在腾讯云搭建免费GPU环境运行Ollama教程
前言
这几天看佬友论坛里面发了白嫖腾讯云GPU的一些帖子,昨天摸鱼,捣鼓了一下,现在分享记录一下
使用须知
缺点
- 部分机器下载模型速度较慢
- 装了通义的qwen2.5-coder:32b,回答吐字很慢,应该还是性能不够
- 每天凌晨会强制自动关机
- ngrok临时穿透的地址会变
- 不过ngrok可以绑定自定义域名,这样就不会频繁更换了
- 但是每天手动点开机确实麻烦,后续可探索自动化脚本解决方案
优点
- 白嫖
- 小模型无压力,自带的llama3回复吐字很快
- 或许可以小模型配合沉浸式翻译,实现自由?
运行环境
- Tencent Cloud Studio
- Ollama
- Ngrok (或其他内网穿透工具)
- OpenWebUI (可选)
详细步骤
1. 安装Ollama环境
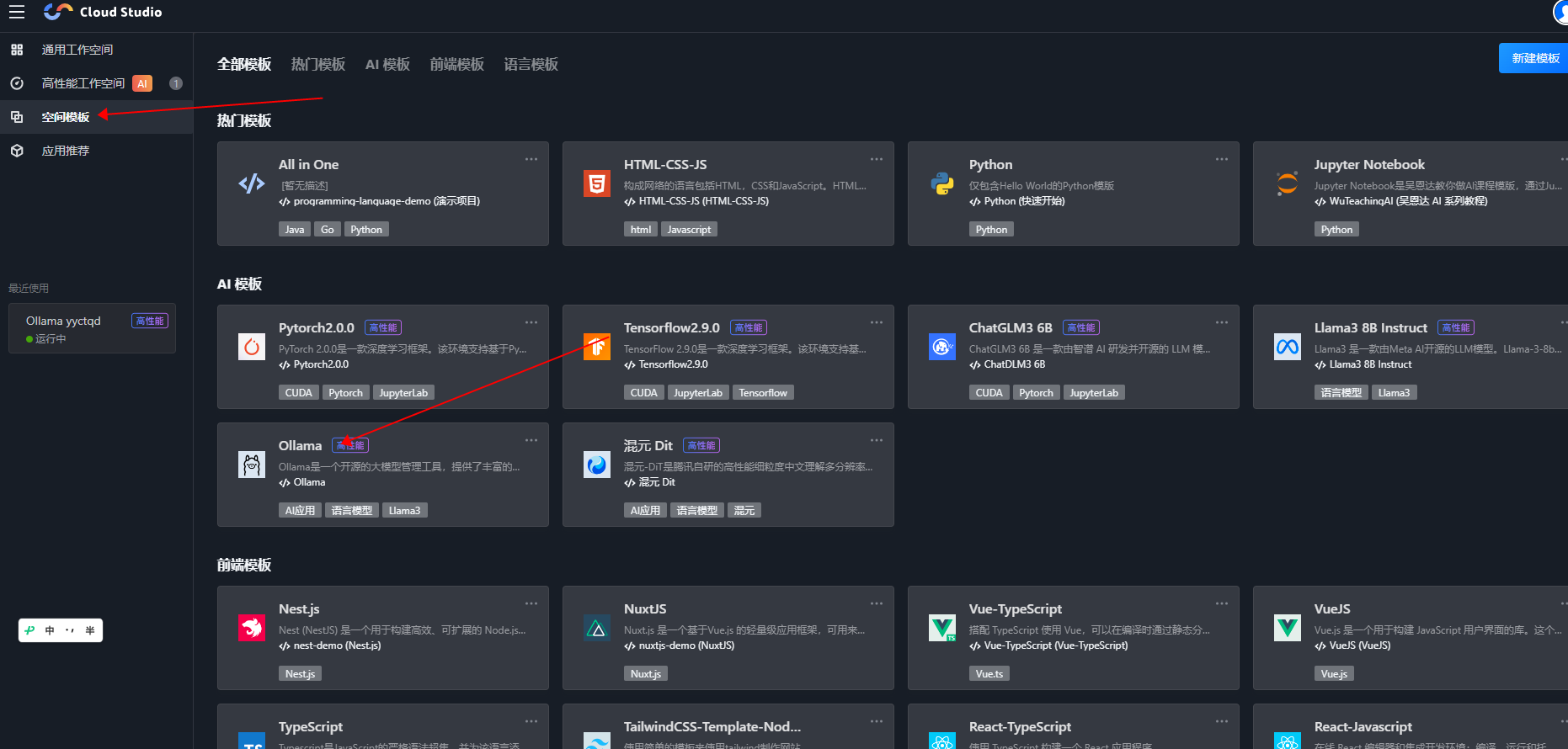
1.1 进入网站并登录
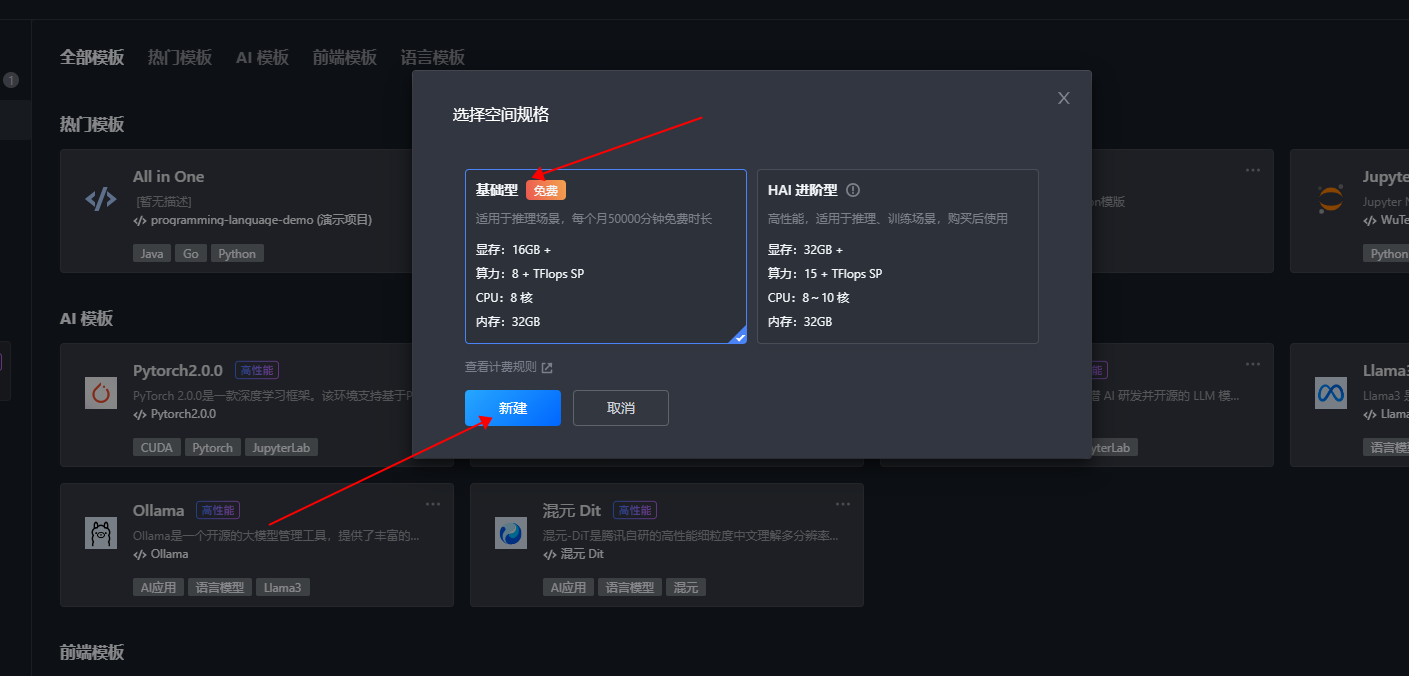
1.2 创建Ollama
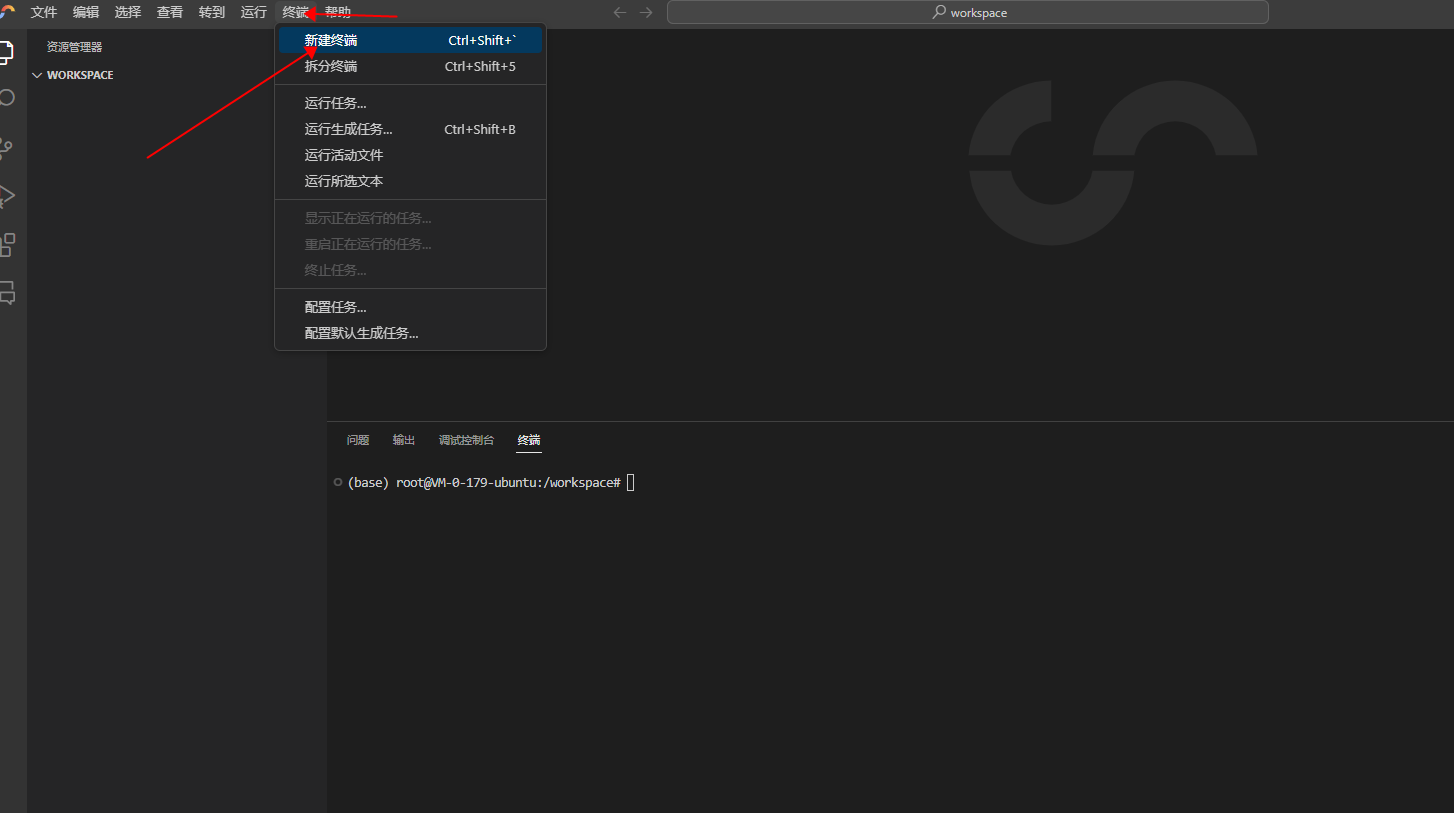
1.3 新建终端
1.4 验证安装
输入以下命令:
ollama

ollama list
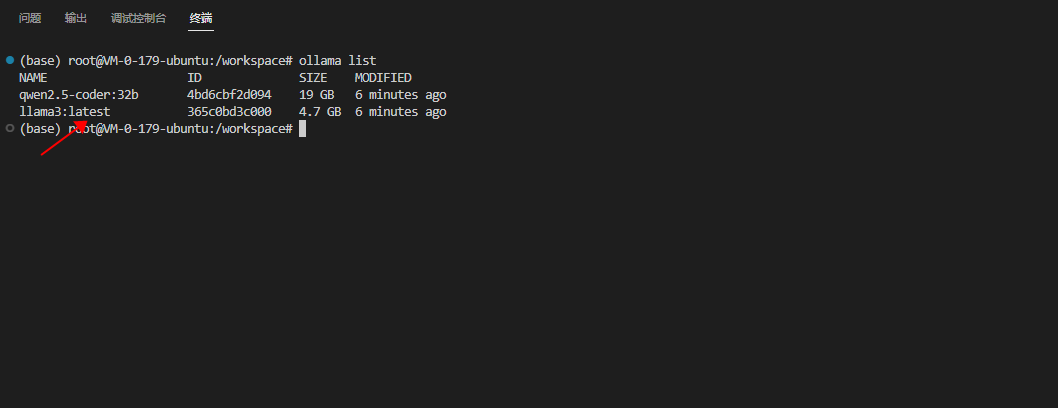
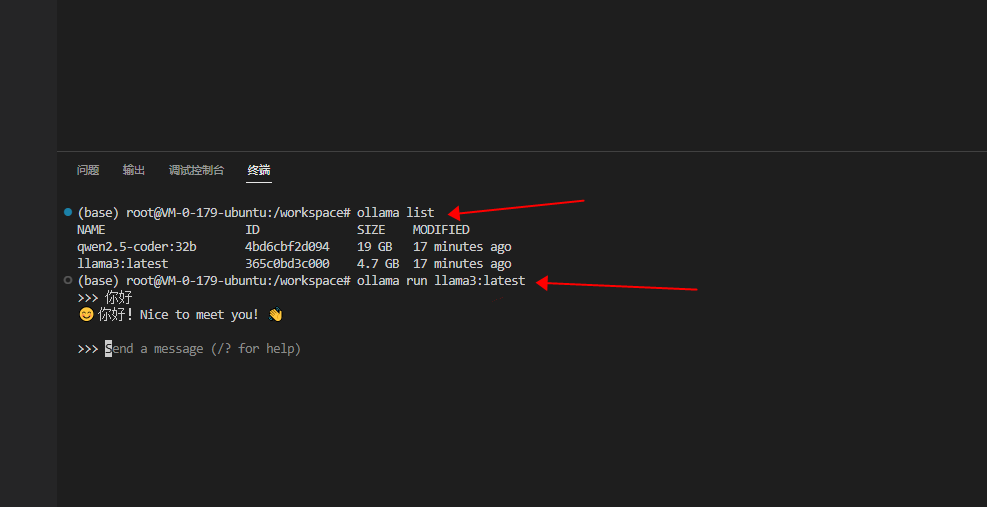
可以看到,已经预装好了,并且自带了Llama 3
1.5 启动服务
终端输入:
ollama serve
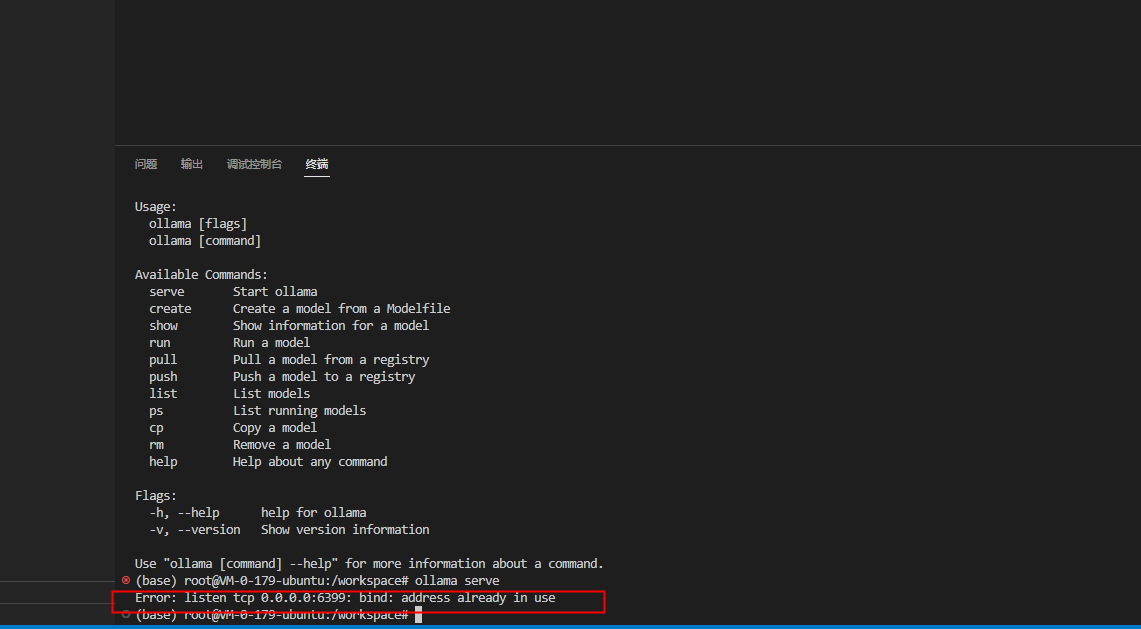
可以看到6399端口被占用了,现在就不用管了
1.6 基础使用测试
ollama list
ollama run llama3:latest
2. 安装ngrok
2.1 注册账号
2.2 进入配置页面
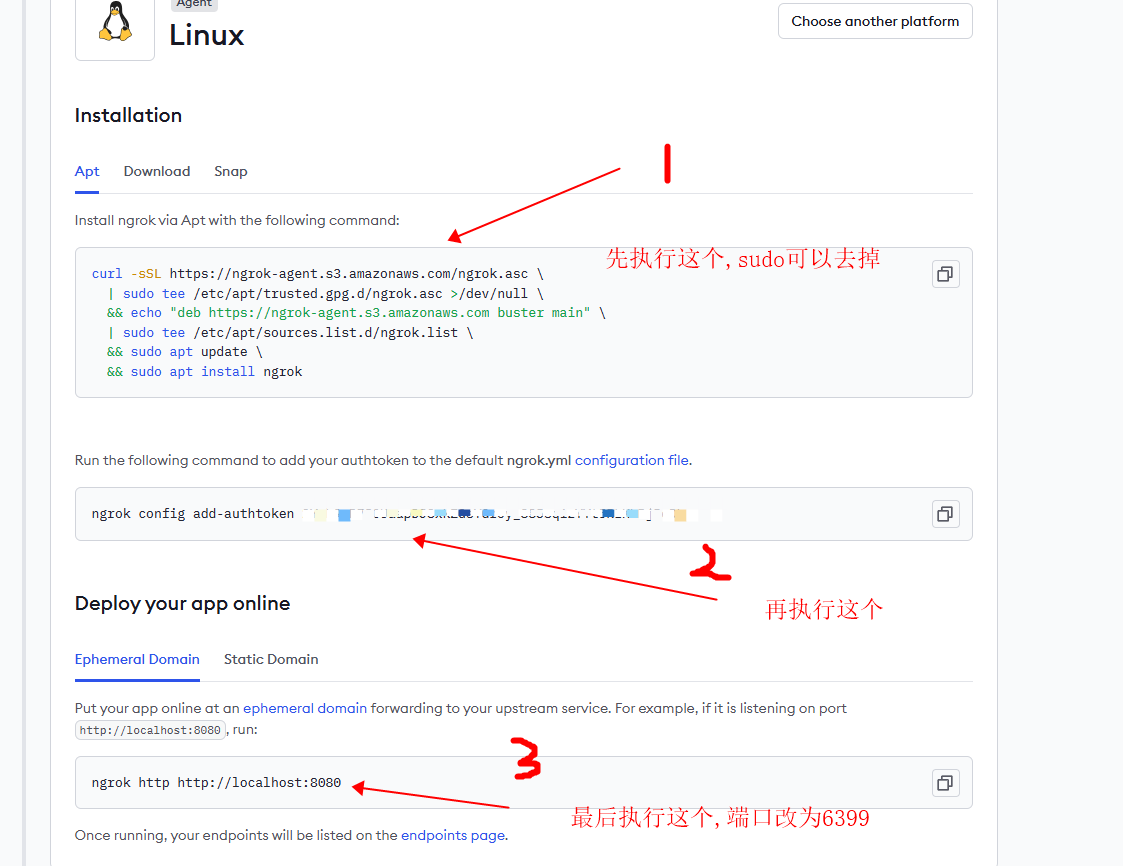
2.3 执行安装命令
按照页面提示执行相关命令:
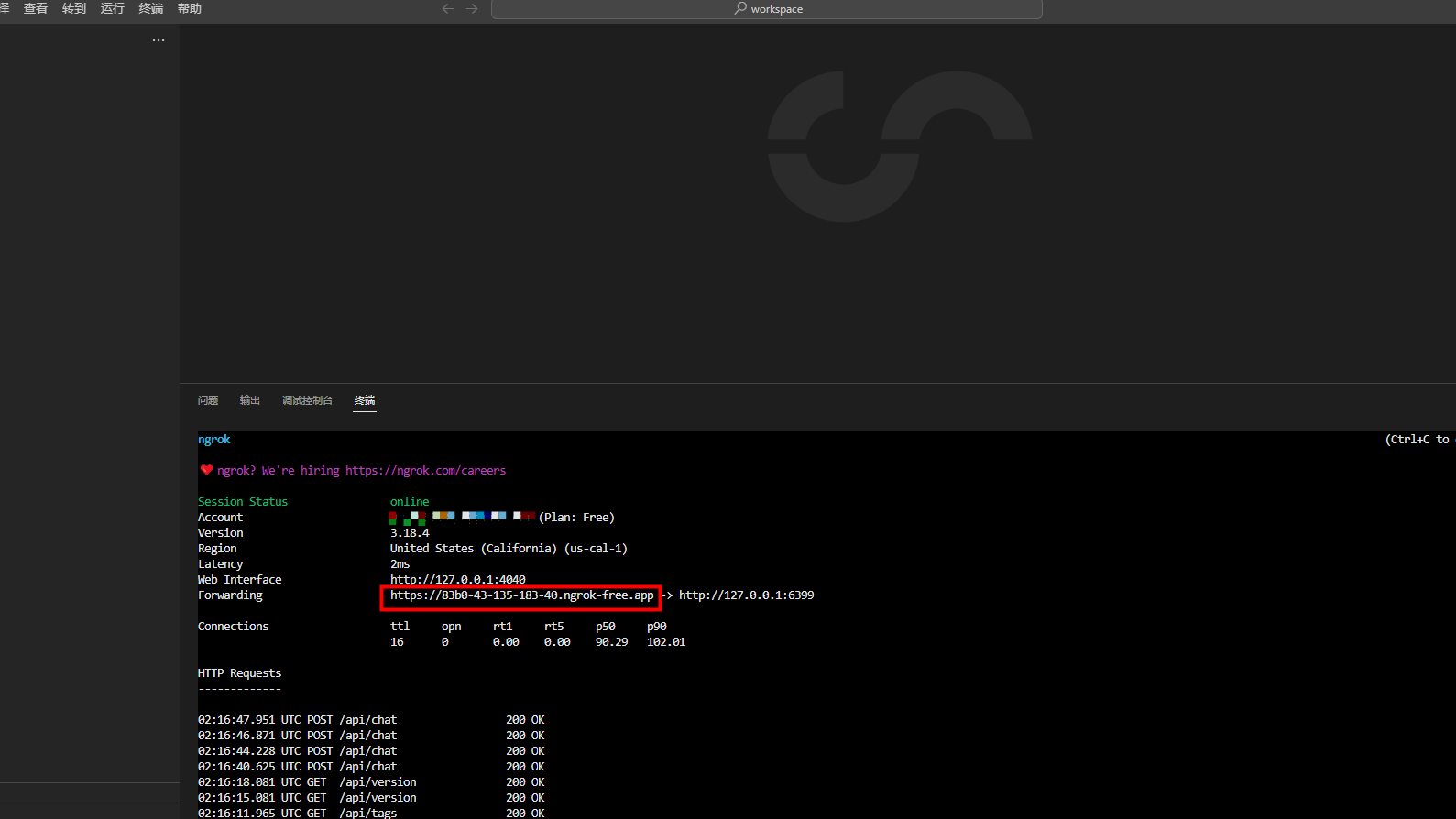
2.4 完成安装
这个时候终端应该是这样的,请记住红框里面的地址:
3. 安装OpenWebUI(可选)
这个就不赘述了,佬友们应该都装过了的
4. 配置OpenWebUI

4.1 获取模型

4.2 测试运行

补充说明
5.1 其他开源模型
访问模型库: library
5.2 安装方法
使用 ollama pull 命令安装对应模型ID
例如:
ollama run qwen2.5-coder
会自动下载安装:
感谢佬友补充
嘿嘿,写完之后,让AI给这篇教程润色一下,好看多了 ![]()
![]()
![]()

