什么是ComfyUI
ComfyUI是一个基于节点流程式的stable diffusion AI绘图工具,具有强大的功能和高度模块化特点。它提供了一个图形用户界面,允许用户通过构建节点流程来创建和控制AI生成的图像。ComfyUI的特色在于其可配置性强,用户可以通过调整各种参数和节点来精细控制生成图像的过程。此外,ComfyUI还支持插件和模型的管理,用户可以在其平台上下载和安装所需的插件和模型,进一步扩展工具的功能。总的来说,ComfyUI是一个为AI图像生成提供全面解决方案的软件,特别适合对图像生成有高级需求的用户。
ComfyUl则是使用图形/节点/流程图设计而用于 SD 的用户界面,做为 Stable Diffusion 的载体,为了让不懂代码没有电脑基础的我们能够更加便捷的使用SD而创造出来的。
什么是模型
stablediffusion生成图片的画风之所以不同,和我们训练模型时的图片有很大关系;例如我们拿一万张风景照片去训练模型,就很难要求sd帮我生成出动漫风格的图片。
因此在生成图片时,选择不同的模型可以理解为选择不同的画师,来"绘制"不同风格的图片。模型有很多种,其中主要影响风格的就是大模型(checkpoints)其次是小模型(lora)以及用来调整生成色调的VAE模型。
其中我们最常用的就是lora和大模型。
SDXL是什么
SDX简单来说就是stable diffusion的官方 StabilityAI 新推出的一个全能型大模型。在此之前也有SD1.5、SD2.1这样的官方大模型(但是基本没人用,因为效果很差)。我们平时经常使用的模型都是以官方大模型作为底模训练出来的微调模型。目前市面上常见的模型都是基于官方的SD1.5作为底模训练出来的。
什么是CheckPoint
在深度学习和机器学习领域,通常指的是在训练过程中定期保存的模型参数快照。这些快照可以用于恢复训练过程、继续训练模型,或者用于测试/部署模型。
说人话就是:CheckPoint就是底模,它是别人训练,或者融合好的大型模型,里面集合了这个模型的参数、权重等。一般模型体积较大,单个模型的大小一般在GB量级。这是使用StableDiffusion模型进行绘画的基础。
所以,当你选择了某个 大模型 ,你的 SD 出图风格、画风也就基本确定了
使用SD进行绘画,必须要用到Checkpoint和VAE模型,不过部分模型已经融合了VAE模型,所以通常不需要下载配置VAE模型
什么是VAE模型
VAE(全称为Variational Autoencoder(变分自编码器))模型通常有两种作用
第一种是滤镜:可以理解为 项 PS、抖音、美图秀秀用到的滤镜一样,让画面看上去不是灰蒙蒙的,让整体的色彩饱和度更高。
第二种是微调:部分VAE会对出图的细节进行微调
下边使用网图来增强理解:


可以看到,在相同的提示词下,通过VAE模型的调整,画风发生了很大的变化。添加VAE模型之后,画面颜色饱和度更高了,色彩更艳丽。
什么是LoRa模型
LoRa(Low-Rank Adaptation of Large Language Models)是一种用于微调大型语言模型的低秩适应技术。
通过前文可知,CheckPoint模型是整个绘画的基础,决定后续绘画内容基调和整体绘画风格。但是训练和修改底模需要大量的数据,较长的训练时间。那么是否有办法不通过训练底模,只是局部修改模型,就能输出我想要的结果。比如说,我希望生成的人物长相接近某个人,只需要微调面部输出就可以。这是时候,LoRa模型就登场了。LoRA模型一般体积不是很大,几十兆到一两百兆,主要用于处理大模型微调的问题。
再次借用网图加深理解
左栏是使用底模进行的输出结果
右栏是使用了某知名明星刘姐姐的 LoRA 模型之后的输出
可以发现,我们只需要引入LoRA模型,并设置该模型的权重,就可以改变整体的人物的面部输出的画风



什么是ControlNet模型
在说ControlNet模型之前,需要理解它的需求背景,在没有ControlNet模型前,输出结果的不稳定。比如下边的示例,我们在使用 sd_xl_base_1.0.safetensors和 提示词 4girl来生成图片,会看到每次生成出来图片都有很大的差异,无法进行稳定的控制。如果模型只能随机这样生成不稳定的结果,那么就无法进行商用。





ControlNet模型的主要作用,就是一种通过添加额外的模型,来控制大模型的某些方面的结果,ControlNet提供了一种增强稳定输出方法,使得SD的输出能够更可控和预测,这让StableDiffusion落地应用起到了重要的作用。其中,比如可以做出指定动作的姿势,下面四个女生的背影图曾经火爆一时,就是因为ControlNet模型的出现,解决了稳定控制这个问题。

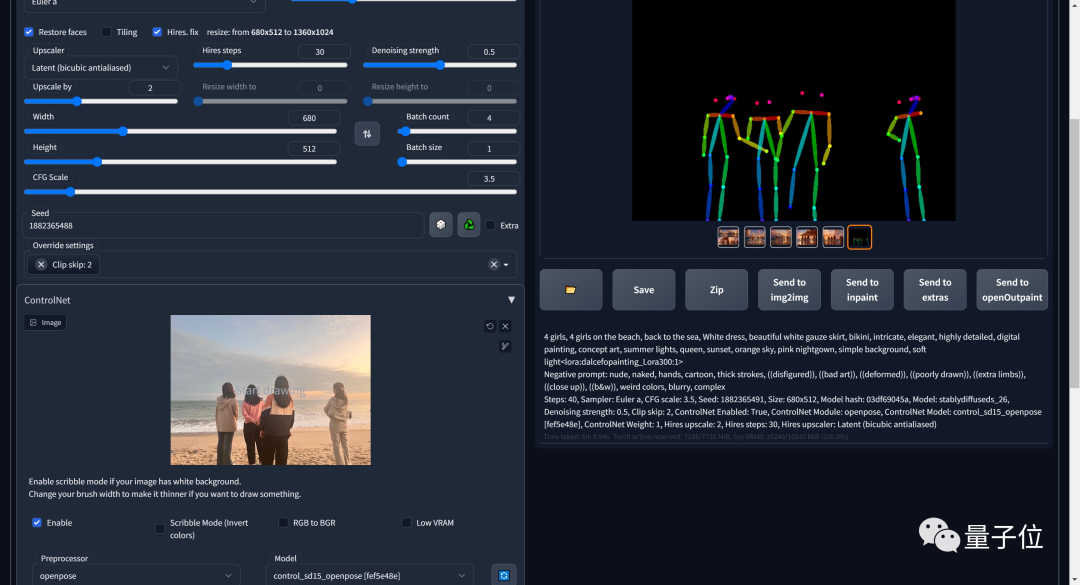


上面只是ControlNet的简单应用之一,还有更多生成线稿图、线稿图上色(下图)、卡通变真人的各种功能。


ControlNet的原理,本质上是给预训练扩散模型增加一个额外的输入,控制它生成的细节。
这里可以是各种类型的输入,作者给出来的有8种,包括草图、边缘图像、语义分割图像、人体关键点特征、霍夫变换检测直线、深度图、人体骨骼等。
什么是Embedding模型
Embedding,又名textual inversion,中文名嵌入or文本反转(又不说人话)。给出一个通俗易懂的定义:Embedding是提示词打包。
举个例子,假如你使用原版的 SD,不使用其他任何插件的情况下,如何生成守望先锋角色–DVA

我们在原版的模型上生成猎空这个角色,实际上需要非常非常长的限定词,才能稳定生成出这个角色
masterpiece, high-quality, 1girl,clothes with Pink pattern,(brown hair), pink
earphones, green pattern on the earphones, blue tights, whitte gloves, ((pink
(pattern on the clothes)), cat pattern on the face, detailed eyes,(pink theme), rabbit
decoration on the chest, green word pattern, sewing line onthe clothes, long hair,
thin girl, delicate face, beautiful face, melon face, skin fuIl of details, pink
background, white gloves, thin neck, Sexy figure, (browneyes:1.2), smile, wearing
whiteshoes,green patterns,blushing,.....以下省略五十行,几千个tag
在引入 Embedding之后,我们将这些tag进行打包,用一个 特殊的触发词 corneo_dva来指向这些tag。当我们在进行实际的图片生成的时候,只需要引入这个词,就相当于 引入了这个角色的所有tag。
可以参考一些 已经很成熟的dva模型 (d.va (overwatch) d.va 守望先锋)



Embedding模型的空间占用非常小,他的内部只是一些列的tag。

什么是HypernetWork模型
Hypernetwork中文翻译为超文本网络模型,是一种用于改善生成图像整体风格的模型,类似于LoRa、embedding模型,都是对Stable Diffusion生成的图片进行针对性地调整。HypernetWork模型可以通过学习已知的图像集合,用于影响影响大模型的绘画的风格,生成新一种新风格的图像。这种模型可以被看作是一个风格生成器,它可以接收一些风格模型为输入,并输出一张新风格的图像。
hypernetwork最重要也是实现最好的功能是对画面风格的转换,也就是切换不同的画风。
参考一些hypernetwork模型
左栏的像素风格HypernetWork模型 右栏的法国画家亨利·卢梭的画风模型


Hypernetwork使用效果并不理想甚至还不如体积只有几k的embeddings文件,但是Hypernetwork的文件体积却可以与lora相提并论,在几十M甚至上百M。hypernetwork的应用领域较窄,主要是训练画风,训练难度很大,未来很有可能被后出现的lora所替代,新手可以将hypernetwork理解为低配版的lora。
什么是Upscale模型
Upscale模型主要用于将低分辨率图像放大到高分辨率,同时尽可能保持图像的质量和细节。这些模型在图像处理和生成领域中非常关键,尤其是在需要增加图像清晰度和细节的应用中。
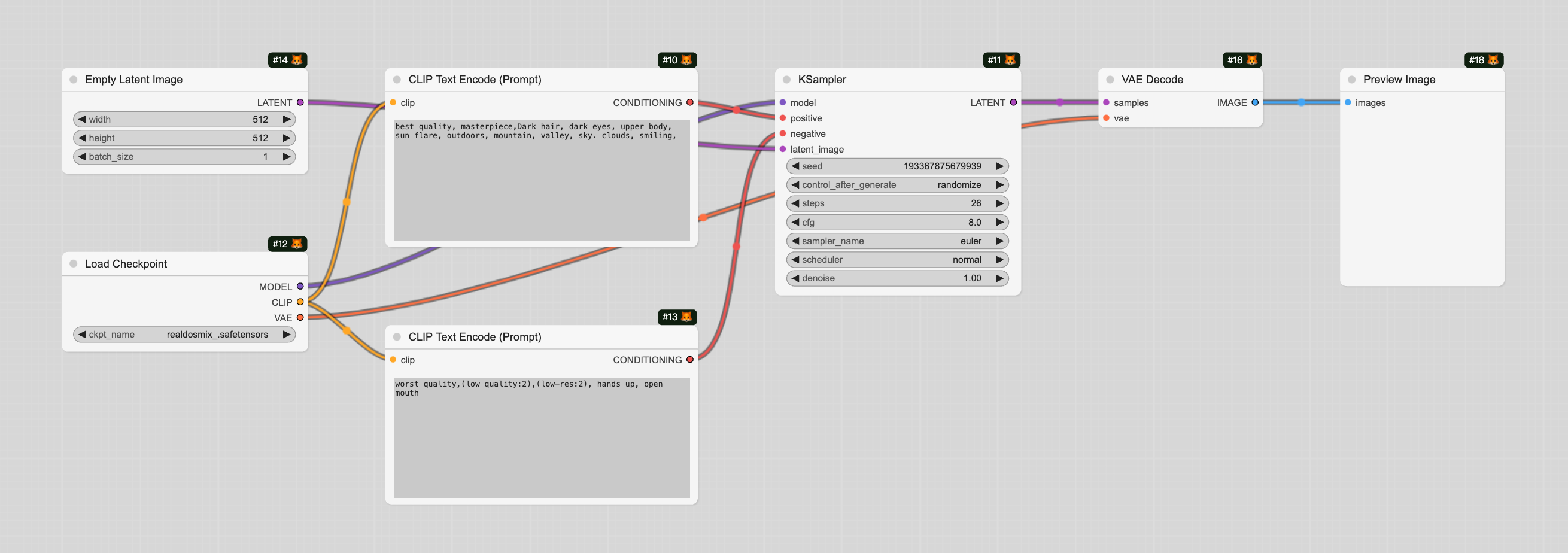
ComfyUI有哪些常用节点
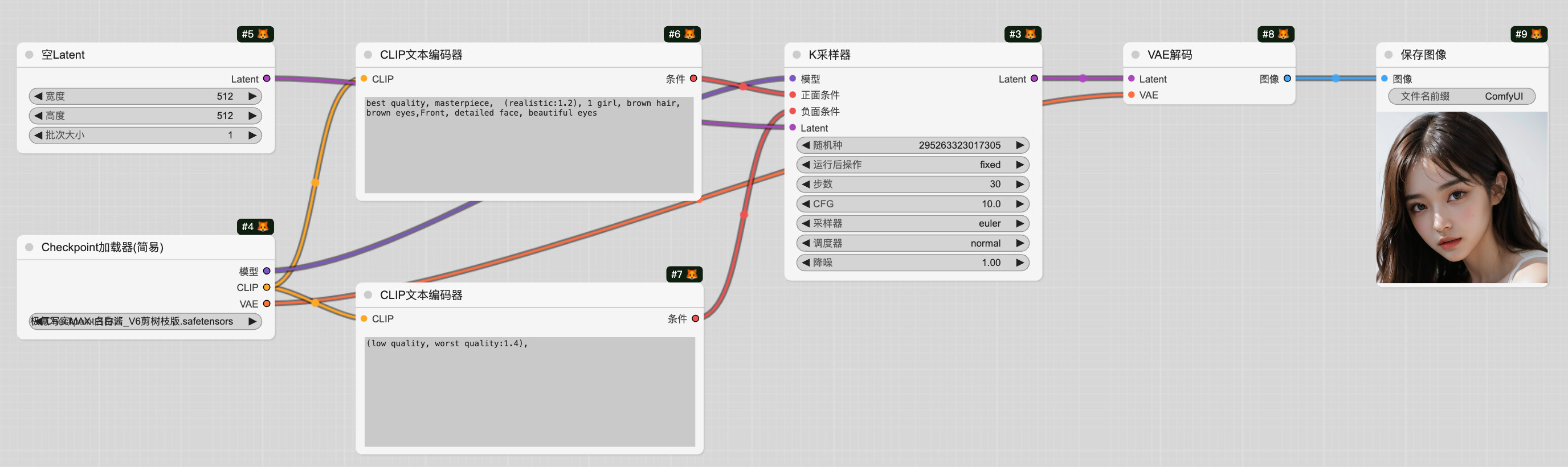
Load Checkpoint节点:选择stable diffusion底模,输出model、clip、vae
CLIPText Encode(Prompt)节点:输入正向提示和负向提示,输入的文本将被clip模型进行编码。
Latent:生成空间图片,可以配置图片的长、宽、数量
KSampler节点:K采样器,输入model、编码后的正向提示、编码后的负向提示、隐空间图片,配置随机种子、扩散步
数、降噪强度等参数
VAE Decode节点:用于将隐空间中的图片解码成像素空间的图片。
K采样器中的一些主要参数
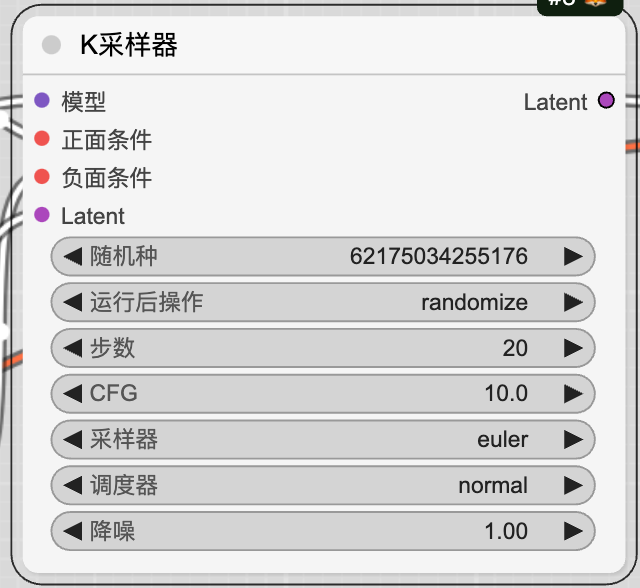
随机种:随机种指的是控制采样器从模型中抽取噪点的一致性。就像一个电影的 剧本 **初稿,不同的种子就能带出不同的创作灵感。**如果随机种固定,那么在其他参数、节点的条件下,生成出来的图片是一样的。
运行后操作:里面有四个选项,固定、增加、减少、随机,和随机种参数搭配使用。
步数:所谓慢工出细活,步数越多,效果越精细, 出图越慢;但是到了某个数值之后,画质就没有明显的提升了。一般来说步数越多图像的细节越丰富,但是也越容易出现噪点。较小的图像使用较少的步数,较大的图像使用较多的步数。
CFG:CFG越高饱和度越高,不影响出图时间.。CFG越高,生成的图像越贴近于CLIP文本,饱和度越高。反之图像生成更自由,会偏离CLIP文本。一般设置为10左右,默认为8,既保证一定的创造自由,又能忠于CLIP提示词。
在ComfyUI中,采样器和调度器的选择对于生成图像的质量和效率至关重要。
采样器:主要负责控制去噪的具体操作,其性能指标包括收敛性。不同的采样器有不同的收敛速度和质量,有些采样器能迅速收敛,适合快速验证创意,而其他一些可能需要更长的时间或更多的步骤才能达到相同的收敛状态,但通常能提供更高质量的结果。还有一些采样器没有设定极限,永远不会收敛,为创新和创造性提供了更多空间。例如,dpmpp-sde采样器就是一种能够提供高质量图像的采样器。
调度器:负责调控去噪的程度,决定每一步去除多少噪声,以确保整个过程既高效又精准。选择合适的调度器对于生成图像的细节保持非常重要。在雕刻的比喻中,调度器的作用类似于在雕刻的不同阶段使用不同的力度,初期使用较大的力度快速去除大块的部分,而在细节处理阶段则需要细致和谨慎,以防止雕塑出现破损。例如,karras调度器就是一种能够根据图像生成的进度动态调整去噪力度的调度器。
因此,选择合适的采样器和调度器对于提高出图质量至关重要。通过调整采样器和调度器的参数,可以显著影响生成图像的质量和效率。例如,通过使用dpmpp-sde采样器和karras调度器,可以在保证图像质量的同时,提高生成效率。
优先采用的采样器:
| euler | 经典之选,快速且可靠 |
|---|---|
| dpmpp 2m | 速度质量完美结合 |
| uni_pc | 效率高,5-10步快速出图 |
| dpmpp_2m_sde | 质量更好 |
| dpm_adaptive | 自适应,快速稳定 |
| ddpm | 质量好,画风细腻 |
优先尝试的调度器:
| karras | 噪声调度,质量更好 |
|---|---|
| exponential | 指数调度,快速生图 |
| sgm_uniform | 简单均匀调度,质量一致性好 |
| normal | 标准,稳定性好 |
降噪:该数值是指去噪的强度,这个值越高生成的图片就越清晰、越平滑,但是会缺失一些细节。
用图来说明CFG对结果的影响

用图来说明步数对结果的影响

用图来说明 降噪对于结果的影响
参考文档:
https://bytetech.info/articles/7389436329219588122?searchId=202407231627081EBF75D3744C32B59C4C
https://blog.csdn.net/matt45m/article/details/136872286
https://blog.csdn.net/u010618499/article/details/134010897