先上图:

看看我们家的Q_S3.5怎么说

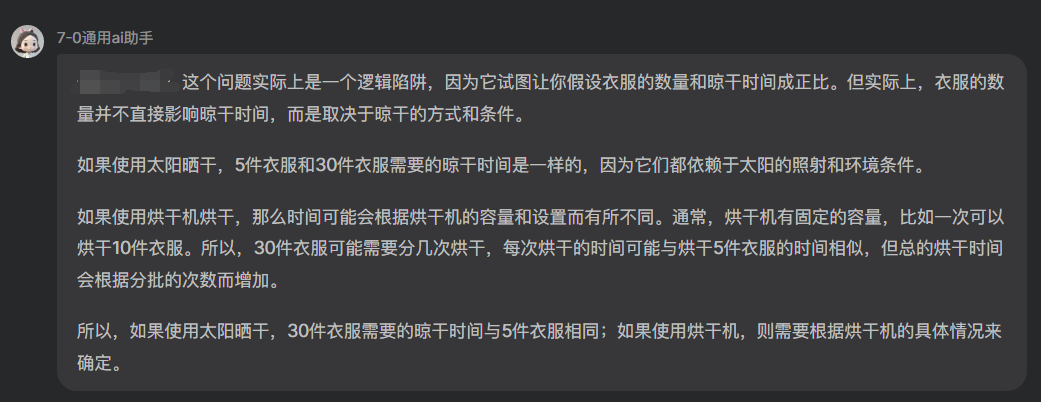
所以看起来3.5真的没有想象中那么差 他只是提示词太冗杂了 而又确实无法达到想要的效果 但的确可以把问题看得更透彻
他的确可以通过分析找出其他模型没有发现的细微差别 比如词的转换
先上图:
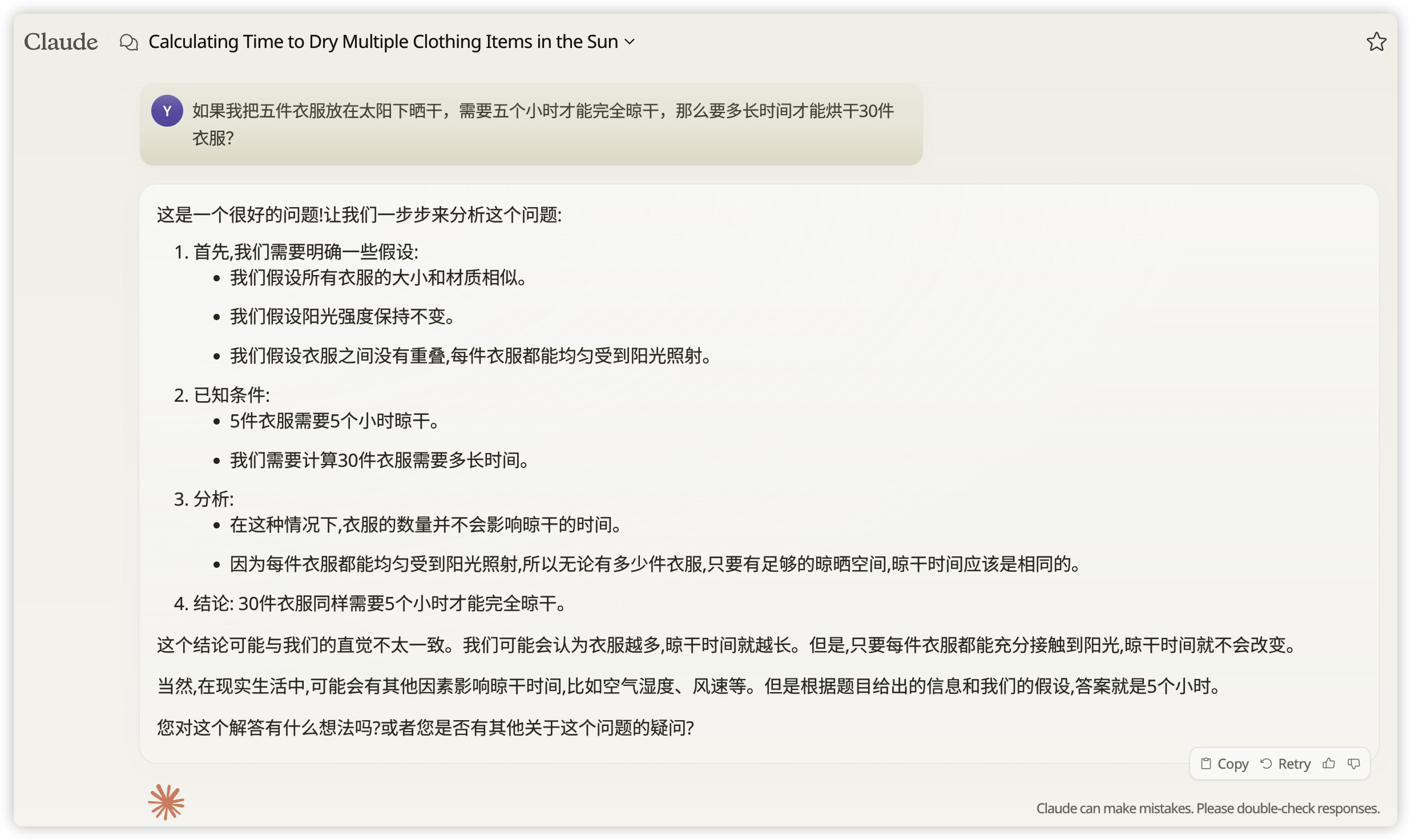
所以看起来3.5真的没有想象中那么差 他只是提示词太冗杂了 而又确实无法达到想要的效果 但的确可以把问题看得更透彻
他的确可以通过分析找出其他模型没有发现的细微差别 比如词的转换
我们可以明确的发现题目中一共提到了三个动作 晾干 晒干以及烘干 这三者都是存在细微差别的
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
你是不是不上班?
不上
太强了吧
可恶![]()
不要为财所困
太阳底下晒干不能叫做“烘干”
深度求索最终没有给出可能的时间呢 大致的估计对于用户把握是很重要的
是吗
9.11和9.8谁大 好多模型都回答不准确
Cot对的概率是50% 前面对后面错 或者前面错 后面对
新的提问方法是将数字用汉字表示出来 九点一一和九点九哪个大
混元大模型可以答对
From #develop:ai to 资源荟萃