之前的内容
快到三级了,给大佬们分享一个python 源码,是在大佬们deeplx和前辈们文件的基础上改的,不需要计算时间戳之类的,直接要一个deepl pro 账号登录后在翻译页面获取的dl_session 值即可,源代码中已经内置了一个cookie 值了,你们也可以用自己的值。严格上说还没有完全实现转api,但能实现不限量翻译了,大佬们就自己修改来适用自己的需求吧!

好像不能上传python 格式文件哇,我复制一下:
import json
import random
import requests
def init_data(source_lang,target_lang):
return {
"jsonrpc": "2.0",
"method": "LMT_handle_texts",
#"method": "LMT_handle_jobs",
"id": random.randint(100000, 109999) * 1000,
"params": {
"splitting": "newlines",
"lang": {
"source_lang_user_selected": source_lang,
"target_lang": target_lang,
},
},
}
def deeplpro(data):
global proxies, enable_proxy_or_not, text_str, cookie, from_lang, to_lang, lang_list
source_lang=from_lang
target_lang=to_lang
if text_str.strip()=="":
return {"data": ""} #原文为空,直接返回空内容
url = "https://api.deepl.com/jsonrpc"
post_data = init_data(source_lang, target_lang)
text = {
"text": text_str,
#"requestAlternatives": 3,
}
post_data["params"]["texts"] = [text]
post_str = json.dumps(post_data)
headers={
"Content-Type": "application/json",
"origin": "https://www.deepl.com",
"referer": "https://www.deepl.com/",
"Cookie": cookie,
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
try:
if(enable_proxy_or_not):
response = requests.post(url, post_str, headers=headers,proxies=proxies,timeout=10)
else:
response = requests.post(url, post_str, headers=headers,timeout=10)
response_json = response.json()
except Exception as e:
print("超时或出错,重新调用再翻译",e)
return deeplpro(data)
return {
"code": 200,
"id": post_data["id"],
"data": response_json["result"]["texts"][0]["text"],
}
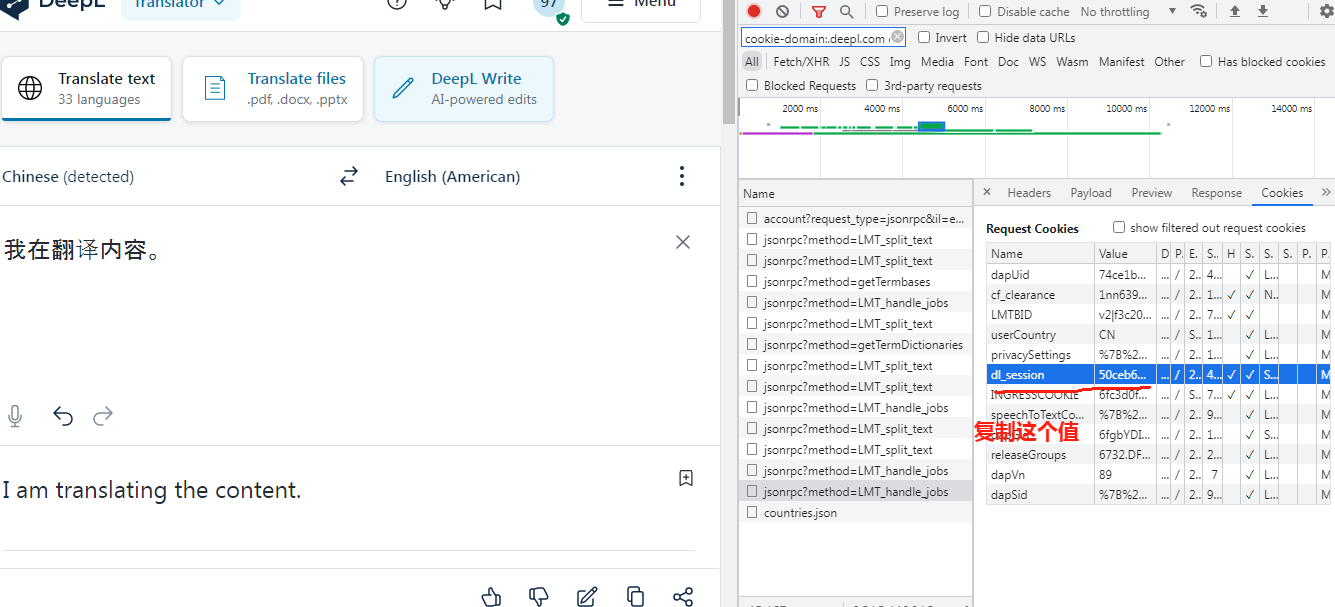
#【【【以下cookie值如果失效,需要您自己去获得deepl pro账号登录后在翻译页面翻译后按F12键打开显示的dl_session值,或者一长串cookie值也可以】】】
cookie="dl_session=50ceb6b1-4829-43a8-b098-487fdd67c034;" #修改这个值,可见下图如何获取该值
proxies = {
'http': 'http://127.0.0.1:8580',
'https': 'https://127.0.0.1:8580'
}
enable_proxy_or_not=False
lang_list = [ "zh", "en", "ja", "ko", "fr", "ru", "de", "es", "it", "nl", "pl", "pt", "bg", "cs", "da", "el", "et", "fi", "hu", "lt", "lv", "ro", "sk", "sl", "sv"]
text_str=input("输入要翻译的内容:")
print("以下仅举例翻译成语言列表中前几种语言,你可根据情况修改。")
#text_str="I love you" #要翻译的字符串,可多行
from_lang="auto"
to_lang="zh"
data = {
"text": text_str,
"source_lang": from_lang,
"target_lang": to_lang,
}
for i in range(10): #len(lang_list)):
to_lang=lang_list[i]
print(to_lang)
result=deeplpro(data)["data"]
print(result)
复制以下两个值任意一个均可,然后修改代码中的cookie变量值为你复制的值:
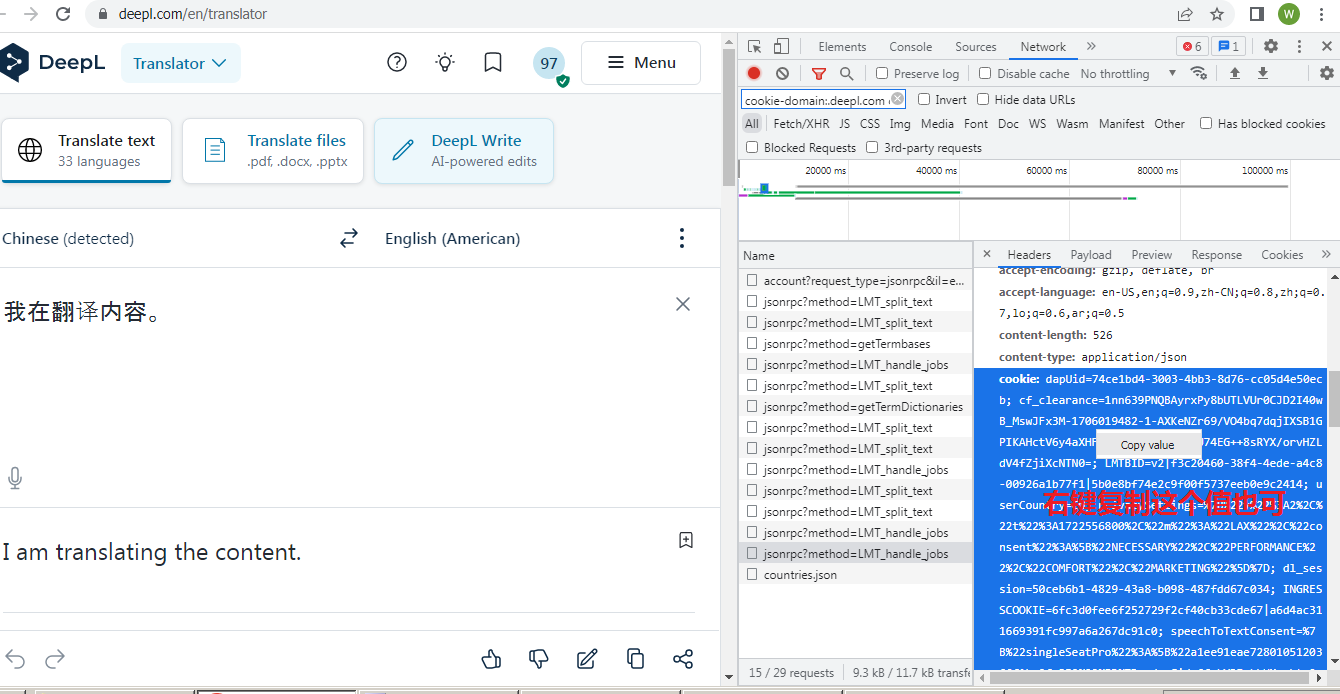
上方内容可以不用管了
————分割线————
以下为更新后的内容,目前已实现在沉浸式翻译里调用:
先上更新后的源码(发现之前的有bug,修改一下):
# 导入必要的库
import json
import random
import requests
from flask import Flask, request, jsonify
import threading
import tkinter as tk
from tkinter import messagebox
import pickle
import logging
import sys
import os
import webbrowser
if sys.stdout is None:
sys.stdout = open(os.devnull, 'w')
if sys.stderr is None:
sys.stderr = open(os.devnull, 'w')
def init_data(source_lang,target_lang):
return {
"jsonrpc": "2.0",
"method": "LMT_handle_texts",
#"method": "LMT_handle_jobs",
"id": random.randint(100000, 109999) * 1000,
"params": {
"splitting": "newlines",
"lang": {
"source_lang_user_selected": source_lang,
"target_lang": target_lang,
},
},
}
def deeplpro(in_text):
global proxies, enable_proxy_or_not, text_str, cookie, from_lang, to_lang, lang_list
data=in_text
source_lang=from_lang
target_lang=to_lang
if text_str.strip()=="":
return {"data": ""} #原文为空,直接返回空内容
url = "https://api.deepl.com/jsonrpc"
post_data = init_data(source_lang, target_lang)
text = {
"text": text_str,
#"requestAlternatives": 3,
}
post_data["params"]["texts"] = [text]
post_str = json.dumps(post_data)
headers={
"Content-Type": "application/json",
"origin": "https://www.deepl.com",
"referer": "https://www.deepl.com/",
"Cookie": cookie,
"user-agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
}
#print(headers)
try:
if(enable_proxy_or_not):
response = requests.post(url, post_str, headers=headers,proxies=proxies,timeout=10)
else:
response = requests.post(url, post_str, headers=headers,timeout=10)
response_json = response.json()
#print(response_json)
if('error' in response_json):
return {
"code": 403,
"id": post_data["id"],
"data": response_json['error']['message'],
}
except Exception as e:
print("超时或出错,重新调用再翻译",e)
return deeplpro(data)
return {
"code": 200,
"id": post_data["id"],
"data": response_json["result"]["texts"][0]["text"],
}
proxies = {
'http': 'http://127.0.0.1:8580',
'https': 'https://127.0.0.1:8580'
}
enable_proxy_or_not=False
lang_list = [ "zh", "en", "ja", "ko", "fr", "ru", "de", "es", "it", "nl", "pl", "pt", "bg", "cs", "da", "el", "et", "fi", "hu", "lt", "lv", "ro", "sk", "sl", "sv"]
text_str="hello world" #要翻译的字符串,可多行
from_lang="auto"
to_lang="zh"
data = {
"text": text_str,
"source_lang": from_lang,
"target_lang": to_lang,
}
# 全局变量,用于存储用户信息
user_info_file = 'user_info.pkl'
# 尝试加载已保存的用户信息
try:
with open(user_info_file, 'rb') as f:
saved_info = pickle.load(f)
except FileNotFoundError:
saved_info = {'dl_session': '', 'port': 2024} # 如果文件不存在,则初始化为空字符串和默认端口号2024
# 创建Flask应用
app = Flask(__name__)
# 定义处理POST和GET请求的函数
@app.route('/', methods=['GET'])
def index():
port_str = port_entry.get()
return f"欢迎使用DeepL Pro转API,使用方法请看readme.pdf!<br/>现在可将地址http://127.0.0.1:{port_str}/translate填入沉浸式翻译等进行翻译。"
#支持post和get请求的翻译api
@app.route('/translate', methods=['POST', 'GET'])
def process_request():
global proxies, enable_proxy_or_not, text_str, cookie, from_lang, to_lang, lang_list,data
if request.method == 'POST':
# 处理POST请求
from_lang = request.json.get('source_lang', '')
to_lang = request.json.get('target_lang', '')
text_str = request.json.get('text', '')
result=deeplpro(data)
elif request.method == 'GET':
# 处理GET请求
from_lang = request.args.get('source_lang', '')
to_lang = request.args.get('target_lang', '')
text_str = request.args.get('text', '')
result=deeplpro(data)
print(result["data"])
# 返回JSON响应
return jsonify(result)
# 保存用户信息到pkl文件
def save_user_info():
with open(user_info_file, 'wb') as f:
pickle.dump(saved_info, f)
# 启动Flask应用的函数
def run_flask_app():
try:
app.run(host='0.0.0.0', port=saved_info['port'], debug=False, use_reloader=False)
except OSError as e:
messagebox.showerror("错误", f"未能启动服务器:{e}")
# tkinter界面函数
def start_web_service():
global start_button, address_label
global text_str, from_lang, to_lang, data, cookie
cookie = dl_session_entry.get()
if("dl_session=" in cookie):
pass
else:
cookie="dl_session="+cookie
result=deeplpro(data)
print(result)
if(result["code"]==403):
messagebox.showerror("错误", "启动服务失败,错误原因为dl_session过期或无效。请确保登录了deepl Pro账号或成员账号,然后不要退出。")
return
else:
messagebox.showinfo("提示","翻译校验成功,点击确定开启web服务!")
if start_button.cget('text') == "启动服务":
# 获取输入框中的字符串和端口号
dl_session = dl_session_entry.get()
port_str = port_entry.get()
try:
port = int(port_str)
except ValueError:
messagebox.showerror("错误", "端口号应为整数")
return
# 更新全局变量中的信息
saved_info['dl_session'] = dl_session
saved_info['port'] = port
# 保存用户信息到文件
save_user_info()
# 在新线程中启动Flask应用
threading.Thread(target=run_flask_app, daemon=True).start()
# 更新界面
start_button.config(text="如需停止服务,直接关闭本窗口")
address_label.config(text=f"Web服务地址: http://127.0.0.1:{port}/translate")
webbrowser.open(f"http://127.0.0.1:{port}/")
else:
# 更新界面
start_button.config(text="启动服务")
address_label.config(text="")
# 创建tkinter界面
root = tk.Tk()
root.title("DeepL Pro转API服务")
# 输入框和标签,使用已保存的信息填充默认值
tk.Label(root, text="填写dl_session或cookie:").grid(row=0, column=0)
dl_session_entry = tk.Entry(root)
dl_session_entry.insert(0, saved_info['dl_session'])
dl_session_entry.grid(row=0, column=1)
tk.Label(root, text="端口号:").grid(row=1, column=0)
port_entry = tk.Entry(root)
port_entry.insert(0, saved_info['port'])
port_entry.grid(row=1, column=1)
# 启动按钮和地址标签
start_button = tk.Button(root, text="启动服务", command=start_web_service)
start_button.grid(row=2, columnspan=2)
address_label = tk.Label(root, text="")
address_label.grid(row=3, columnspan=2)
# 运行tkinter主循环
root.mainloop()
程序运行起来后如下所示:
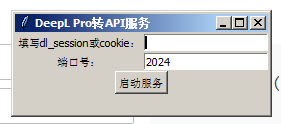
- 找个deepl账号或上了deepl pro车的账号登录 deepl.com,不要退出,填入dl_session值或cookie值;该值如何找如上面的截图所示,我这里也再粘贴一次。
暂时有效的一个cookie值:dl_session=46fb6935-9339-4501-804d-b842cf1a1afd;
填写dl_session开始一直到后面的分号(包括分号) ,目前作了改进,可直接填写dl_session=之后的内容了,也可以不要分号
将上面获取的值复制粘贴到下图中的输入框中:
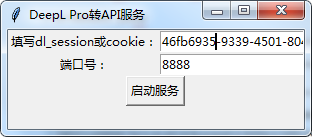
点启动服务。
-
如果一切正常,则会显示如下:
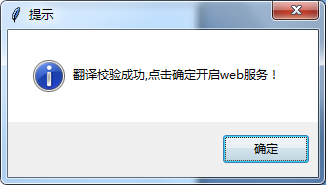
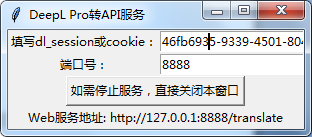
那个端口地址可以自定义,默认值是2024
会打开本地web服务的主页,上面也有写该填写哪个地址(注意,这个地址是内网址,外网可能无法访问):
-
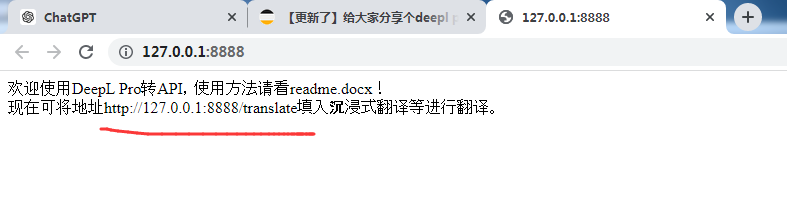
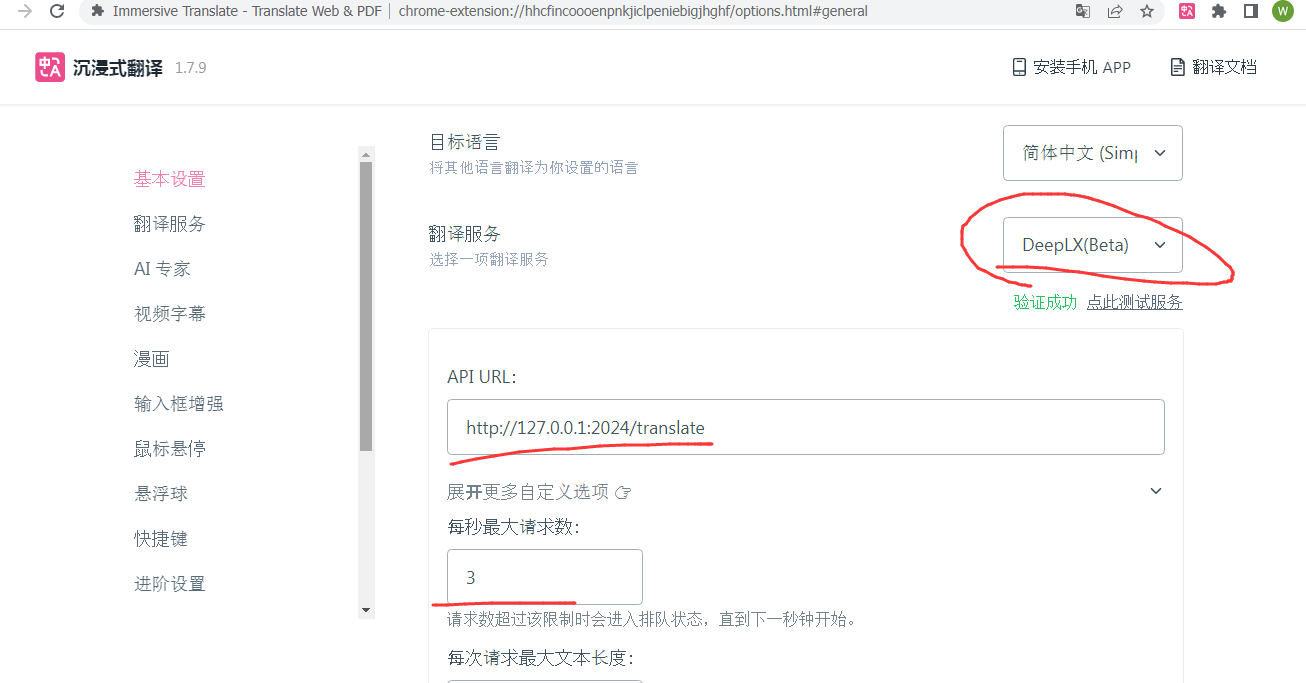
接下来,将接口地址http://127.0.0.1:2024/translate 填入到沉浸式翻译即可,我好像打包时运行保存了填写的数据,那就填写http://127.0.0.1:8888/translate 吧:
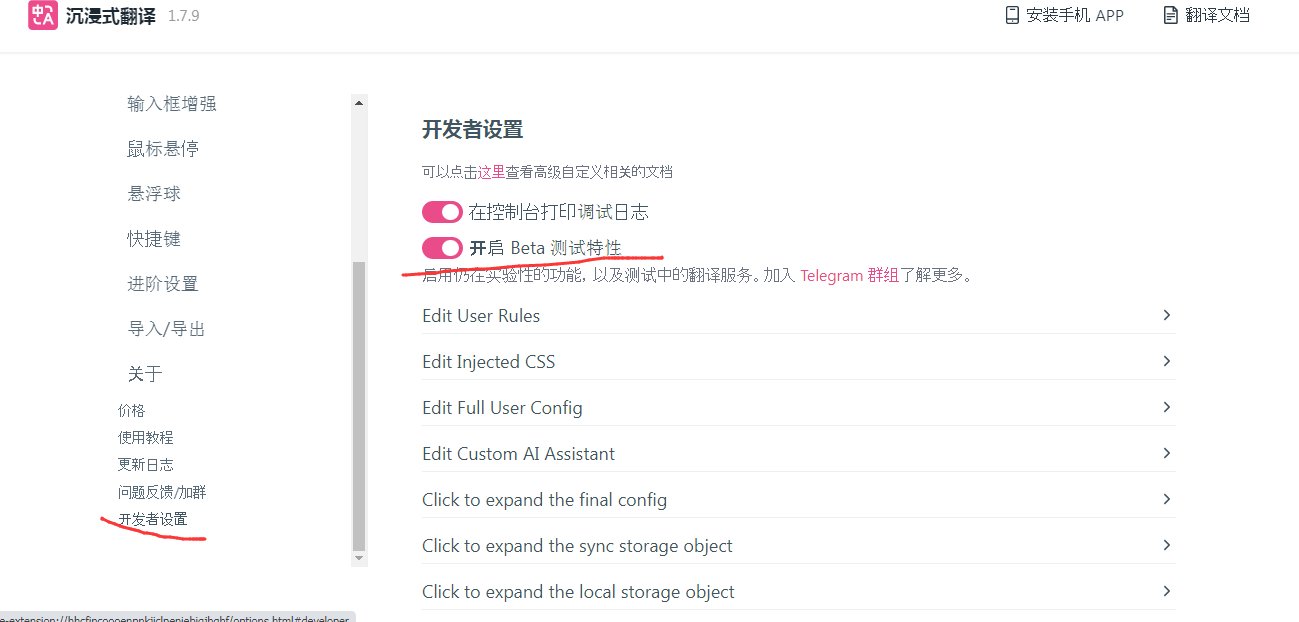
大家可能会一开始找不到这个deeplx(Beta)选项,只需要在左侧“开发者设置”里打开“开启Beta测试特性”就有了。
-
接下来就是愉快的使用了!
翻译效果如下:
最后,我把程序打个包呢。欢迎使用!百度网盘链接: 百度网盘 请输入提取码 提取码: 8888