M1上安装本地大模型做了个测试,发现效果还是太差了:
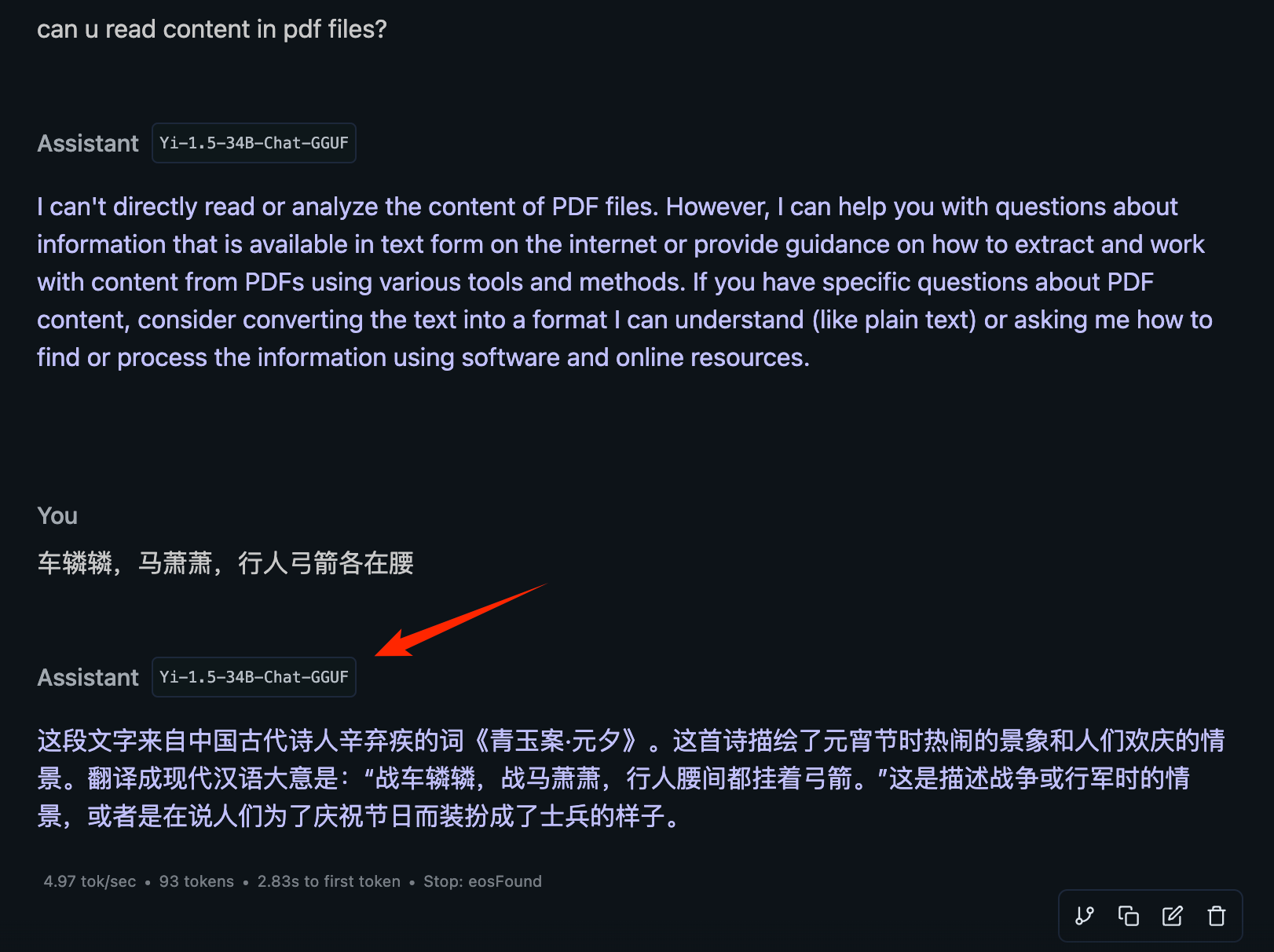
测试了:
LM:ollama,LM Studio
模型:Yi-1.5-34B, Qwen2.5-coder-32B
组合起来4种效果,和上面截图的结果差不多:一本正经的胡说八道
还是通过始皇的 oai API 调 GPT 得到的回答更靠谱一些
M1上安装本地大模型做了个测试,发现效果还是太差了:
测试了:
LM:ollama,LM Studio
模型:Yi-1.5-34B, Qwen2.5-coder-32B
组合起来4种效果,和上面截图的结果差不多:一本正经的胡说八道
还是通过始皇的 oai API 调 GPT 得到的回答更靠谱一些
本地肯定差啊。。
试试混元的那个
各种模型的软文还是不能太信
不是本地差,是小规模模型现在能力比较差,14B以下的模型现在基本处于探索+秀技作用,最大的用处是探索算法架构和训练方式等上限的(算法上限不是能力上限),这是努力的方向或者说代表未来的目标。本地、在线这是另一个评价指标,跟模型规模是两个不同的概念
这跟软文没关系,本地跑405B/110B/72B的模型照样很强
多谢大佬指点~
然后14以上,30左右这个规模的模型能够在agent中作为一定的生产力了,或者作为基座模型微调垂直类模型发挥专精的效果。
毕竟现在还不是AGI,这种规模的侧重点有限,需要做突出和组合
要知道 4o mini 的知识幻觉也很高,至少在文本流畅程度方面,本地模型已经很不错了,人家的模型不好,为什么敢收钱呢 ![]()
72B以上只能是M1以后的芯片了,M1系列内存最大64G,跑不起来
72b用q4量化的话显存占用大概在45G上下,50G内存可以跑的
正常,现在好用的模型起码是70B的,4o这级别的甚至要100-200B,本地跑个30B的开源模型,完全不能指望它好用
学到了,这个论坛就是热佬多!
![]() ,找个q4试试
,找个q4试试
本地跑现在最大的用途就是可以跑个qwen2.5:7B当个翻译,然后Qwen2vl当OCR,或者跑个coder 14B/32B配合copilot等编程框架编程用。至于当做问答这种还是算了,让他们去做专精的任务吧,别难为这些小模型了
羡慕本地可以运行的 ![]()
本地跑的Qwen2.5-coder-32B和api提供的效果不一样吗?
羡慕可以本地跑 100B的佬

