
2 个赞
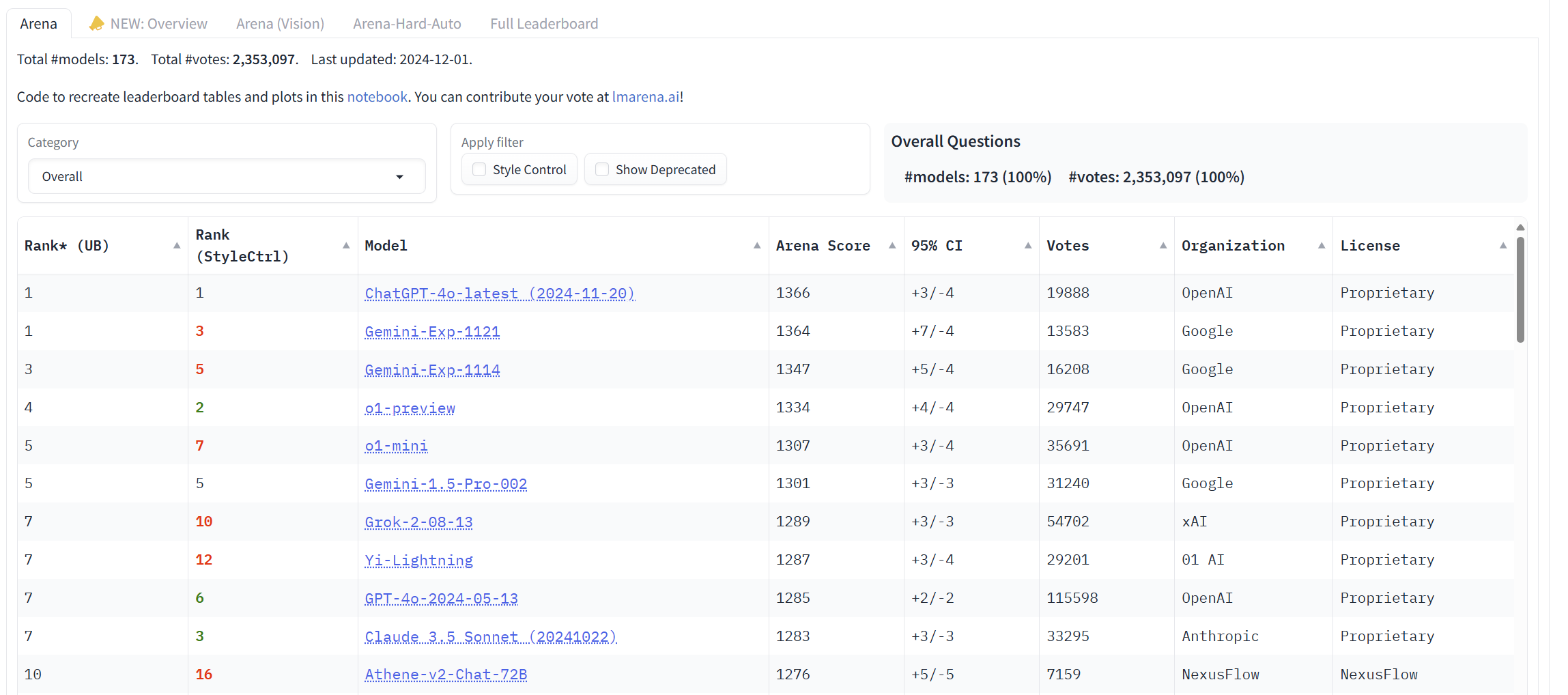
都快被刷成野榜了。。。c3.5都进不去前五
2 个赞
甚至快跌出前十
我觉得就是给钱榜了
一方面可能是刷钱/背题了,还有一方面是人类偏好对齐虽然能提分,但是人的判断(普通人非专业专项的人)对于大模型的提升变得更小了,感觉和翁荔离职后写的第一篇关于RLHF的文章探讨的奖励黑洞差不多,现在这种大众打分站来评估的准确性感觉不咋行了。以后大模型的评测要依赖专业化了,而不是这种大众点评似的评估了。
还是算了吧。。
克劳德现在网页版就是弱智,gemini编程也差,同样的问题最终是chatgpt解决.第一也当之无愧
大众评估其实不太能展示模型的专业能力,从几个角度考虑:
1、很少有人会在竞技场使用专业问题进行评估
2、很少有人能够评判答案的好坏(这是一个很惨酷的事实)
另外对于非客观的问题结果,人们还是喜欢当昏君的,哪怕有去除样式的排行也无法去除人类对模型输出的喜好,说好话的奸佞比简短批判的忠臣更容易获得好评。
之前gpt4omini排名比c3.5s高的时候大家就分析过,4omini更倾向于顺着用户言论,c3.5s则输出更多消极内容。
所以,网页用户测试投票的这种评估不能全面反应模型能力。但是lmsys有一个评估还是比较靠谱的,插件代码评估,因为那个是客观的,代码能不能跑很现实
1 个赞
看这个榜要勾上style control,你会发现sonnet是第3
然后再在category里选hard prompt,sonnet是仅次于o1-preview
style control说白了就是人类会偏好各种花里胡哨的格式比如markdown之类,很多模型会投其所好,而sonnet不喜欢用这些格式所以吃亏。style control就是排除掉这些偏好的因素。
2 个赞

应该是pro用户吧?普号估计都给干成haiku了![]()
确实,感觉说人类偏好对齐对模型提升和性能判断很有限这点确实有点武断,因为style control也算是偏好对齐的一部分吧 ![]()
c3.5也就写代码和文科强,其他理科和工科的题目很少能做对(英文问、公式用latex、结构化prompt、cot)。gemini和o1、gpt4o就做得出来
所以不要用自己平时问的问题去假定所有测试的人会问的问题。别人问的方向可能你没试过
1 个赞
确实,可能平时关注的方面更集中在代码方面吧。文笔latest一直很不错,claude反而还怪怪的,也可能是我打开方式不对 ![]() 。
。
很好奇这方面佬有哪些测试和见解呢,案例能分享不。
我的各科作业![]()
有具体的吗 ![]() 比如某些具体的测试,表现不佳或者不如其他模型体现在哪些方面呢,很好奇
比如某些具体的测试,表现不佳或者不如其他模型体现在哪些方面呢,很好奇 ![]()
电子信息或者计算机专业的基础课和专业课,除了代码相关的,其他课c3.5都不如gemini和4o,不管是做题还是教学。(o1就不用比了)
比较冷门的编程语言4o也比c3.5要好
具体表现就是题做不对,教我的话会有很多幻觉
题我现在不方便贴出来。你可以自己网上找、转成英文latex去问claude更有说服力
2 个赞
接着血流成河 ![]()

