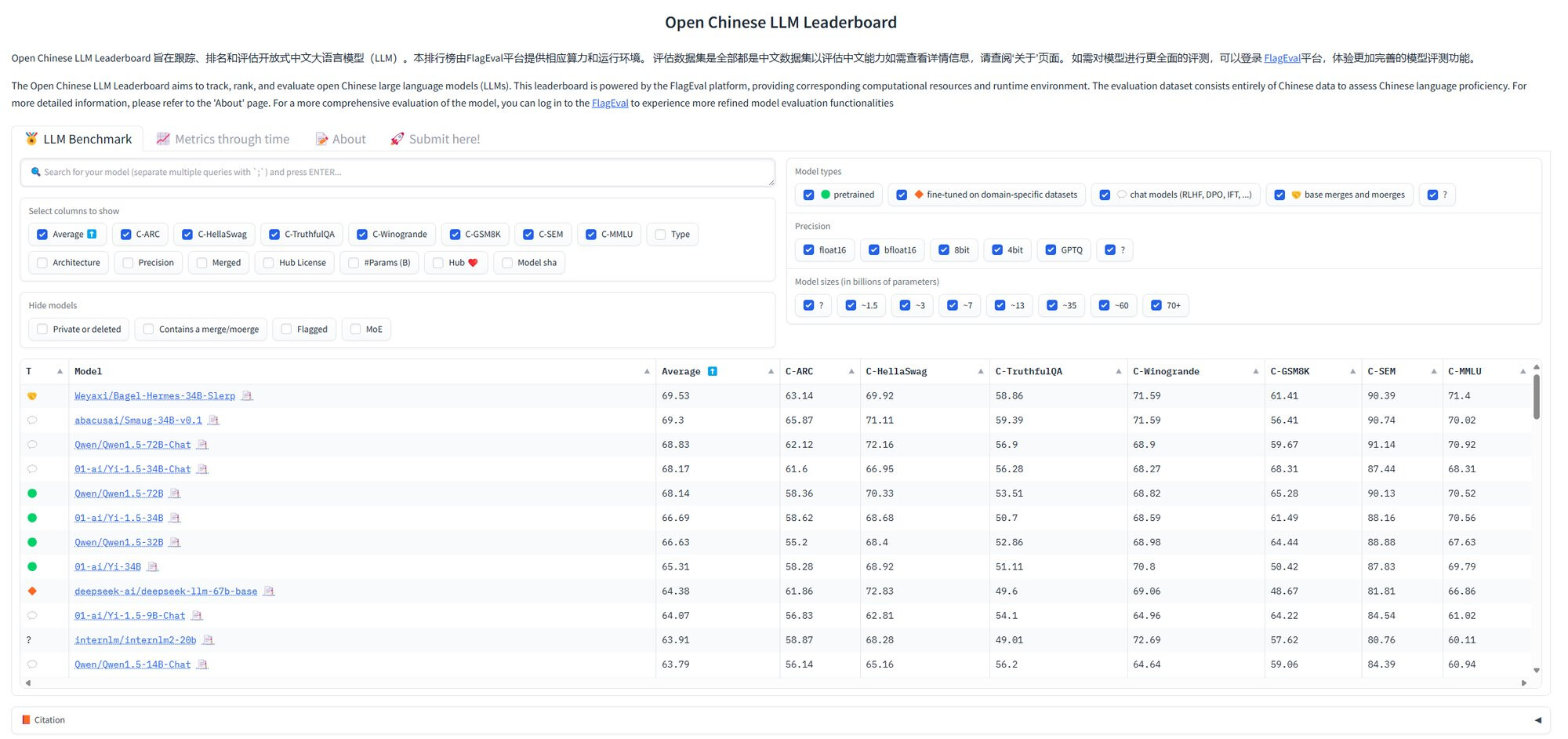
 Open Chinese LLM Leaderboard
Open Chinese LLM Leaderboard
开放中文大语言模型榜单(权威性有待考究)
- 最近更新的中文模型榜单,跟踪、排名和评估开放式中文大语言模型(LLM), 评估数据集是全部都是中文数据集以评估中文能力如需查看详情信息。
![]() 以上
以上