始皇的玩具始皇的新玩具TTS+Whisper糊了个玩具
代码
import PySimpleGUI as sg
import requests
import json
import tempfile
import os
import sounddevice as sd
import numpy as np
import wave
import pygame
import threading
class AudioRecorder:
def __init__(self, sample_rate=44100, channels=1):
self.sample_rate = sample_rate
self.channels = channels
self.recording = False
self.frames = []
def callback(self, indata, frames, time_info, status):
if self.recording:
self.frames.append(indata.copy())
def start(self):
self.recording = True
self.frames = []
self.stream = sd.InputStream(callback=self.callback, channels=self.channels, samplerate=self.sample_rate)
self.stream.start()
def stop(self):
self.recording = False
self.stream.stop()
self.stream.close()
return np.concatenate(self.frames, axis=0)
def text_to_speech(text, voice, auth_token):
url = "https://api.oaifree.com/v1/audio/speech"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {auth_token}"
}
data = {
"model": "tts-1-hd",
"input": text,
"voice": voice,
"response_format": "mp3",
"speed": 1
}
try:
response = requests.post(url, headers=headers, data=json.dumps(data))
response.raise_for_status()
with tempfile.NamedTemporaryFile(delete=False, suffix='.mp3') as temp_file:
temp_file.write(response.content)
temp_file_path = temp_file.name
pygame.mixer.init()
pygame.mixer.music.load(temp_file_path)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10)
pygame.mixer.quit()
os.unlink(temp_file_path)
except Exception as e:
print(f"语音转换错误: {e}")
def speech_to_text(audio_file_path, auth_token):
url = "https://api.oaifree.com/v1/audio/transcriptions"
headers = {
"Authorization": f"Bearer {auth_token}"
}
files = {
"file": open(audio_file_path, "rb"),
"model": (None, "whisper-1")
}
try:
response = requests.post(url, headers=headers, files=files)
response.raise_for_status()
return response.json()["text"]
except requests.exceptions.RequestException as e:
print(f"语音转文字错误: {e}")
return None
def chat_with_ai(messages, auth_token):
url = "https://api.oaifree.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
data = {
"messages": messages,
"stream": False,
"model": "gpt-4o",
"temperature": 0.5,
"max_tokens": 8000,
"top_p": 1
}
try:
response = requests.post(url, headers=headers, data=json.dumps(data))
response.raise_for_status()
response_data = response.json()
if 'choices' in response_data and len(response_data['choices']) > 0:
if 'message' in response_data['choices'][0] and 'content' in response_data['choices'][0]['message']:
return response_data['choices'][0]['message']['content']
else:
print("意外的响应结构:")
print(json.dumps(response_data, indent=2))
return None
else:
print("未找到有效的响应内容:")
print(json.dumps(response_data, indent=2))
return None
except requests.exceptions.RequestException as e:
print(f"AI 对话错误: {e}")
return None
def main():
recorder = AudioRecorder()
messages = [] # 用于存储对话历史
voices = ["alloy", "echo", "fable", "onyx", "nova", "shimmer"]
layout = [
[sg.Text("语音助手", justification='center', font=('Any', 20))],
[sg.Text("AUTH_TOKEN:"), sg.Input(key="-AUTH-", password_char='*')],
[sg.Text("状态: 准备就绪", key="-STATUS-", justification='center')],
[sg.Text("选择语音模型:"), sg.Combo(voices, default_value="echo", key="-VOICE-")],
[sg.Button("开始录音", key="-RECORD-"), sg.Button("停止录音", key="-STOP-", disabled=True)],
[sg.Text("您的问题:", justification='left')],
[sg.Multiline(size=(50, 5), key="-USER-INPUT-", disabled=True)],
[sg.Text("AI 回答:", justification='left')],
[sg.Multiline(size=(50, 10), key="-AI-RESPONSE-", disabled=True)],
[sg.Button("清除对话历史", key="-CLEAR-")]
]
window = sg.Window("语音助手", layout, finalize=True, element_justification='center')
recording = False
while True:
event, values = window.read(timeout=100)
if event == sg.WINDOW_CLOSED:
break
if event == "-RECORD-" and not recording:
recording = True
window["-STATUS-"].update("正在录音...")
window["-RECORD-"].update(disabled=True)
window["-STOP-"].update(disabled=False)
recorder.start()
elif event == "-STOP-" and recording:
recording = False
window["-STATUS-"].update("正在处理...")
window["-RECORD-"].update(disabled=True)
window["-STOP-"].update(disabled=True)
audio_data = recorder.stop()
with tempfile.NamedTemporaryFile(delete=False, suffix='.wav') as temp_file:
temp_file_path = temp_file.name
with wave.open(temp_file_path, 'wb') as wf:
wf.setnchannels(recorder.channels)
wf.setsampwidth(2)
wf.setframerate(recorder.sample_rate)
wf.writeframes((audio_data * 32767).astype(np.int16).tobytes())
auth_token = values["-AUTH-"]
user_input = speech_to_text(temp_file_path, auth_token)
os.unlink(temp_file_path)
if user_input:
window["-USER-INPUT-"].update(user_input)
messages.append({"role": "user", "content": user_input})
window["-STATUS-"].update("AI 正在思考...")
ai_response = chat_with_ai(messages, auth_token)
if ai_response:
messages.append({"role": "assistant", "content": ai_response})
window["-AI-RESPONSE-"].update(ai_response)
window["-STATUS-"].update("AI 正在说话...")
selected_voice = values["-VOICE-"]
threading.Thread(target=text_to_speech, args=(ai_response, selected_voice, auth_token)).start()
else:
window["-STATUS-"].update("未能理解。请重试。")
window["-RECORD-"].update(disabled=False)
window["-STOP-"].update(disabled=True)
elif event == "-CLEAR-":
messages.clear()
window["-USER-INPUT-"].update("")
window["-AI-RESPONSE-"].update("")
window["-STATUS-"].update("对话历史已清除")
if not pygame.mixer.get_busy():
window["-STATUS-"].update("准备就绪")
window.close()
if __name__ == "__main__":
main()
可以直接使用已打包的exe
[123云盘下载地址](https://www.123pan.com/s/pTVtjv-DyQWd.html)旧版已失效
填入Acces token就可以愉快的玩耍了
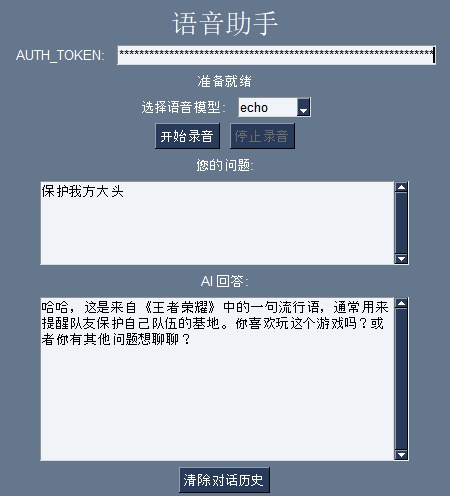
当然,需要plus账户哈
各位佬友好像都觉得这个UI真的似乎不是很友好(确实不好 ![]() )
)
加个夜班赶一下交互感
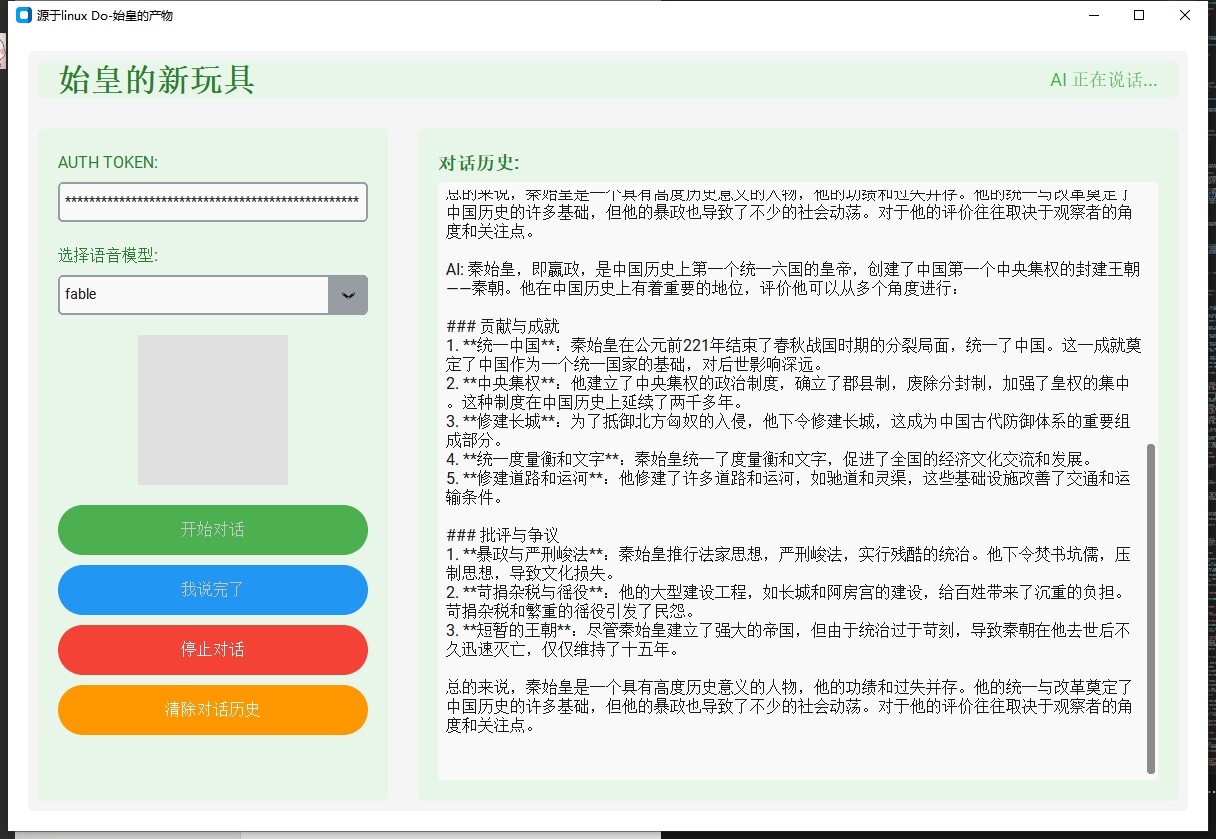
附上下载链接和代码链接
代码包:https://www.123pan.com/s/pTVtjv-ZyQWd.html
成品包:https://www.123pan.com/s/pTVtjv-cyQWd.html