前文提要:
https://linux.do/t/topic/290200
https://linux.do/t/topic/294680
(\ _ /)
( ・-・)
/っ ![]() 用的 15 年前流行的 PHP+MySQL,为什么不用最新世代的可以语义查询的向量数据库?这是我 $18/年 的老鸡配置:
用的 15 年前流行的 PHP+MySQL,为什么不用最新世代的可以语义查询的向量数据库?这是我 $18/年 的老鸡配置:
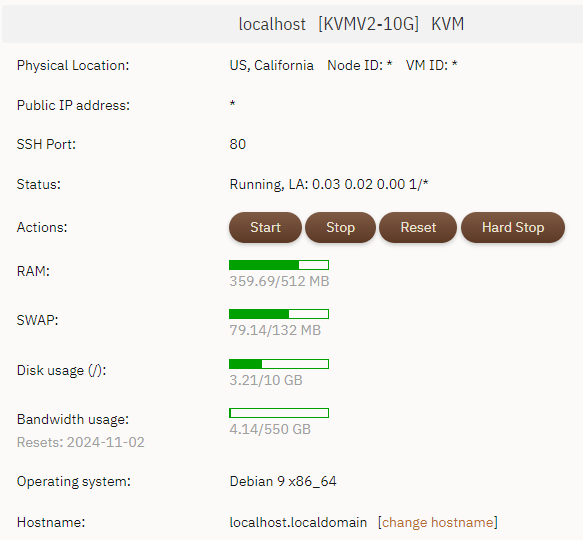
部署 OpenWebUI 我都不敢想。
目前只是少量数据,601 个音频转录之后是 50+ 万字。

使用的就是最初的构想:
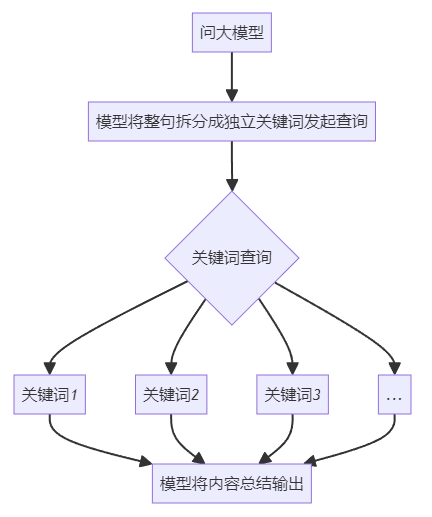
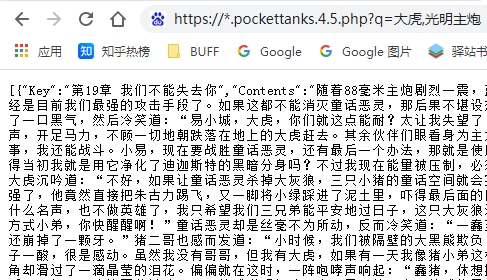
效果:
(极其冷门的数据,网上必然没有,连原本小说都没有想 OCR 都不行,唯一渠道就是充 KFC 早餐会员送的 XMLR 在线听书。)
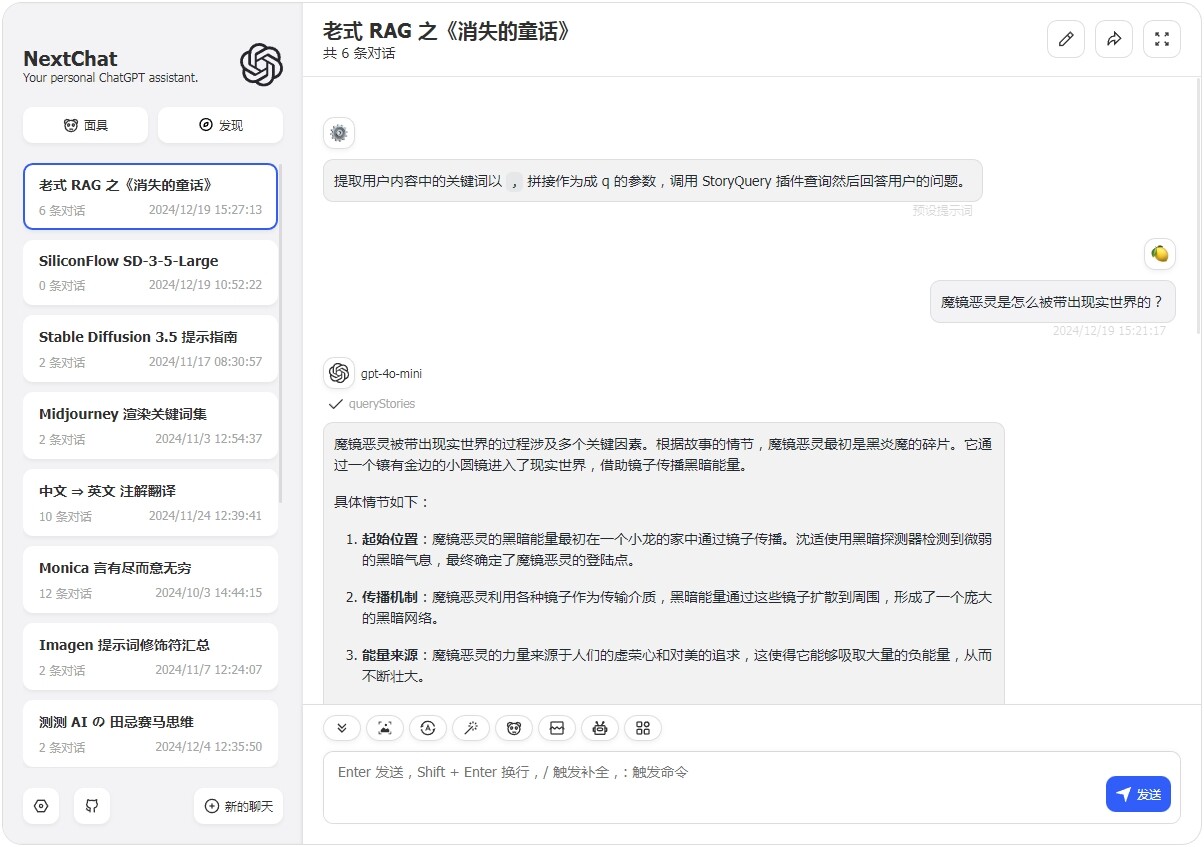

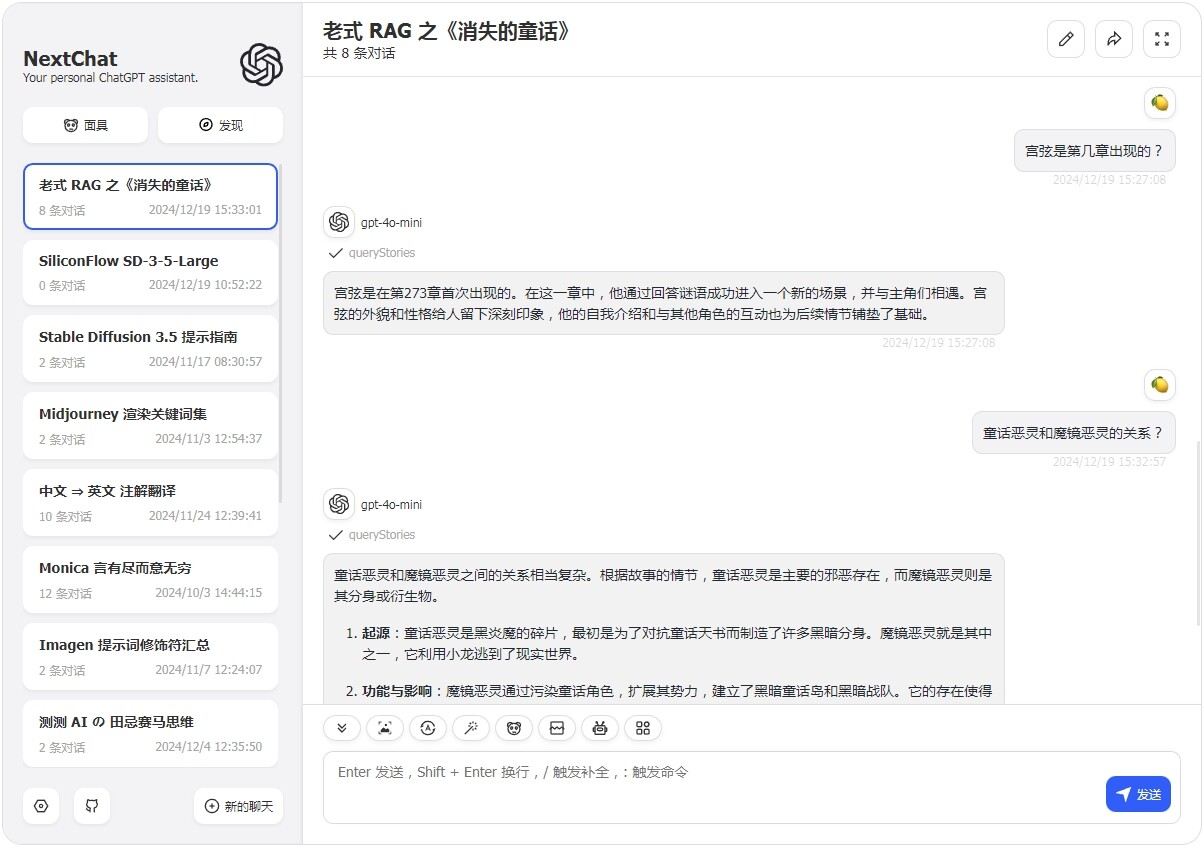
插件调用过程:
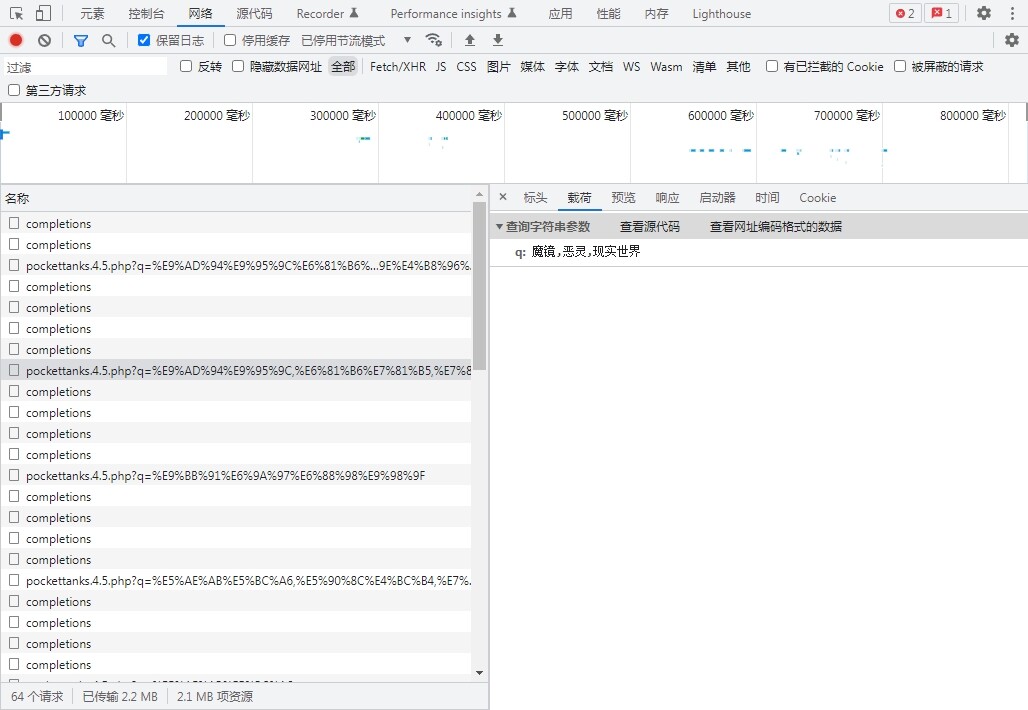
直接访问接口是这样的数据,去掉了所有冗余空格减少体积,反正大模型看得懂。
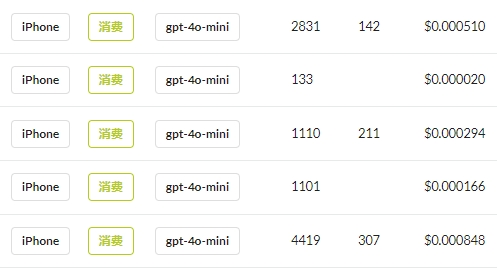
插件查询消耗 Tokens:
就是这样。原帖的第 3、4 步处理很快不值一提。
最麻烦是 Gemini 转录文本这一步,要像工厂打螺丝那样一个一个投喂,然后模型也不都是那么稳定如果没有按格式输出就得摁停纠正。
与向量 RAG 相比劣势是无法通过语义查询,但已经足够满足我的需求了。
一些「数据清洗阶段」的注意点:
因为是纯音频转文本一些「冷门」词汇例如名字什么(本书中更常见的高频词「审视」和主角团之一「沈适」同音就大量被转录成前者。。)的是很难正确处理的,通过预置 Prompt 可以解决很大部分但多少有遗漏。而大模型的「大海捞针」找一两个目标可以,多了就失能了,这种有规律的丢给 Python 就行。
反正就是让 Claude 写个 Python 筛选同音词汇:
FindHomophones.py
import pypinyin
from collections import defaultdict
import re
import tkinter as tk
from tkinter import filedialog
import os
def get_pinyin(word):
return ''.join(pypinyin.lazy_pinyin(word))
def process_large_file(file_path):
pinyin_dict = defaultdict(set)
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 使用正则表达式匹配所有长度为2到4的中文字符
words = re.findall(r'[\u4e00-\u9fa5]{2,4}', line)
for word in words:
pinyin = get_pinyin(word)
pinyin_dict[pinyin].add(word)
return pinyin_dict
def find_homophones(pinyin_dict):
return {pinyin: words for pinyin, words in pinyin_dict.items() if len(words) > 1}
def main():
root = tk.Tk()
root.withdraw() # 隐藏主窗口
input_file = filedialog.askopenfilename(
title="选择要处理的文本文件",
filetypes=[("Text files", "*.txt"), ("All files", "*.*")]
)
if not input_file:
print("没有选择文件,程序退出。")
return
# 获取输入文件的目录和文件名(不包括扩展名)
input_dir, input_filename = os.path.split(input_file)
input_name = os.path.splitext(input_filename)[0]
# 在脚本所在目录创建输出文件
script_dir = os.path.dirname(os.path.abspath(__file__))
output_file = os.path.join(script_dir, f"{input_name}_homophones.txt")
pinyin_dict = process_large_file(input_file)
homophones = find_homophones(pinyin_dict)
with open(output_file, 'w', encoding='utf-8') as out_file:
for pinyin, words in homophones.items():
out_file.write(f"拼音 '{pinyin}' 对应的同音词: {', '.join(words)}\n")
print(f"结果已保存到: {output_file}")
if __name__ == "__main__":
main()
但 Python 程序没有「语义」理解的能力,所以筛选出来之后还需要丢回大模型再筛一遍:
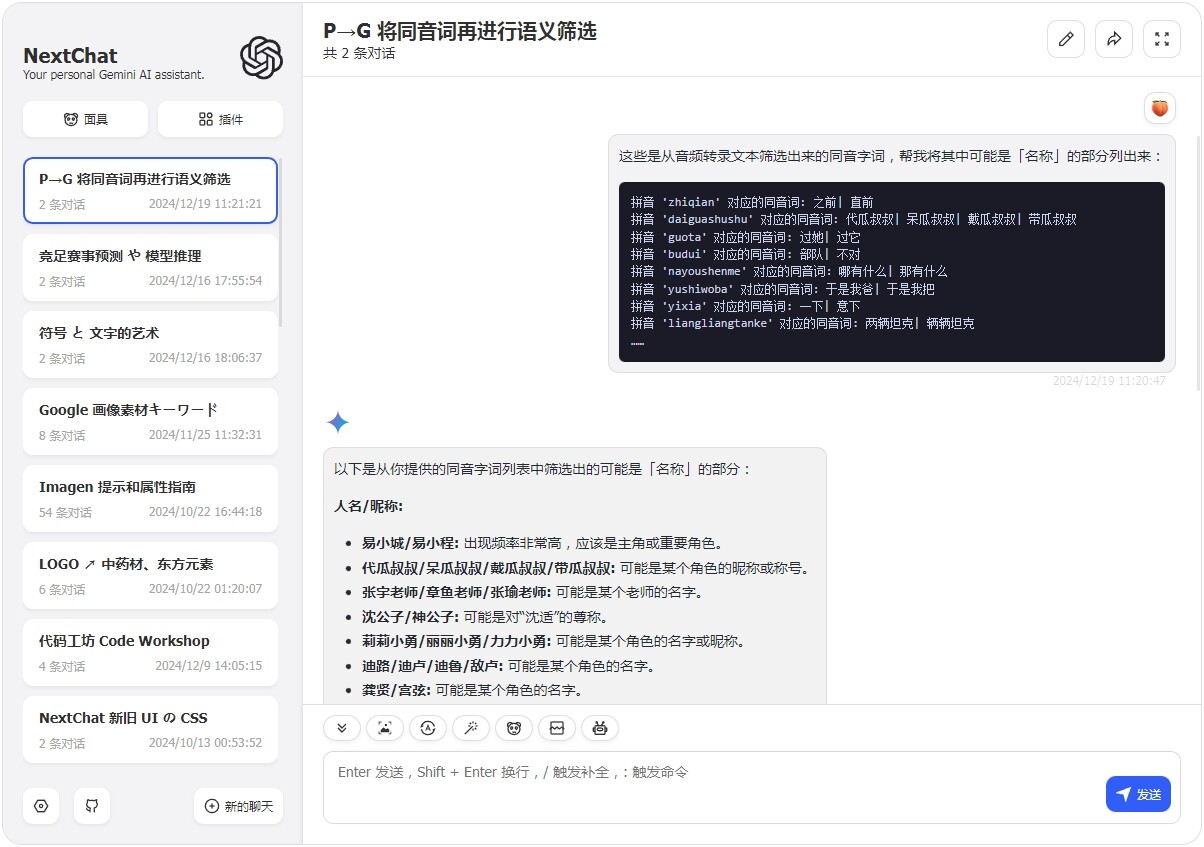
然后挑出主要的手动全局替换一下。。嗯,苦力活。好在数据量不太多。
有个偏门的想法是建个全拼音的索引,然后搜索时也转成拼音搜索再转回去,但感觉这样是简单的问题复杂化了,目前还不需要遂放弃。
校正完主要角色名之后,就是把文本清洗一下:统一格式 + 清楚冗余空格,这一步也是让 Claude 写 Python,我用的 GCP 的 3.5 Sonnet 0621 都是一稿过稳得一逼。
ChapterTextCleaner.py
import tkinter as tk
from tkinter import filedialog
import re
import os
def process_file():
# 创建一个Tkinter根窗口(但不显示)
root = tk.Tk()
root.withdraw()
# 弹出文件选择对话框
file_path = filedialog.askopenfilename(filetypes=[("Text files", "*.txt")])
if not file_path:
print("没有选择文件")
return
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
# 使用正则表达式分割章节
chapters = re.split(r'(^第\d.+?\n)', content, flags=re.MULTILINE)
# 处理章节内容
result = ["Key\tContents"]
for i in range(1, len(chapters), 2):
title = chapters[i].strip()
text = chapters[i+1] if i+1 < len(chapters) else ""
# 去除冗余空格和换行
text = re.sub(r'\s+', ' ', text).strip()
result.append(f"{title}\t{text}")
# 生成输出文件路径
output_path = os.path.join(os.path.dirname(file_path), "processed_output.txt")
# 写入结果到文件
with open(output_path, 'w', encoding='utf-8') as file:
file.write('\n'.join(result))
print(f"处理完成,结果已保存到: {output_path}")
if __name__ == "__main__":
process_file()
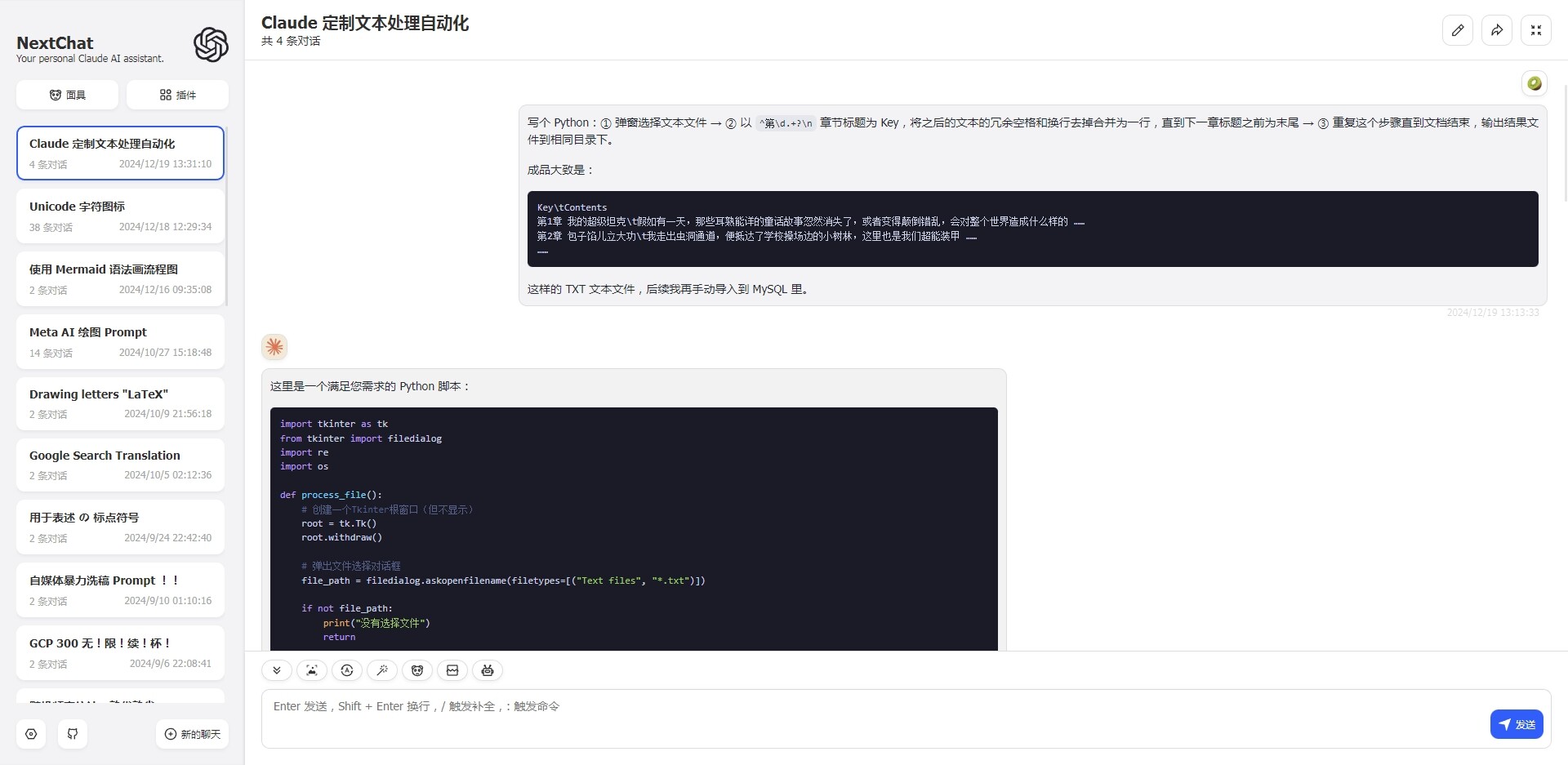
原始数据:
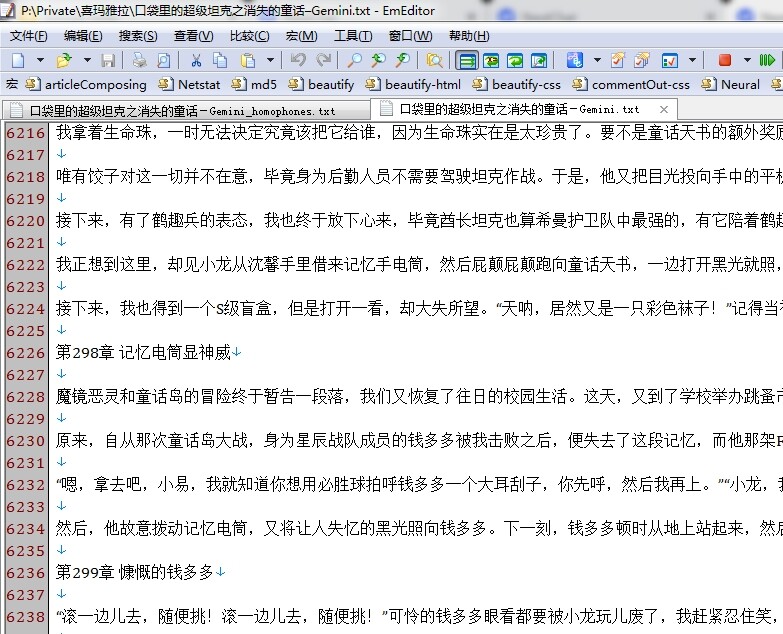
清洗之后:

最后还是让 Claude 再写个 Python,统计筛选一下异常长的行:
AnalyzeText.py
import tkinter as tk
from tkinter import filedialog
import heapq
def analyze_file():
# 创建一个Tkinter根窗口(但不显示)
root = tk.Tk()
root.withdraw()
# 弹出文件选择对话框
file_path = filedialog.askopenfilename(filetypes=[("Text files", "*.txt")])
if not file_path:
print("没有选择文件")
return
# 读取文件内容
with open(file_path, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 跳过标题行
lines = lines[1:]
# 计算每行的字数(不包括Key和制表符)
line_lengths = [(len(line.split('\t')[1].strip()), i+1, line.split('\t')[0].strip()) for i, line in enumerate(lines)]
# 使用堆来找出字数最多的20行
top_20 = heapq.nlargest(20, line_lengths)
# 输出字数最多的20行
print("字数最多的20行:")
for count, line_num, title in top_20:
print(f"{title}: {count}字")
# 计算平均字数
total_chars = sum(len(line.split('\t')[1].strip()) for line in lines)
avg_chars = total_chars / len(lines)
print(f"\n行平均字数: {avg_chars:.2f}")
if __name__ == "__main__":
analyze_file()
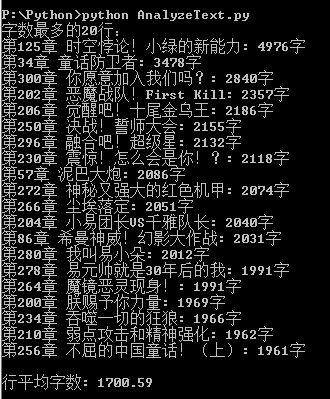
把太长的字段再分割一下省得 Tokens 爆炸,然后入库。
最后再让 Claude 写了个 NextChat 插件,大概这样:
openapi: 3.0.1
info:
title: StoryQuery
description: A plugin to query stories from 你的接口域名
version: 'v1.0'
servers:
- url: https://你的接口域名
paths:
/pockettanks.4.5.php:
get:
operationId: queryStories
summary: Query stories based on keywords
parameters:
- name: q
in: query
description: Comma-separated keywords for querying stories
required: true
schema:
type: string
responses:
"200":
description: Successful response
content:
application/json:
schema:
type: object
我也看不懂,但能用。