版权声明
这些笔记基于《Python for Data Analysis, 3rd Edition》一书的内容总结和理解。原书由 Wes McKinney 编写,出版商为 O’Reilly,ISBN 978-1-098-10403-0。版权声明如下:
MIT License
Original work Copyright (c) 2024 Wes McKinney
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
起来晚了,主要是昨天练习代码的时间太长,学习的过程也比较坎坷,尤其是到了文件处理,编码格式那一块,我浪费了很多时间
在学习的过程中,我的情绪也十分低落,唉,怎么说呢,就是我的一个 bilibili 的一个评论,被人说了,但这也没什么,我把评论删掉就好了
后来我想着去网易云音乐,听听音乐缓解一下,发了一个痛苦的评论,表达自己讨厌这个世界,可是,唉,又被人骂了,骂的很难看,虽然他后来又把消息又删除了,可是,却成为了我不开心的起因,是我扎在我心里的倒刺本来想着,看看自己喜欢的视频,缓解一下,可是那个up的视频有被人举报了,唉
我好想哭,今天好倒霉, 我算哪根葱哪根蒜,我也就叫唤叫唤,然后被厌烦我叫声的人踹几脚,再被淬口吐沫,骂我一句老不死的狗东西,然后我再呜咽一声便睡下了,我真希望不要再醒来了,太讨厌这个世界了,真想立刻离开这个鬼世界,攒钱还是第一要务吧,要不然都没有选择安乐的资格
于是就这样我跌跌撞撞的把 python 基础部分学完了

Functions
这个在自学 python学习之路☞4.注释和函数 和 python学习之路☞14.函数再临之定义 参数 和 return 中有练习过,但是仍然不全面,这次就好好按照书里的介绍补充学习一下
Namespaces, Scope, and Local Functions
函数既可以访问内部的变量也可以访问全局变量
变量的作用域另一种说法是命名空间
默认情况下,函数内的变量都会分配给本地命名空间
本地命名空间在函数调用的时候创建填充,在函数执行完成时销毁
# 代码例子
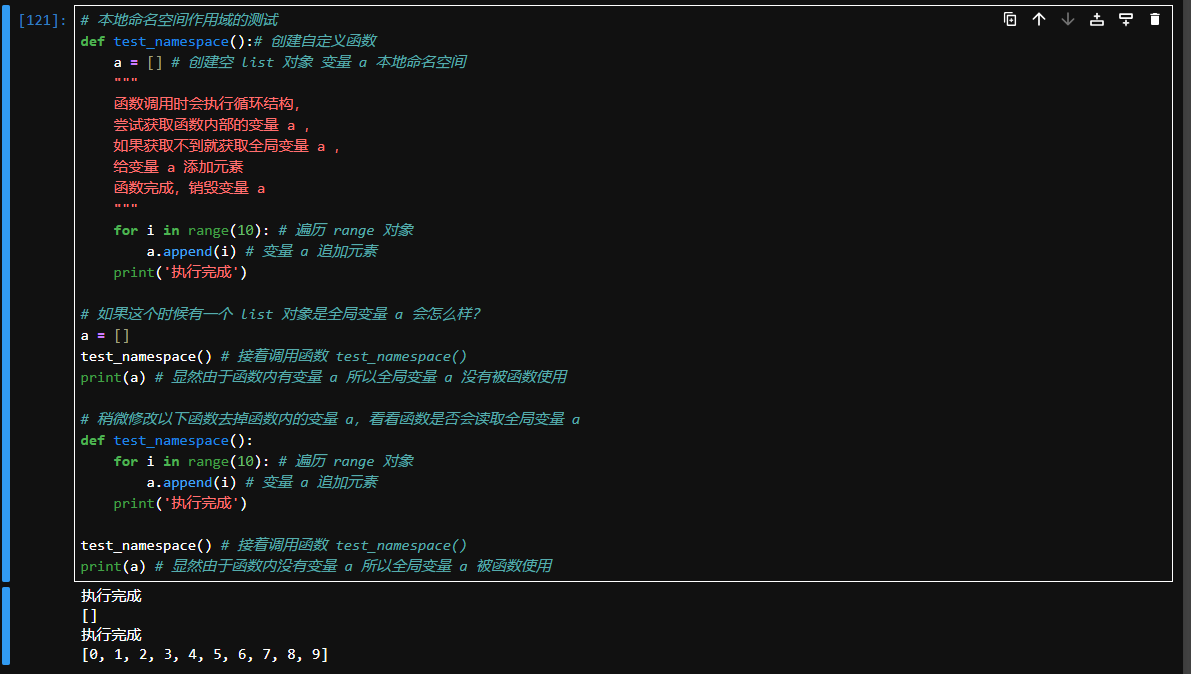
# 本地命名空间作用域的测试
def test_namespace():# 创建自定义函数
a = [] # 创建空 list 对象 变量 a 本地命名空间
"""
函数调用时会执行循环结构,
尝试获取函数内部的变量 a ,
如果获取不到就获取全局变量 a ,
给变量 a 添加元素
函数完成,销毁变量 a
"""
for i in range(10): # 遍历 range 对象
a.append(i) # 变量 a 追加元素
print('执行完成')
# 如果这个时候有一个 list 对象是全局变量 a 会怎么样?
a = []
test_namespace() # 接着调用函数 test_namespace()
print(a) # 显然由于函数内有变量 a 所以全局变量 a 没有被函数使用
# 稍微修改以下函数去掉函数内的变量 a,看看函数是否会读取全局变量 a
def test_namespace():
for i in range(10): # 遍历 range 对象
a.append(i) # 变量 a 追加元素
print('执行完成')
test_namespace() # 接着调用函数 test_namespace()
print(a) # 显然由于函数内没有变量 a 所以全局变量 a 被函数使用
若是需要让函数的本地命名空间作用域变大就需要使用关键字
global或nonlocal手动(显式)声明这些变量
# 代码例子
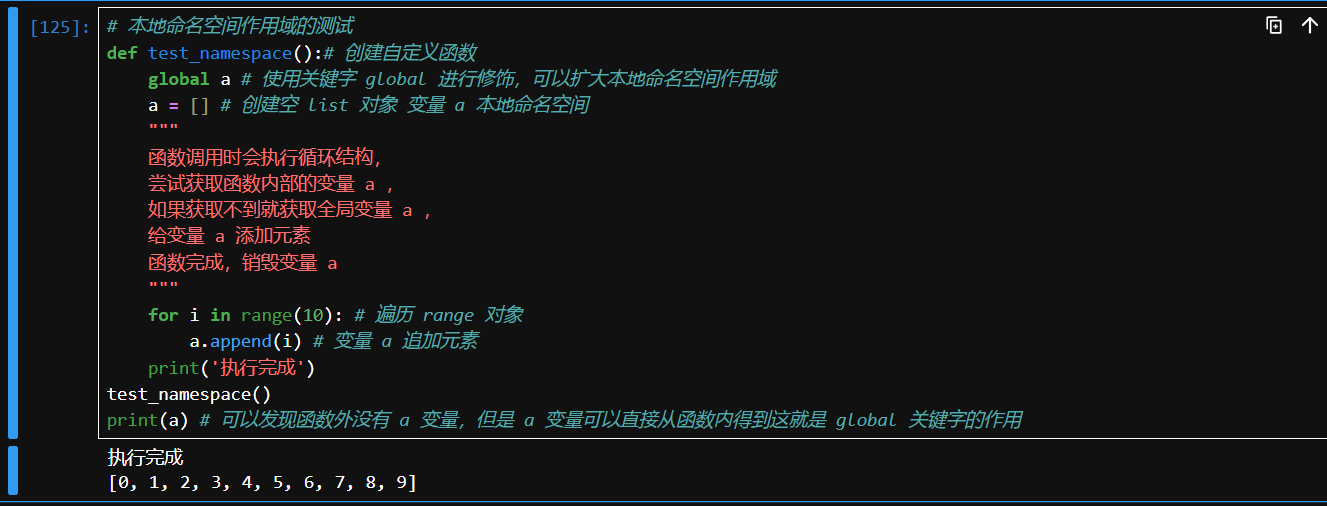
# 本地命名空间作用域的测试
def test_namespace():# 创建自定义函数
global a # 使用关键字 global 进行修饰,可以扩大本地命名空间作用域
a = [] # 创建空 list 对象 变量 a 本地命名空间
"""
函数调用时会执行循环结构,
尝试获取函数内部的变量 a ,
如果获取不到就获取全局变量 a ,
给变量 a 添加元素
函数完成,销毁变量 a
"""
for i in range(10): # 遍历 range 对象
a.append(i) # 变量 a 追加元素
print('执行完成')
test_namespace()
print(a) # 可以发现函数外没有 a 变量,但是 a 变量可以直接从函数内得到这就是 global 关键字的作用
Returning Multiple Values
返回多个值这个倒是没什么需要注意的地方,都练习过。
Functions Are Objects
函数是对象,嗯,一切皆对象
书中介绍了一种简单的清理字符串数据的例子,来证明函数具备对象行为,真是十分抽象
在练习这个代码前,需要了解新知识
import re
模块:re
作用:re模块是 Python 的正则表达式模块,它提供了一组函数,用于在字符串中搜索、匹配、替换和处理正则表达式。正则表达式是一种特殊的字符序列,可以有效地搜索和操作字符串。
re.sub函数正则表达式替换:
作用:re.sub(pattern, repl, string)函数用于在字符串string中查找所有匹配pattern的子串,并将其替换为repl。
str_obj.strip()字符串方法:
作用:str_obj.strip()方法用于移除字符串两端的空格和指定的字符(默认为空格)。例如,字符串" hello "经过strip()方法处理后,会变成"hello"
str_obj.title()字符串方法:
作用:str_obj.title()方法将字符串的每个单词的首字母转换为大写。比如,字符串"hello world"经过str_obj.title()方法处理后,会变成"Hello World"。了解了以上知识点就可以开始代码练习了
# 代码例子
import re
# 原始数据
books = [
" the great gatsby! ",
" To kill a Mockingbird# ",
"1984?",
" pride and prejudice! ",
" the catcher in the Rye "
]
print(books,type(books),id(books))
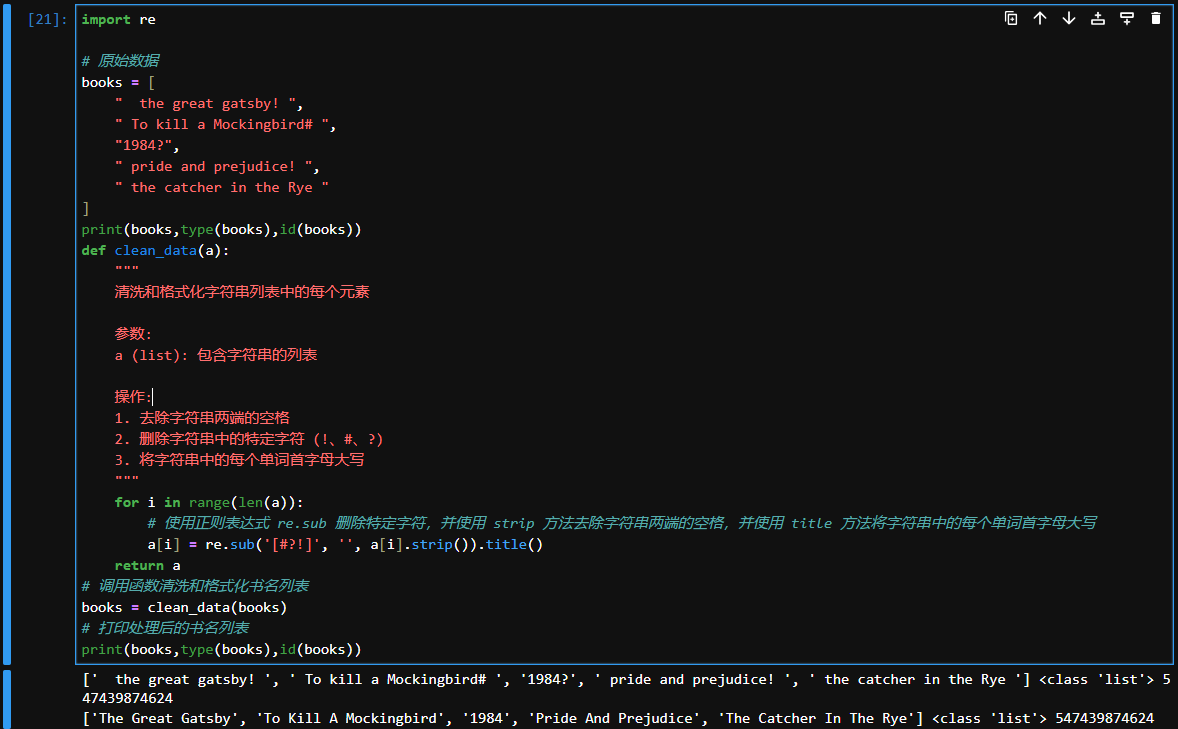
def clean_data(a):
"""
清洗和格式化字符串列表中的每个元素
参数:
a (list): 包含字符串的列表
操作:
1. 去除字符串两端的空格
2. 删除字符串中的特定字符 (!、#、?)
3. 将字符串中的每个单词首字母大写
"""
for i in range(len(a)):
# 使用正则表达式 re.sub 删除特定字符,并使用 strip 方法去除字符串两端的空格,并使用 title 方法将字符串中的每个单词首字母大写
a[i] = re.sub('[#?!]', '', a[i].strip()).title()
return a
# 调用函数清洗和格式化书名列表
books = clean_data(books)
# 打印处理后的书名列表
print(books,type(books),id(books))
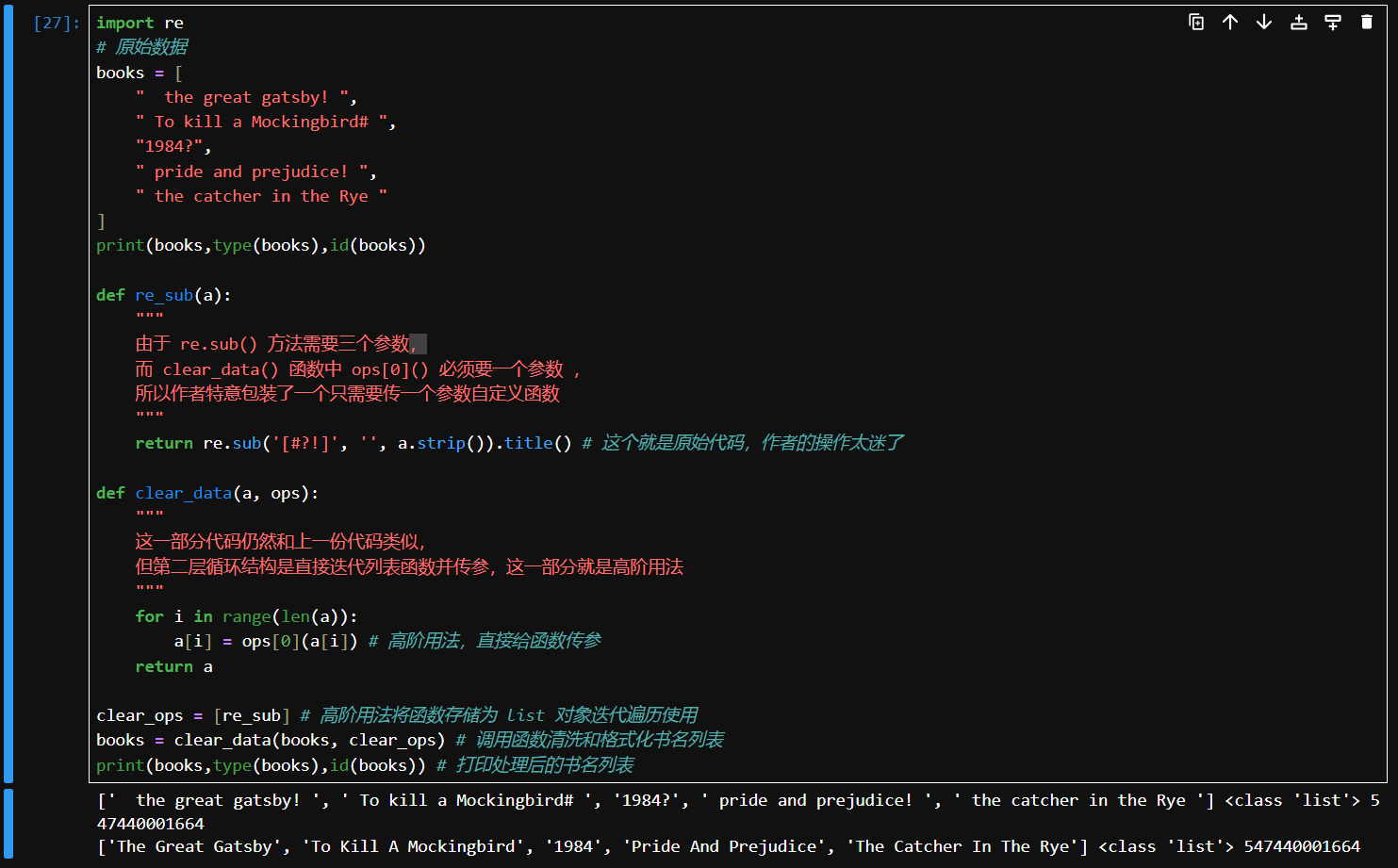
关于这个代码还有一个高阶使用,被作者秀了一脸,不仔细看根本无法理解
# 代码例子
import re
# 原始数据
books = [
" the great gatsby! ",
" To kill a Mockingbird# ",
"1984?",
" pride and prejudice! ",
" the catcher in the Rye "
]
print(books,type(books),id(books))
def re_sub(a):
"""
由于 re.sub() 方法需要三个参数,
而 clear_data() 函数中 ops[0]() 必须要一个参数 ,
所以作者特意包装了一个只需要传一个参数自定义函数
"""
return re.sub('[#?!]', '', a.strip()).title() # 这个就是原始代码,作者的操作太迷了
def clear_data(a, ops):
"""
这一部分代码仍然和上一份代码类似,
但第二层循环结构是直接迭代列表函数并传参,这一部分就是高阶用法
"""
for i in range(len(a)):
a[i] = ops[0](a[i]) # 高阶用法,直接给函数传参
return a
clear_ops = [re_sub] # 高阶用法将函数存储为 list 对象迭代遍历使用
books = clear_data(books, clear_ops) # 调用函数清洗和格式化书名列表
print(books,type(books),id(books)) # 打印处理后的书名列表
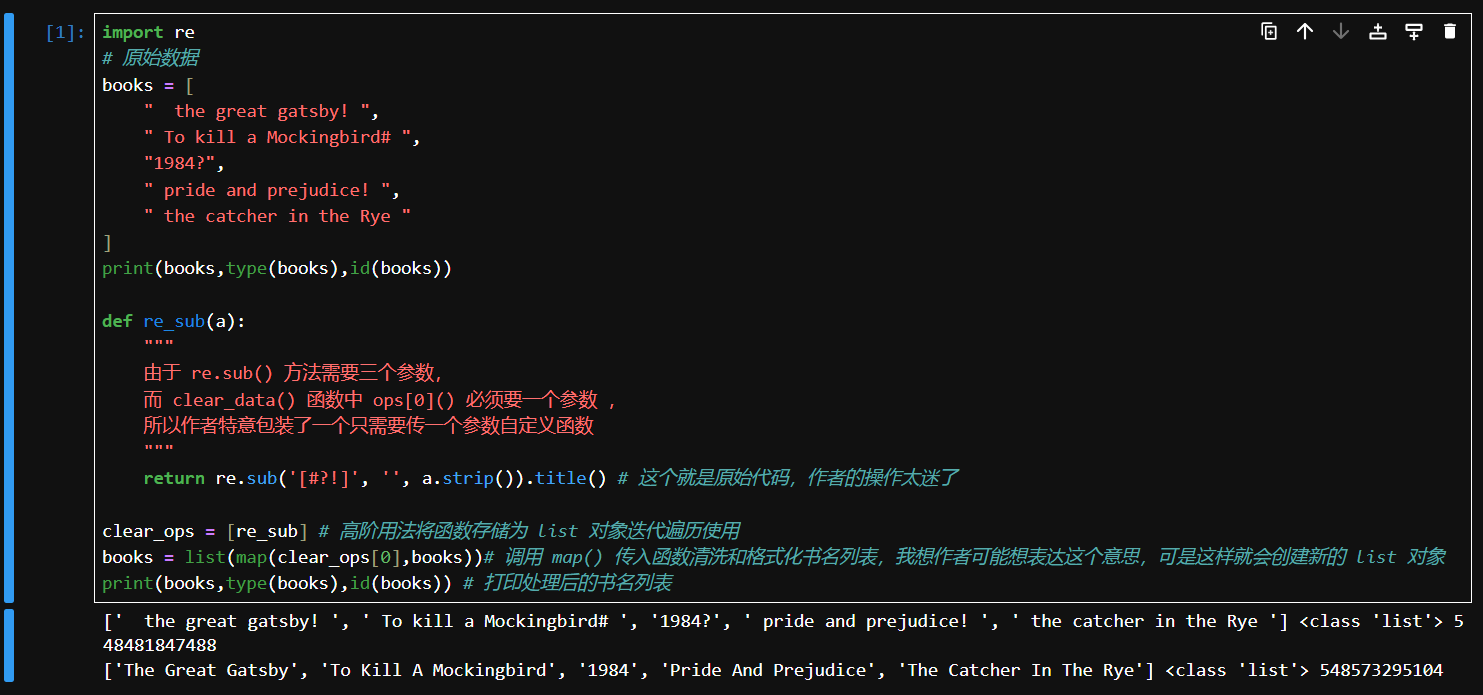
作者还提到可以使用
map(function,iterable)函数实现有意思的玩法
# 代码例子
import re
# 原始数据
books = [
" the great gatsby! ",
" To kill a Mockingbird# ",
"1984?",
" pride and prejudice! ",
" the catcher in the Rye "
]
print(books,type(books),id(books))
def re_sub(a):
"""
由于 re.sub() 方法需要三个参数,
而 clear_data() 函数中 ops[0]() 必须要一个参数 ,
所以作者特意包装了一个只需要传一个参数自定义函数
"""
return re.sub('[#?!]', '', a.strip()).title() # 这个就是原始代码,作者的操作太迷了
clear_ops = [re_sub] # 高阶用法将函数存储为 list 对象迭代遍历使用
books = list(map(clear_ops[0],books))# 调用 map() 传入函数清洗和格式化书名列表,我想作者可能想表达这个意思,可是这样就会创建新的 list 对象
print(books,type(books),id(books)) # 打印处理后的书名列表
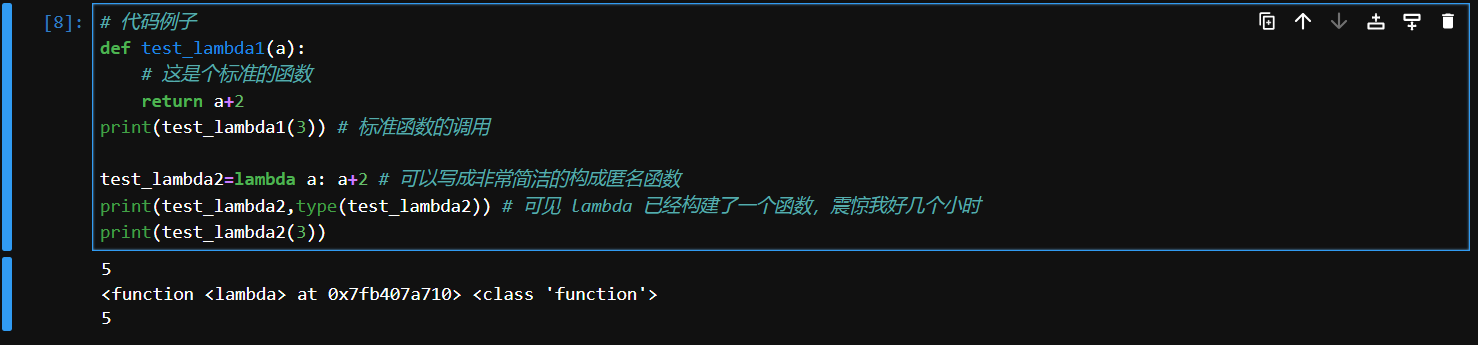
Anonymous (Lambda) Functions
匿名 lambda 函数,即单条语句就能构成函数且结果为返回值,用来声明匿名函数
其结构类似lambda 传参变量: 返回值表达式
# 代码例子
def test_lambda1(a):
# 这是个标准的函数
return a+2
print(test_lambda1(3)) # 标准函数的调用
test_lambda2=lambda a: a+2 # 可以写成非常简洁的构成匿名函数
print(test_lambda2,type(test_lambda2)) # 可见 lambda 已经构建了一个函数,震惊我好几个小时
print(test_lambda2(3))
书中作者还写了一个例子,这个例子似乎模拟了 map() 函数的功能
# 代码例子
# 模拟 map() 函数的功能
a = [1,2,3,4]
print(a,type(a),id(a))
def test_list_comprehensions(func,a): # 自定义一个需要传参变量为一个函数和一个可迭代对象的函数这功能类似 map()
return [func(i) for i in a] # 将可迭代对象通过 推导式 传入到函数中处理并返回
a = test_list_comprehensions(lambda x: x+1,a)# 将lambda匿名函数和可迭代对象传入到自定义函数
print(a,type(a),id(a))

作者还举例,将 lambda 匿名函数作为排序条件
# 代码例子
a = ['你好','abc','defg','h','ijkkk','qq','q!!!!','世界']
print(a,type(a),id(a))
a.sort() # 默认排序是升序
print(a,type(a),id(a))
a.sort(key=lambda x: len(x)) # 使用 lambda 匿名函数修改排序条件
print(a,type(a),id(a))

Generators
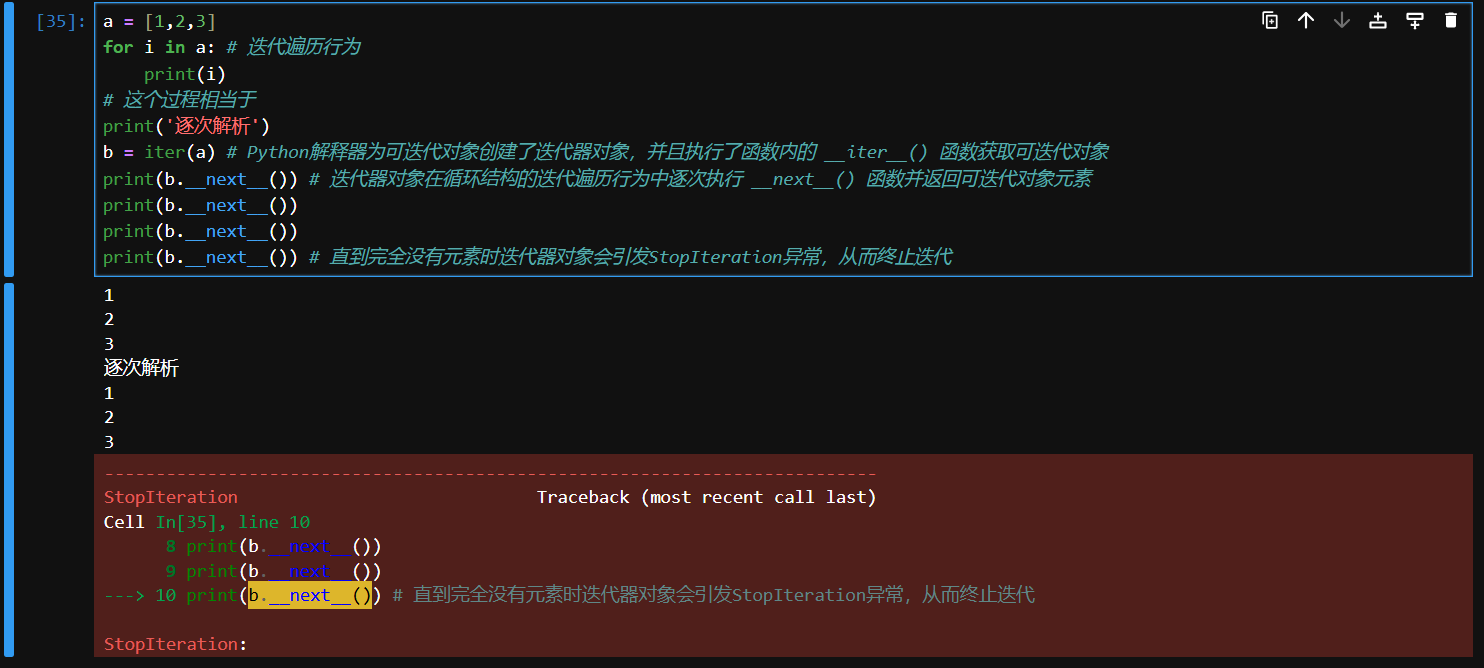
这一部分介绍的是生成器,但是要理解生成器就要理解什么是迭代器
许多对象都支持迭代,这意味着你可以逐个访问对象中的元素。
迭代的实现依赖于迭代器协议, 这是一套使对象能够被逐个访问的规则和方法
在某个迭代遍历可迭代对象的行为中,比如循环结构,
- Python解释器会为可迭代对象创建一个迭代器对象。
- 这个迭代器对象负责管理迭代。
- 每次循环时,迭代器对象返回下一个元素,直到没有更多元素为止。
# 代码例子
a = [1,2,3]
for i in a: # 迭代遍历行为
print(i)
# 这个过程相当于
print('逐次解析')
b = iter(a) # Python解释器为可迭代对象创建了迭代器对象,并且执行了函数内的 __iter__() 函数获取可迭代对象
print(b.__next__()) # 迭代器对象在循环结构的迭代遍历行为中逐次执行 __next__() 函数并返回可迭代对象元素
print(b.__next__())
print(b.__next__())
print(b.__next__()) # 直到完全没有元素时迭代器对象会引发StopIteration异常,从而终止迭代
在理解迭代器之后,紧接就是 生成器
生成器 是一种便捷的方法,用于创建一个新的可迭代对象
- 要创建生成器,需要在函数中使用
yield关键字,这个函数将会返回 generator 可迭代对象- 通过迭代遍历的行为请求 generator 可迭代对象中的元素,在每次执行时返回一个值并暂停,直到被再次调用时继续执行
- 这种机制使得生成器非常适合用于处理大量数据或流式数据,因为它们只在需要时才生成数据,而不需要一次性加载所有数据到内存中
# 代码例子
def test_yield(): # 自定义一个函数并通过 yield 存储对象此时的函数是个生成器返回 generator 对象
yield 1
yield 2
yield 3
a = test_yield()
print(a,type(a),id(a))
# 只有在请求生成器对象中的元素时,生成器才开始执行其代码
for i in a: # 通过迭代遍历行为让生成器对象将元素吐出来
print(i)

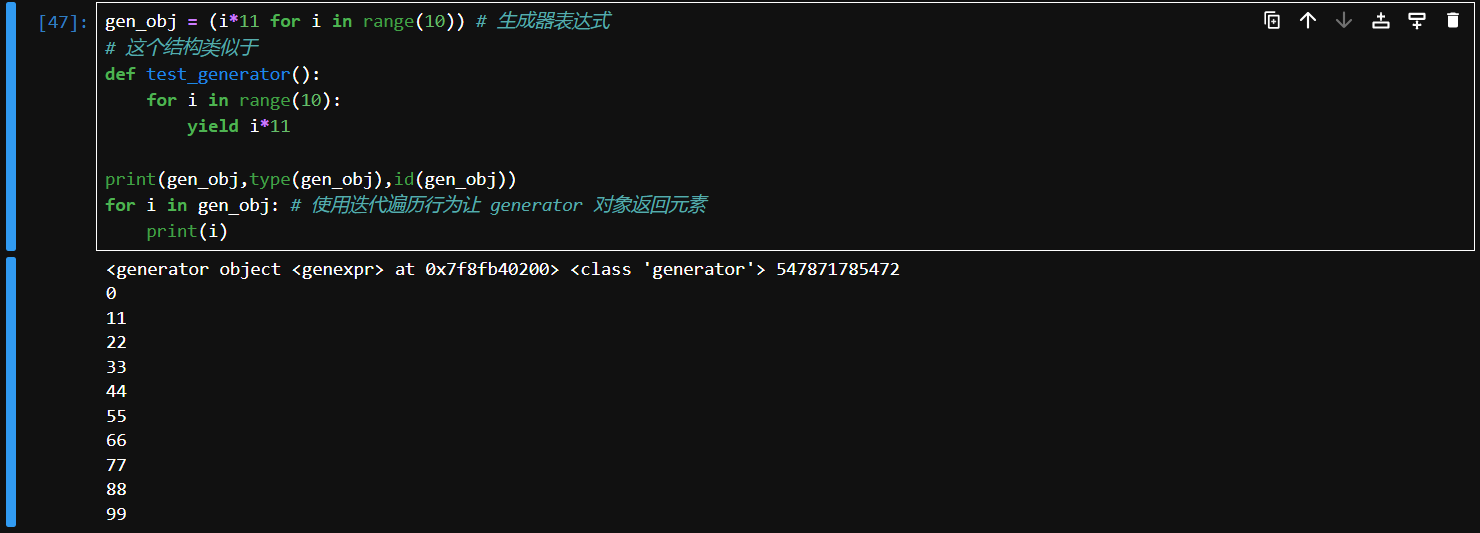
Generator expressions
与 list dict 和 set 推导式相似,生成器也有自己的表达式
生成器表达式结构如(表达式 for 元素 in 可迭代对象)
# 代码例子
gen_obj = (i*11 for i in range(10)) # 生成器表达式
# 这个结构类似于
def test_generator():
for i in range(10):
yield i*11
print(gen_obj,type(gen_obj),id(gen_obj))
for i in gen_obj: # 使用迭代遍历行为让 generator 对象返回元素
print(i)
itertools module
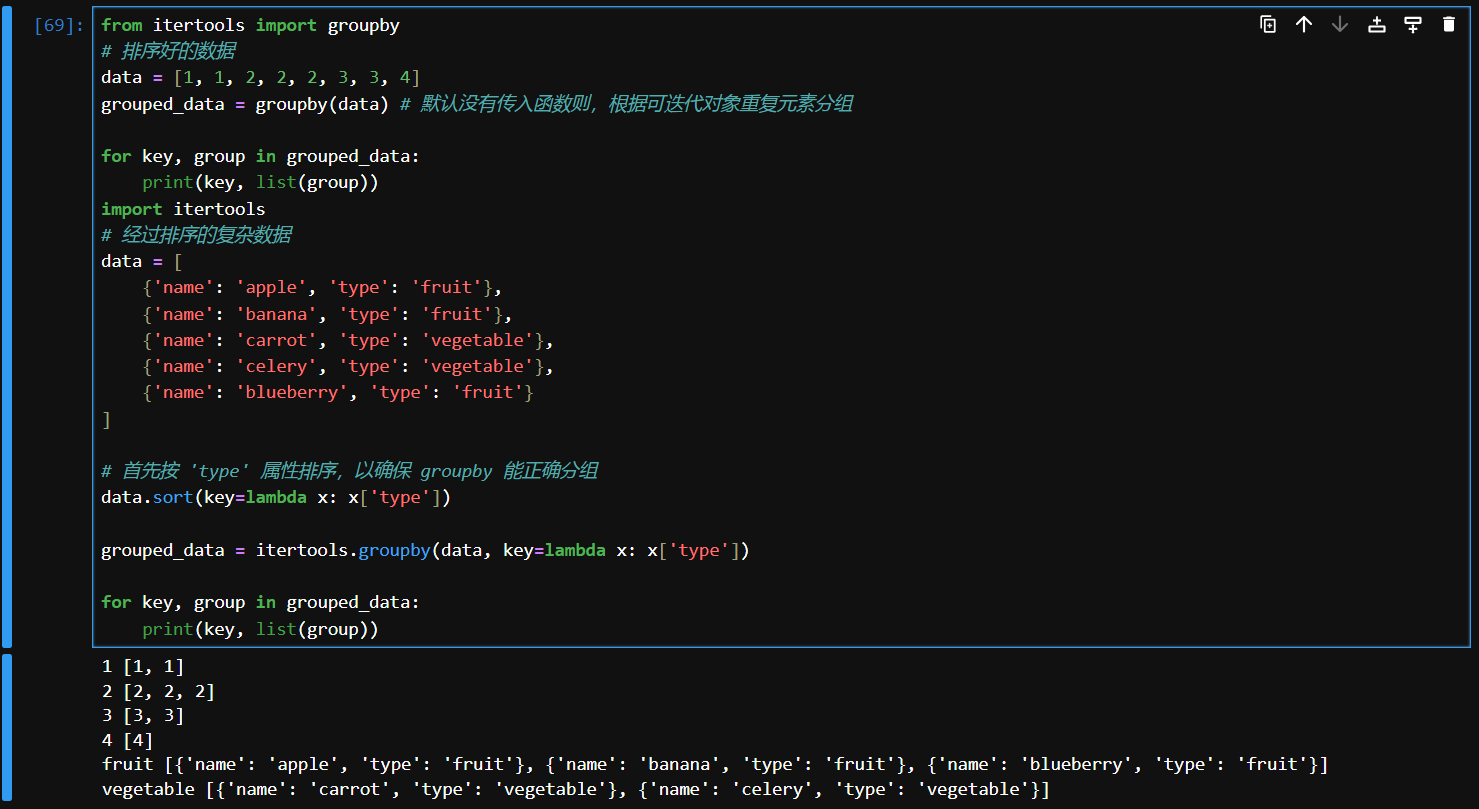
书里介绍了一个标准库
itertools其中有一个itertools.groupby(iterable,function)可以接收一个可迭代对象和一个函数用来处理可迭代对象并按照函数返回的参数进行分组
- 排序:使用
groupby()之前,通常需要对数据进行排序,因为groupby()只会对连续相同的元素进行分组。- 惰性操作:
groupby()是一个惰性操作,它只在你遍历分组时才会处理数据。
# 代码例子
from itertools import groupby
# 排序好的数据
data = [1, 1, 2, 2, 2, 3, 3, 4]
grouped_data = groupby(data) # 默认没有传入函数则,根据可迭代对象重复元素分组
for key, group in grouped_data:
print(key, list(group))
import itertools
# 经过排序的复杂数据
data = [
{'name': 'apple', 'type': 'fruit'},
{'name': 'banana', 'type': 'fruit'},
{'name': 'carrot', 'type': 'vegetable'},
{'name': 'celery', 'type': 'vegetable'},
{'name': 'blueberry', 'type': 'fruit'}
]
# 首先按 'type' 属性排序,以确保 groupby 能正确分组
data.sort(key=lambda x: x['type'])
grouped_data = itertools.groupby(data, key=lambda x: x['type'])
for key, group in grouped_data:
print(key, list(group))
Errors and Exception Handling
代码运行的过程难免会有错误和异常,为了让程序在遇到错误时不崩溃,可以使用
try/except语句。
通过在try块中包裹可能引发异常的代码,我们可以在except块中处理这些异常。
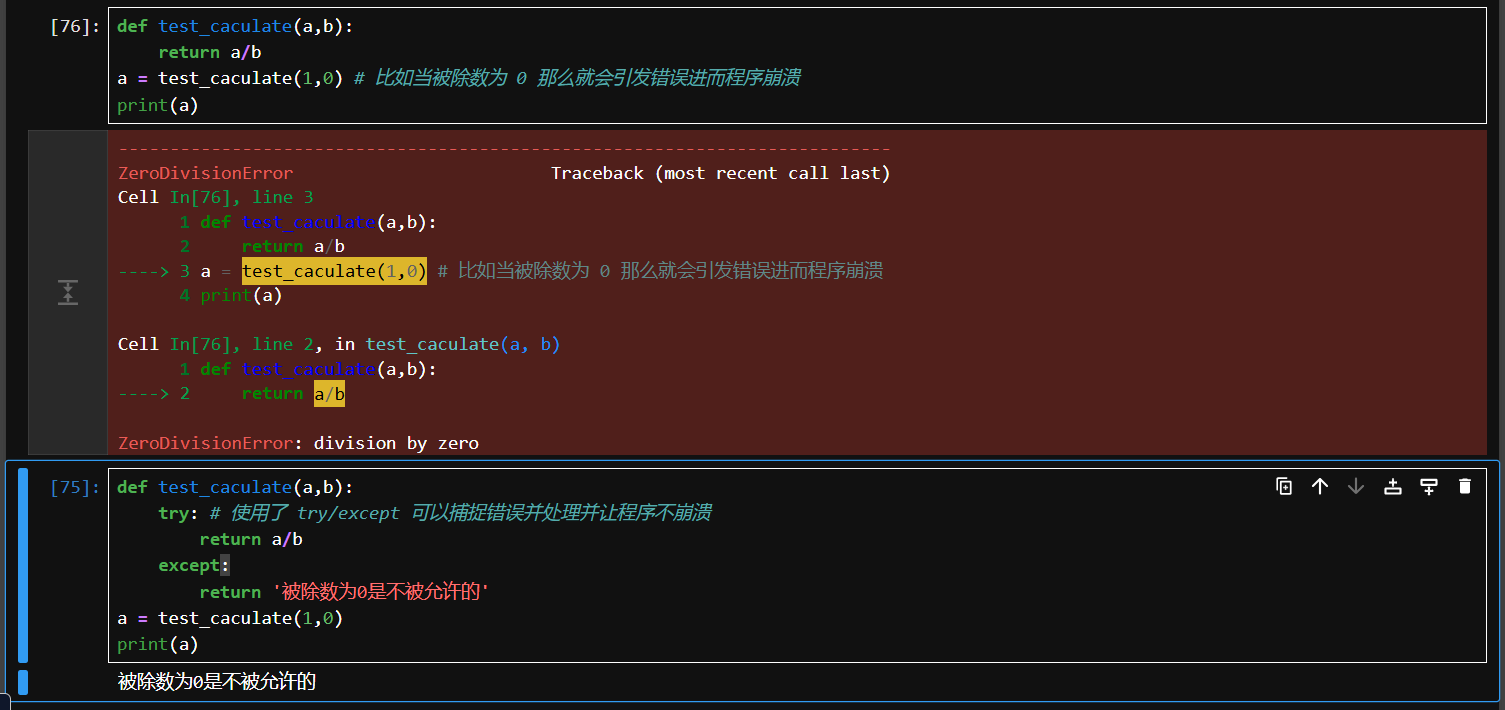
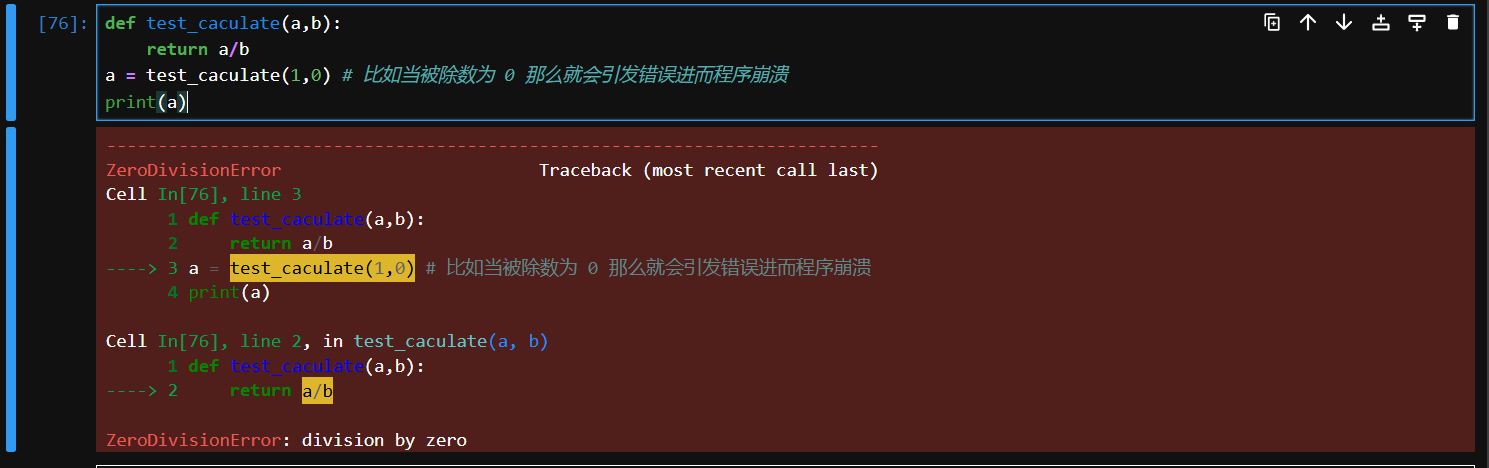
# 错误的代码例子
def test_caculate(a,b):
return a/b
a = test_caculate(1,0) # 比如当被除数为 0 那么就会引发错误进而程序崩溃
print(a)
# 捕获异常代码例子
def test_caculate(a,b):
try: # 使用了 try/except 可以捕捉错误并处理并让程序不崩溃
return a/b
except:
return '被除数为0是不被允许的'
a = test_caculate(1,0)
print(a)
接下来是捕获特定的异常,为了只捕获特定类型的异常,可以在
except后面指定异常类型。
def test_caculate(a,b):
try: # 使用了 try/except 可以捕捉错误并处理并让程序不崩溃
return a/b
except TypeError:
return '错误的类型',b
a = test_caculate(1,'0')
print(a)

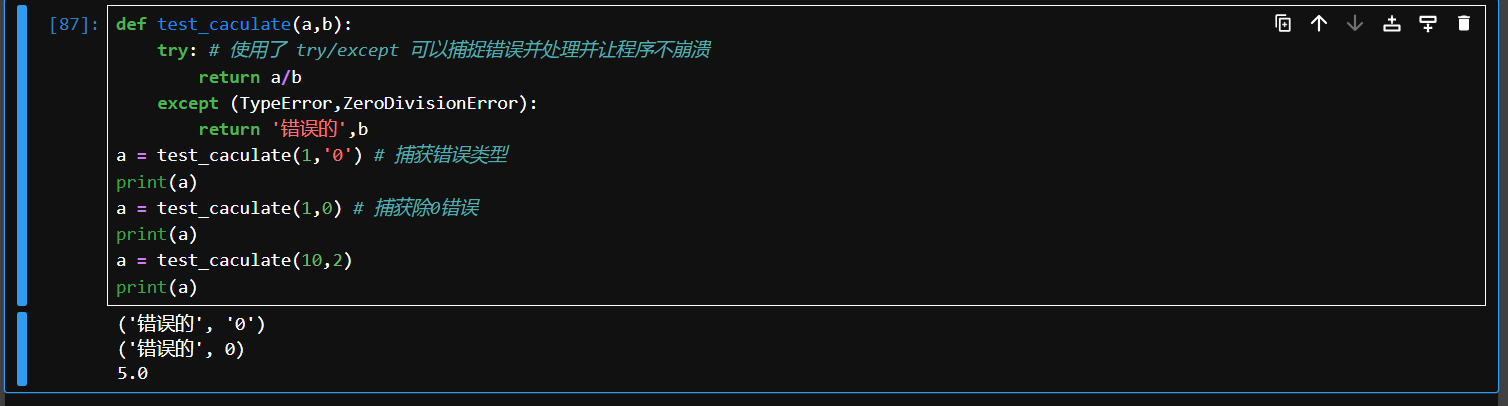
通过传递一个异常类型的元组来捕获多个类型的异常
def test_caculate(a,b):
try: # 使用了 try/except 可以捕捉错误并处理并让程序不崩溃
return a/b
except (TypeError,ZeroDivisionError):
return '错误的',b
a = test_caculate(1,'0') # 捕获错误类型
print(a)
a = test_caculate(1,0) # 捕获除0错误
print(a)
a = test_caculate(10,2)
print(a)
有时希望在不论代码是否成功执行的情况下,都执行一些工作。可以使用
finally语句
# 代码例子
def test_caculate(a,b):
try: # 使用了 try/except 可以捕捉错误并处理并让程序不崩溃
return a/b
except (TypeError,ZeroDivisionError):
return '错误的',b
finally:
print('无论对错,我都执行')
a = test_caculate(1,'0') # 捕获错误类型
print(a)
a = test_caculate(1,0) # 捕获除0错误
print(a)
a = test_caculate(10,2)
print(a)

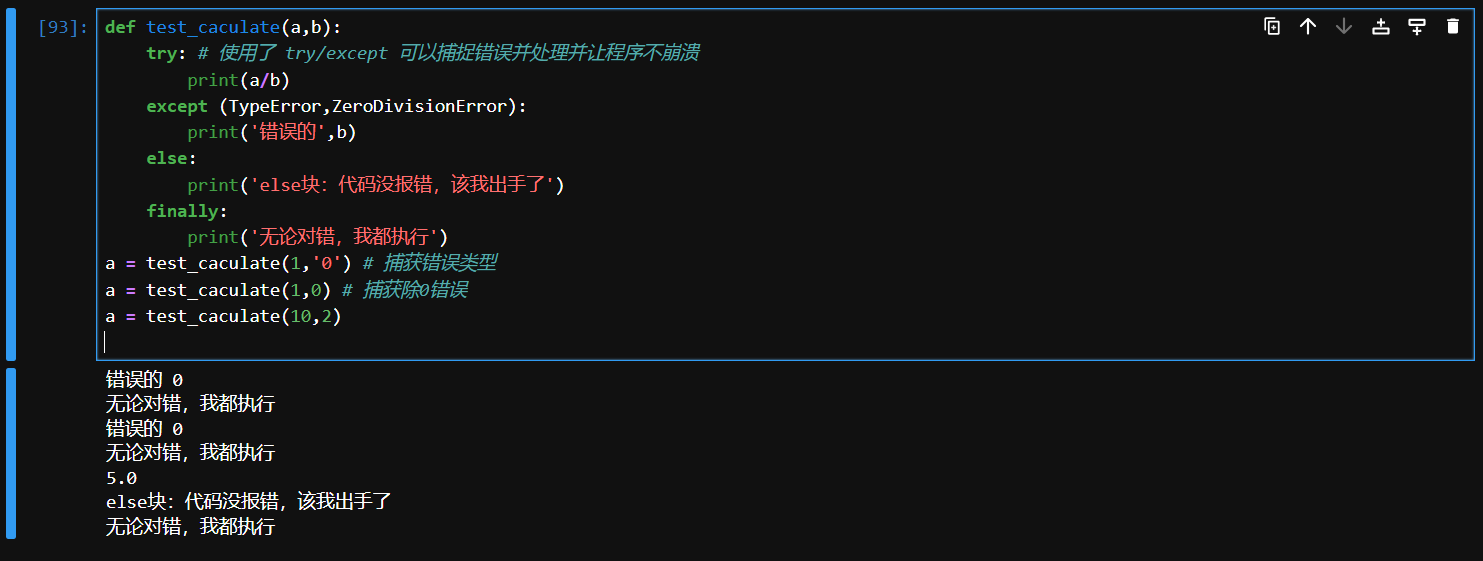
else语句用于指定在try块成功执行且未引发任何异常时执行的代码。
# 代码例子
def test_caculate(a,b):
try: # 使用了 try/except 可以捕捉错误并处理并让程序不崩溃
print(a/b)
except (TypeError,ZeroDivisionError):
print('错误的',b)
else:
print('else块:代码没报错,该我出手了')
finally:
print('无论对错,我都执行')
a = test_caculate(1,'0') # 捕获错误类型
a = test_caculate(1,0) # 捕获除0错误
a = test_caculate(10,2)
Exceptions in IPython
和 Python 解释器相比 IPython 解释器可以提供更多的错误打印信息
使用%run命令执行脚本或执行任何语句时,如果出现异常,IPython 默认会打印出完整的调用堆栈追踪(traceback),这个在以 IPython 解释器为内核的 notebook 中学习捕获异常的时候有所体现
可以使用%xmode魔法命令来控制显示的上下文信息量。例如:
Plain模式:显示与标准 Python 解释器相同的基本信息。Verbose模式:显示更详细的信息,包括函数参数值等。
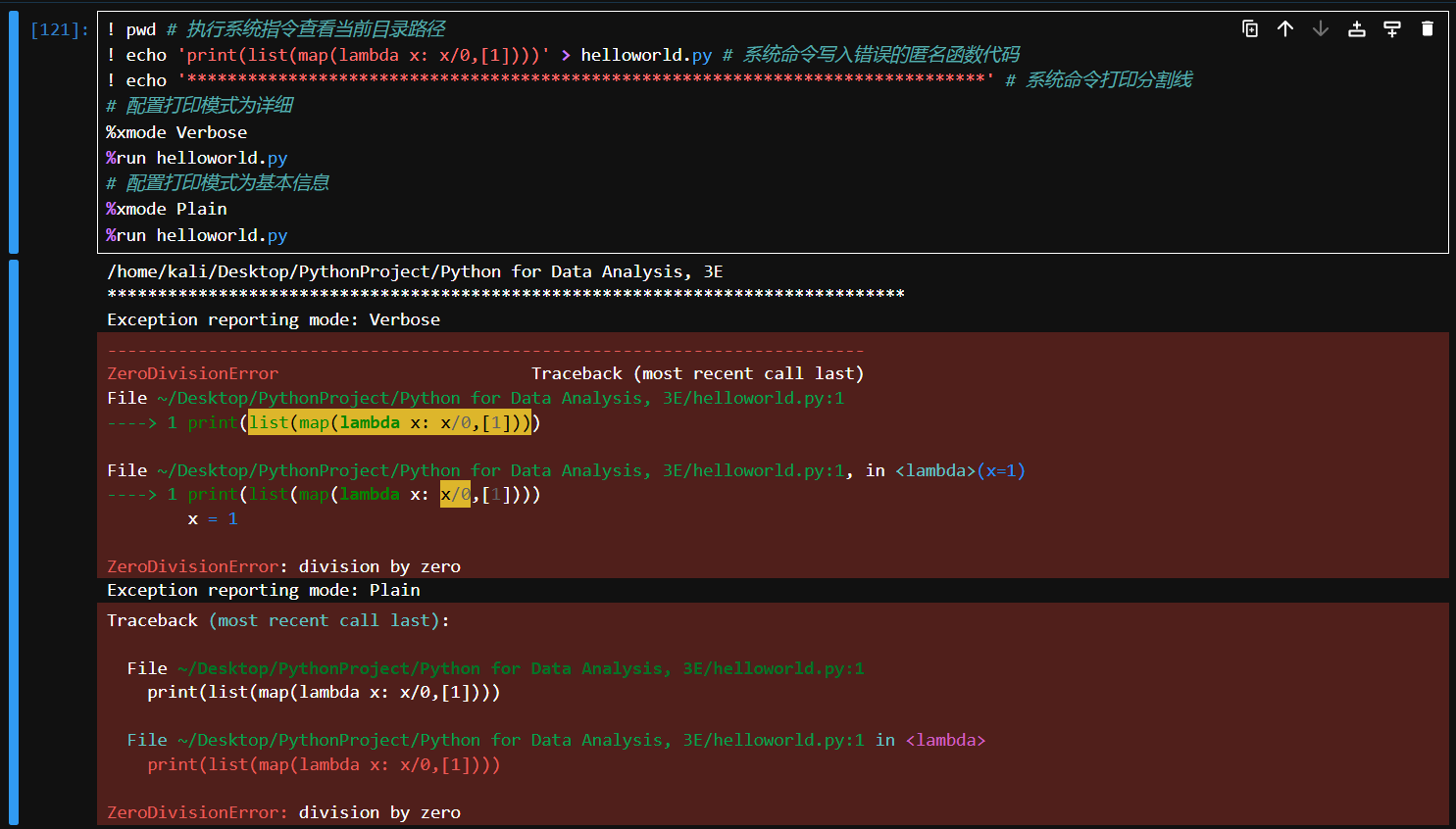
# 代码例子
! pwd # 执行系统指令查看当前目录路径
! echo 'print(list(map(lambda x: x/0,[1])))' > helloworld.py # 系统命令写入错误的匿名函数代码
! echo '*******************************************************************************' # 系统命令打印分割线
# 配置打印模式为详细
%xmode Verbose
%run helloworld.py
# 配置打印模式为基本信息
%xmode Plain
%run helloworld.py
IPython 提供了一些调试工具,比如
%debug和%pdb魔法命令,可以在发生错误后进行交互式的事后调试(postmortem debugging)
Files and the Operating System
书中介绍了基本的文件操作,作为高级文件操作的基础,使用内置的
open(file=文件路径,encoding=编码格式, mode=模式)函数,返回一个可迭代的 TextIOWrapper 文件对象
file=可以指定相对或绝对文件路径
使用encoding=可选的文件编码。是为了保证文件编码的一致性,不同平台的默认编码可能不同
默认文件以只读模式"r"打开,即mode="r"。可以将文件对象当作 list 对象一样进行迭代。
- 文件读写模式:
r:只读模式w:写入模式,创建新文件(覆盖现有文件)x:写入模式,创建新文件,如果文件已存在则失败a:追加模式(如果文件不存在则创建)r+:读写模式b:二进制模式(例如"rb"或"wb")t:文本模式(默认)读取文件中的每一行时,行末的换行符(EOL)标记会保留,可以用
str_obj.rstrip()去除
rstrip()和strip()是字符串方法,用于去除字符串中的空白字符或其他指定字符。它们的区别在于去除字符的位置不同。以下是详细的解释:
rstrip()- 功能:
rstrip()方法用于删除字符串末尾的空白字符或指定字符。- 用法:
string.rstrip([chars])
chars是一个可选参数,指定要去除的字符集。如果不提供chars参数,则默认去除空白字符(包括空格、制表符、换行符等)。- 区别总结
rstrip():仅删除字符串末尾的空白字符或指定字符。strip():删除字符串开头和末尾的空白字符或指定字符。
使用
open创建文件对象后,在使用完毕后文件对象.close()关闭文件,以释放系统资源。
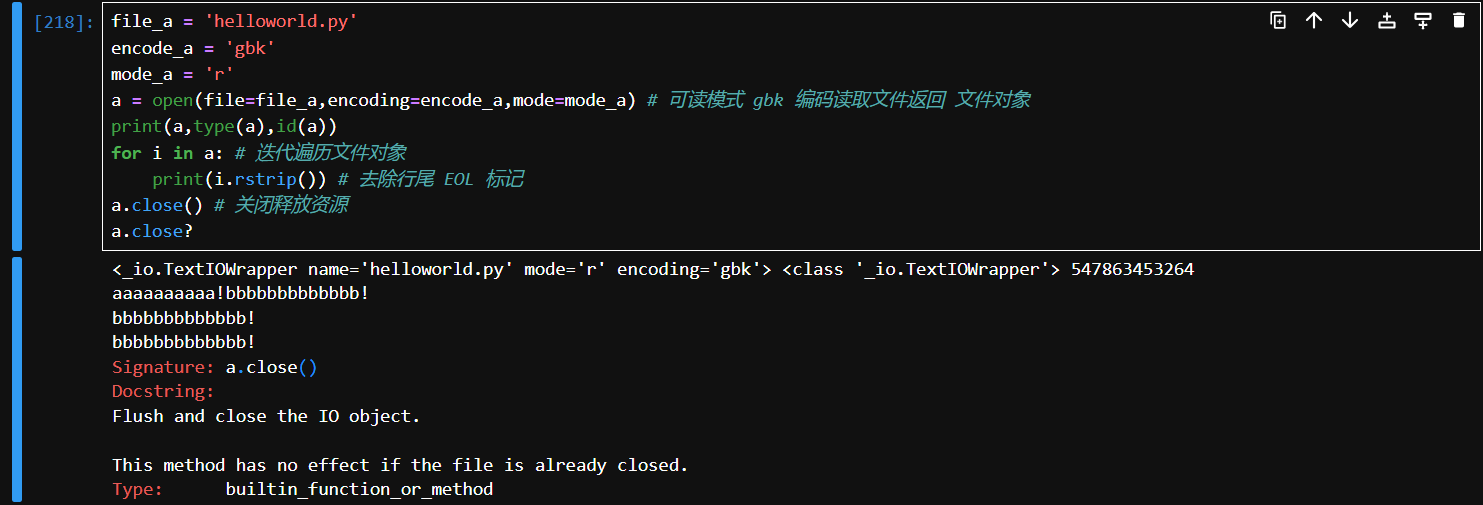
# 代码例子
file_a = 'helloworld.py'
encode_a = 'gbk'
mode_a = 'r'
a = open(file=file_a,encoding=encode_a,mode=mode_a) # 可读模式 gbk 编码读取文件返回 文件对象
print(a,type(a),id(a))
for i in a: # 迭代遍历文件对象
print(i.rstrip()) # 去除行尾 EOL 标记
a.close() # 关闭释放资源
a.close?
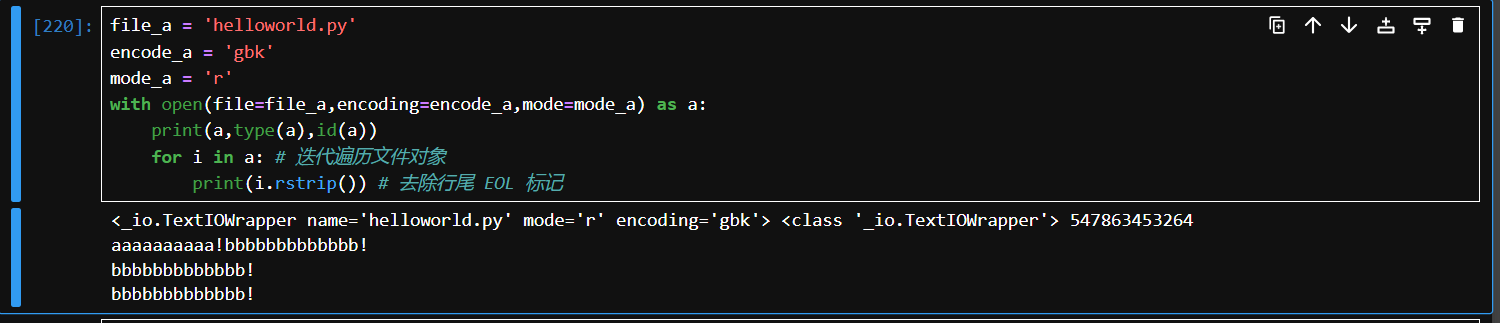
文件读取还可以通过使用
with语句可以更方便地管理文件关闭操作,它会在代码块结束时自动关闭文件。
# 代码例子
file_a = 'helloworld.py'
encode_a = 'gbk'
mode_a = 'r'
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
print(a,type(a),id(a))
for i in a: # 迭代遍历文件对象
print(i.rstrip()) # 去除行尾 EOL 标记
可以通过标准库
sys的sys.getdefaultencoding()方法获取当前系统默认字符编码环境
# 代码例子
# import sys
# sys.*default*?
from sys import getdefaultencoding
print(getdefaultencoding())

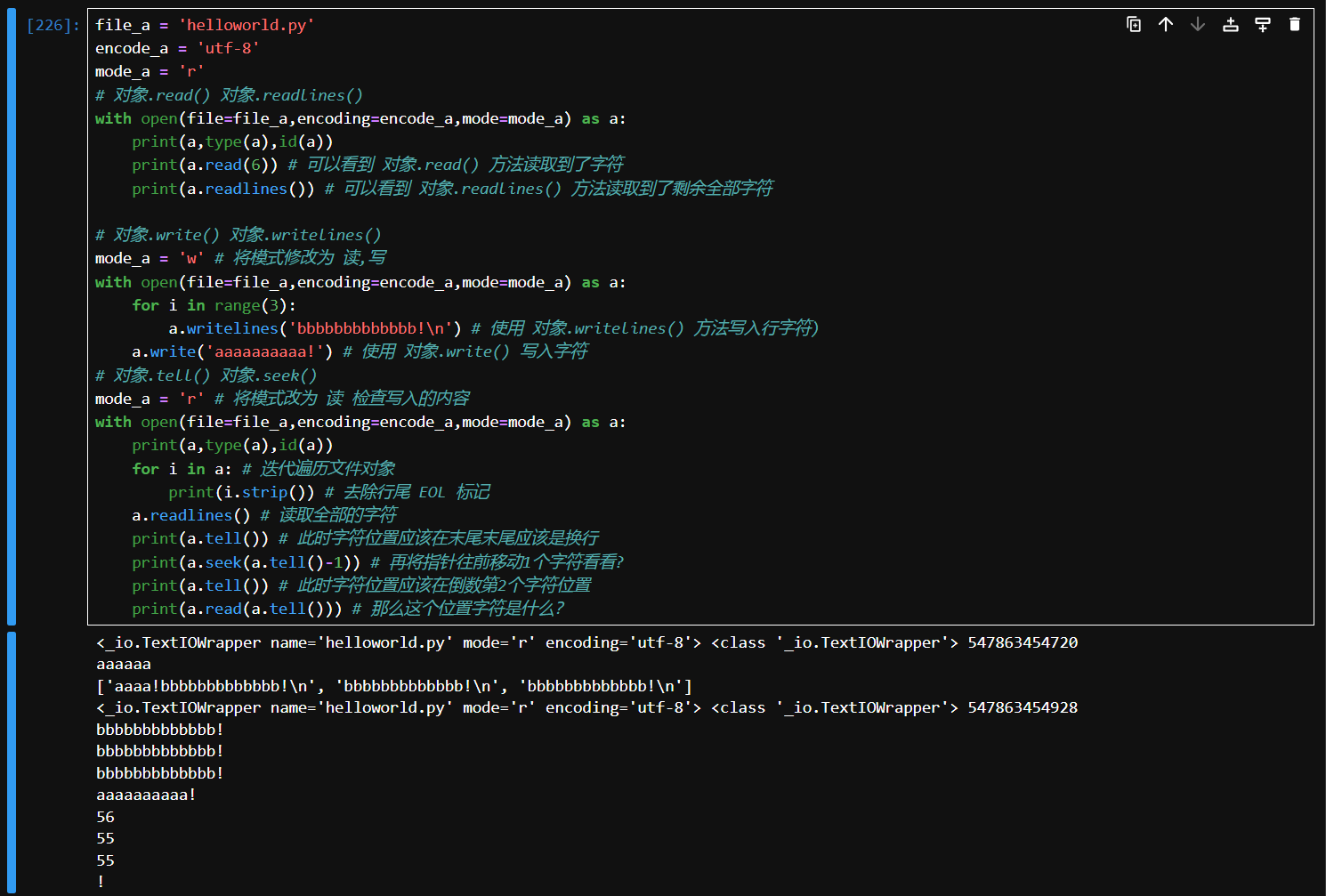
文件对象的方法:
- 使用
对象.read()方法以字符方式读取返回 str 对象对象.readlines()方法能读取整个文件。返回 list 对象- 使用
对象.write()方法以字符方式写入对象.writelines()方法以可迭代对象的方式写入文本。对象.tell()方法返回当前文件指针的位置。返回数字对象对象.seek()方法更改文件指针位置。返回数字对象
# 代码例子
file_a = 'helloworld.py'
encode_a = 'utf-8'
mode_a = 'r'
# 对象.read() 对象.readlines()
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
print(a,type(a),id(a))
print(a.read(6)) # 可以看到 对象.read() 方法读取到了字符
print(a.readlines()) # 可以看到 对象.readlines() 方法读取到了剩余全部字符
# 对象.write() 对象.writelines()
mode_a = 'w' # 将模式修改为 读,写
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
for i in range(3):
a.writelines('bbbbbbbbbbbbb!\n') # 使用 对象.writelines() 方法写入行字符)
a.write('aaaaaaaaaa!') # 使用 对象.write() 写入字符
# 对象.tell() 对象.seek()
mode_a = 'r' # 将模式改为 读 检查写入的内容
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
print(a,type(a),id(a))
for i in a: # 迭代遍历文件对象
print(i.strip()) # 去除行尾 EOL 标记
a.readlines() # 读取全部的字符
print(a.tell()) # 此时字符位置应该在末尾末尾应该是换行
print(a.seek(a.tell()-1)) # 再将指针往前移动1个字符看看?
print(a.tell()) # 此时字符位置应该在倒数第2个字符位置
print(a.read(a.tell())) # 那么这个位置字符是什么?
Bytes and Unicode with Files
接下来主要讨论了在 Python 中处理字节和 Unicode 编码文件的基础知识
默认情况下,Python 文件(无论是可读还是可写)都是以文本模式打开的,这意味着你将处理 Python 字符串(即 Unicode)
# 代码例子
file_a = 'helloworld.py'
encode_a = 'utf-8'
mode_a = 'r'
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
print(a,type(a),id(a))
print(a.readlines())

如果想以二进制模式打开文件,可以在文件模式中添加
b。这种模式下,读取请求将返回确切数量的字节返回 BufferedReader 文件对象
如果需要处理字节数据,可以使用二进制模式,例如"rb"。
※ 注意如果使用 二进制 读取就不要传入 编码格式 会报错的
# 代码例子
file_a = 'helloworld.py'
mode_a = 'rb'
with open(file=file_a,mode="rb") as a:
print(a,type(a),id(a))
print(a.readlines())

当以文本模式打开文件时使用
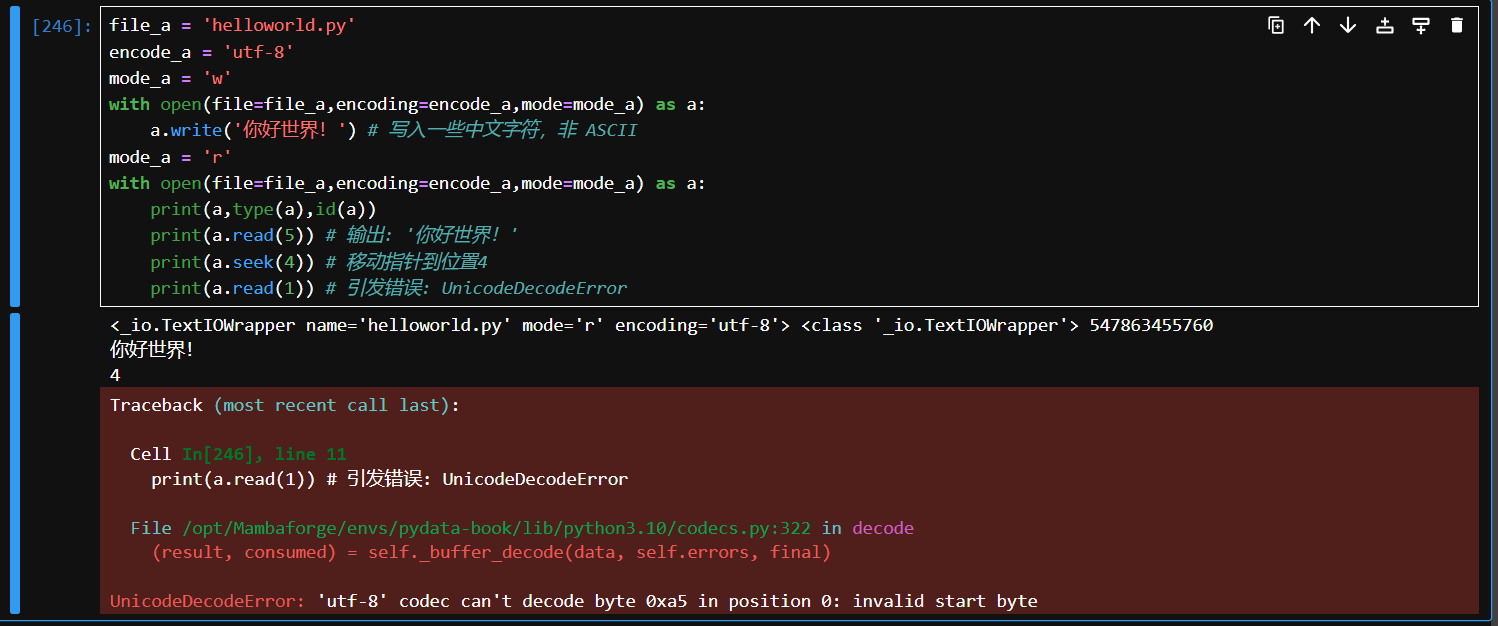
seek需要小心,对于常见的 ASCII 字符(如英文字符和数字),只使用 1 个字节来表示,所以如果文件中包含非 ASCII 字符,则一个字符可能会占用多个字节,如果文件指针位置落在一个 Unicode 字符的字节定义中间,随后的读取将会导致错误。
# 代码例子
file_a = 'helloworld.py'
encode_a = 'utf-8'
mode_a = 'w'
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
a.write('你好世界!') # 写入一些中文字符,非 ASCII
mode_a = 'r'
with open(file=file_a,encoding=encode_a,mode=mode_a) as a:
print(a,type(a),id(a))
print(a.read(5)) # 输出: '你好世界!'
print(a.seek(4)) # 移动指针到位置4
print(a.read(1)) # 引发错误: UnicodeDecodeError
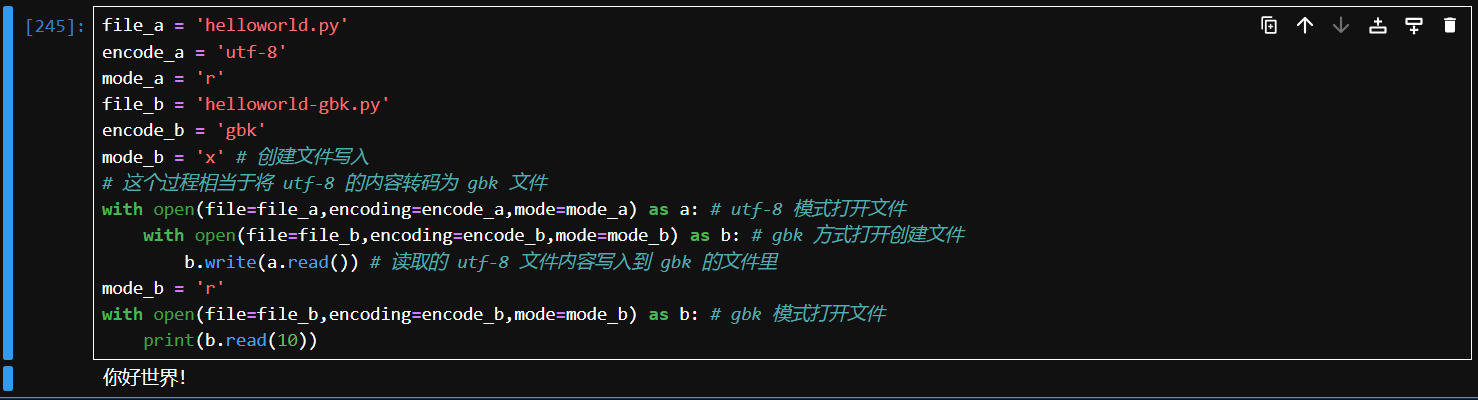
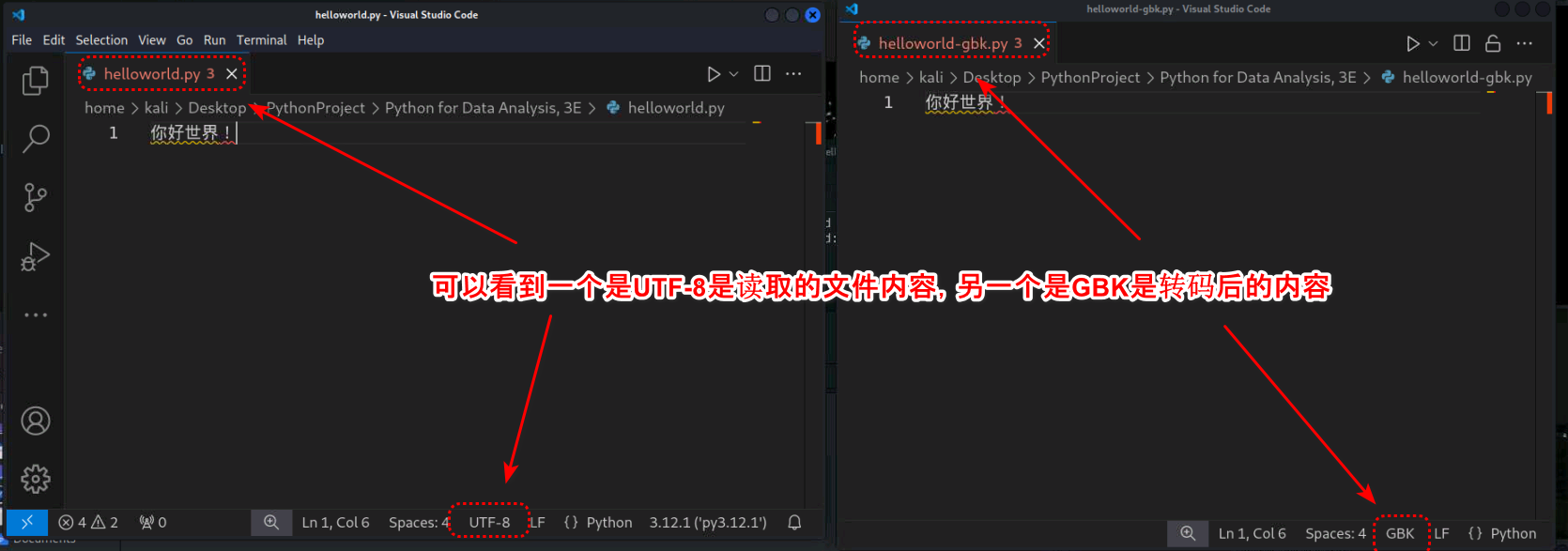
书里介绍了一种嵌套读写的方法可以将一个编码格式的文本文件转为另一种编码格式的文本文件
# 代码例子
file_a = 'helloworld.py'
encode_a = 'utf-8'
mode_a = 'r'
file_b = 'helloworld-gbk.py'
encode_b = 'gbk'
mode_b = 'x' # 创建文件写入
# 这个过程相当于将 utf-8 的内容转码为 gbk 文件
with open(file=file_a,encoding=encode_a,mode=mode_a) as a: # utf-8 模式打开文件
with open(file=file_b,encoding=encode_b,mode=mode_b) as b: # gbk 方式打开创建文件
b.write(a.read()) # 读取的 utf-8 文件内容写入到 gbk 的文件里
mode_b = 'r'
with open(file=file_b,encoding=encode_b,mode=mode_b) as b: # gbk 模式打开文件
print(b.read(10))