问题描述
Nvidia模型调用接口兼容Openai,但在实际使用中发现返回的数据包中前面第一个数据包的content字段为null("delta":{"role":"assistant","content":null}),如果连续对话,还会出现前几个数据chunk都是这样的,而且后续的chunk中的role也为null,这会导致两个问题:
- 在chatbox中回复前面会把null打印出来,不美观;
- 在Cursor中数据解析会出错,无法使用。
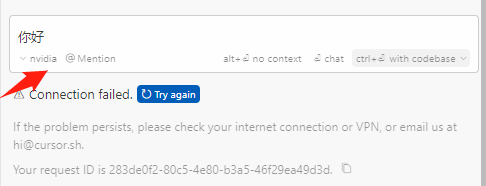

看了一圈,论坛竟然没人讨论,我这个没有正经编程的决定挑战一把,自己解决,以下是分析和解决的过程,有需要的佬可以自行部署。
问题定位
使用POST分别请求gpt-4o和nvidia返回的数据,将response保存下来,进行比对:
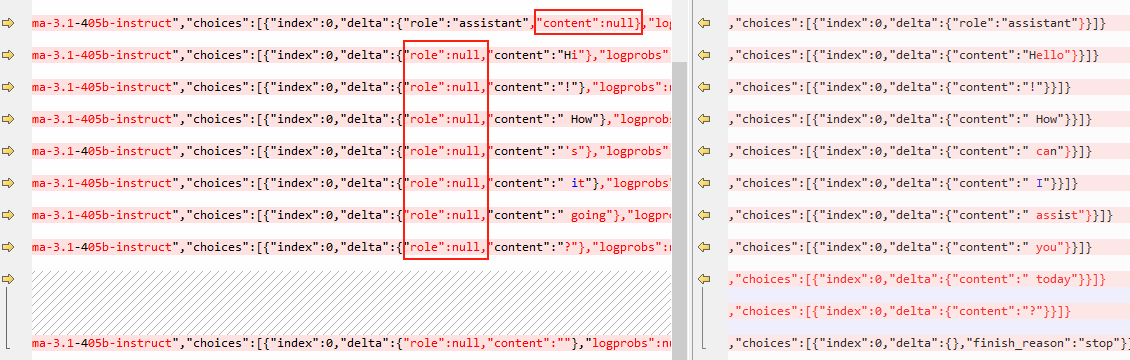
可以看到,Nvidia返回的数据前面有几包可能会出现content字段为null的情况,同时后续的包中还会存在role为null的数据字段,需要构造一个服务将返回的数据包转换为和gpt-4o一致的,也就是一个代理服务,使用worker实现最容易了,但是介于我只会一点python的皮毛,还是先用python实现,worker能不能就看缘分了(后来worker借助claude竟然实现了~~~)。
python方案
在claude的帮助下,写了一个基于Flask的api服务,可以代理流式和非流式请求。
from flask import Flask, request, Response, stream_with_context, jsonify
import requests
import json
import time
import uuid
import logging
app = Flask(__name__)
logging.basicConfig(level=logging.DEBUG)
NVIDIA_API_URL = "https://integrate.api.nvidia.com/v1/chat/completions"
def convert_to_openai_format(nvidia_data, is_stream=True):
openai_data = {
"id": nvidia_data.get("id", str(uuid.uuid4())),
"object": "chat.completion.chunk" if is_stream else "chat.completion",
"created": nvidia_data.get("created"),
"model": nvidia_data.get("model"),
"choices": []
}
if "choices" in nvidia_data and nvidia_data["choices"]:
for i, choice in enumerate(nvidia_data["choices"]):
openai_choice = {
"index": i,
"finish_reason": choice.get("finish_reason")
}
if is_stream:
openai_choice["delta"] = {}
if "delta" in choice:
delta = choice["delta"]
# 当delta中的role或者content不为空时,才包含该部分数据
if delta.get("role"):
openai_choice["delta"]["role"] = delta["role"]
if delta.get("content"):
openai_choice["delta"]["content"] = delta["content"]
else:
openai_choice["message"] = {
"role": choice.get("message", {}).get("role", "assistant"),
"content": choice.get("message", {}).get("content", "")
}
openai_data["choices"].append(openai_choice)
if not is_stream:
openai_data["usage"] = nvidia_data.get("usage", {})
return openai_data
def generate_openai_response(nvidia_response):
for line in nvidia_response.iter_lines():
if line:
logging.debug(f"original line: {line}")
try:
if line.startswith(b"data: "):
json_str = line.decode('utf-8').split("data: ", 1)[1]
if json_str.strip() == "[DONE]":
yield "data: [DONE]\n\n"
continue
nvidia_data = json.loads(json_str)
openai_data = convert_to_openai_format(nvidia_data)
# 当delta.content不为空,或者finish_reason为stop时,才返回数据
if openai_data.get("choices")[0].get("delta").get("content") or openai_data.get("choices")[0].get("finish_reason") == "stop":
yield f"data: {json.dumps(openai_data)}\n\n"
logging.debug(f"opean line: {openai_data}")
print("====================")
else:
logging.warning(f"Skipping line")
continue
else:
logging.warning(f"Skipping line: {line}")
except json.JSONDecodeError as e:
logging.error(f"JSON decode error: {e}")
except Exception as e:
logging.error(f"Unexpected error: {e}")
@app.route('/v1/chat/completions', methods=['POST'])
def chat_completions():
data = request.json
auth_header = request.headers.get('Authorization')
headers = {
'Authorization': f'{auth_header}',
# 'Authorization': f'Bearer {NVIDIA_API_KEY}',
'Content-Type': 'application/json'
}
# Replace the model name if necessary
if "model" in data:
data["model"] = "meta/llama-3.1-405b-instruct"
is_stream = data.get('stream', False)
try:
nvidia_response = requests.post(NVIDIA_API_URL, headers=headers, json=data, stream=is_stream)
nvidia_response.raise_for_status()
if is_stream:
return Response(stream_with_context(generate_openai_response(nvidia_response)), content_type='text/event-stream')
else:
nvidia_data = nvidia_response.json()
openai_data = convert_to_openai_format(nvidia_data, is_stream=False)
return jsonify(openai_data)
except requests.RequestException as e:
logging.error(f"Error making request to NVIDIA API: {e}")
return jsonify({"error": "Error communicating with NVIDIA API"}), 500
if __name__ == '__main__':
# app.run(debug=True, port=5000)
app.run(debug=True, port=5000, host='0.0.0.0')
cloudflare worker
为了少浪费vps的资源,还是部署到worker好一些,在上述python代码的基础上,使用claude将代码转换为worker脚本,在转换过程中出了一些问题,但claude还是基于提供的错误完成了代码的修改。cloudflare worker代理的脚本如下,可以去除Nvidia官方返回中不符合openai标准的部分,并丢弃其中content为null的部分,在chatbox中不会再显示null字符,也支持在cursor中进行调用。代码如下:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request))
})
const NVIDIA_API_URL = "https://integrate.api.nvidia.com/v1/chat/completions"
function convertToOpenAIFormat(nvidiaData, isStream = true) {
const openaiData = {
id: nvidiaData.id || crypto.randomUUID(),
object: isStream ? "chat.completion.chunk" : "chat.completion",
created: nvidiaData.created,
model: nvidiaData.model,
choices: []
}
if (nvidiaData.choices && nvidiaData.choices.length > 0) {
nvidiaData.choices.forEach((choice, i) => {
const openaiChoice = {
index: i,
finish_reason: choice.finish_reason
}
if (isStream) {
openaiChoice.delta = {}
if (choice.delta) {
if (choice.delta.role) openaiChoice.delta.role = choice.delta.role
if (choice.delta.content) openaiChoice.delta.content = choice.delta.content
}
} else {
openaiChoice.message = {
role: choice.message?.role || "assistant",
content: choice.message?.content || ""
}
}
openaiData.choices.push(openaiChoice)
})
}
if (!isStream) {
openaiData.usage = nvidiaData.usage || {}
}
return openaiData
}
async function* generateOpenAIResponse(response) {
const reader = response.body.getReader()
const decoder = new TextDecoder()
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
for (let i = 0; i < lines.length - 1; i++) {
const line = lines[i].trim()
if (line.startsWith('data: ')) {
const jsonStr = line.slice(5).trim()
if (jsonStr === '[DONE]') {
yield 'data: [DONE]\n\n'
continue
}
try {
const nvidiaData = JSON.parse(jsonStr)
const openaiData = convertToOpenAIFormat(nvidiaData)
yield `data: ${JSON.stringify(openaiData)}\n\n`
} catch (error) {
console.error('Error parsing JSON:', error)
}
}
}
buffer = lines[lines.length - 1]
}
if (buffer.trim().length > 0) {
console.warn('Unprocessed data in buffer:', buffer)
}
}
async function handleRequest(request) {
if (request.method !== 'POST' || !request.url.endsWith('/v1/chat/completions')) {
return new Response('Not Found', { status: 404 })
}
const authHeader = request.headers.get('Authorization')
if (!authHeader) {
return new Response('Unauthorized', { status: 401 })
}
const data = await request.json()
const headers = {
'Authorization': authHeader,
'Content-Type': 'application/json'
}
if (data.model) {
data.model = "meta/llama-3.1-405b-instruct"
}
const isStream = data.stream || false
try {
const nvidiaResponse = await fetch(NVIDIA_API_URL, {
method: 'POST',
headers: headers,
body: JSON.stringify(data)
})
if (!nvidiaResponse.ok) {
throw new Error(`NVIDIA API responded with ${nvidiaResponse.status}`)
}
if (isStream) {
const stream = new ReadableStream({
async start(controller) {
try {
for await (const chunk of generateOpenAIResponse(nvidiaResponse)) {
controller.enqueue(new TextEncoder().encode(chunk))
}
} catch (error) {
console.error('Streaming error:', error)
controller.error(error)
} finally {
controller.close()
}
}
})
return new Response(stream, {
headers: { 'Content-Type': 'text/event-stream' }
})
} else {
const nvidiaData = await nvidiaResponse.json()
const openaiData = convertToOpenAIFormat(nvidiaData, false)
return new Response(JSON.stringify(openaiData), {
headers: { 'Content-Type': 'application/json' }
})
}
} catch (error) {
console.error('Error:', error)
return new Response(JSON.stringify({ error: 'Error communicating with NVIDIA API' }), {
status: 500,
headers: { 'Content-Type': 'application/json' }
})
}
}