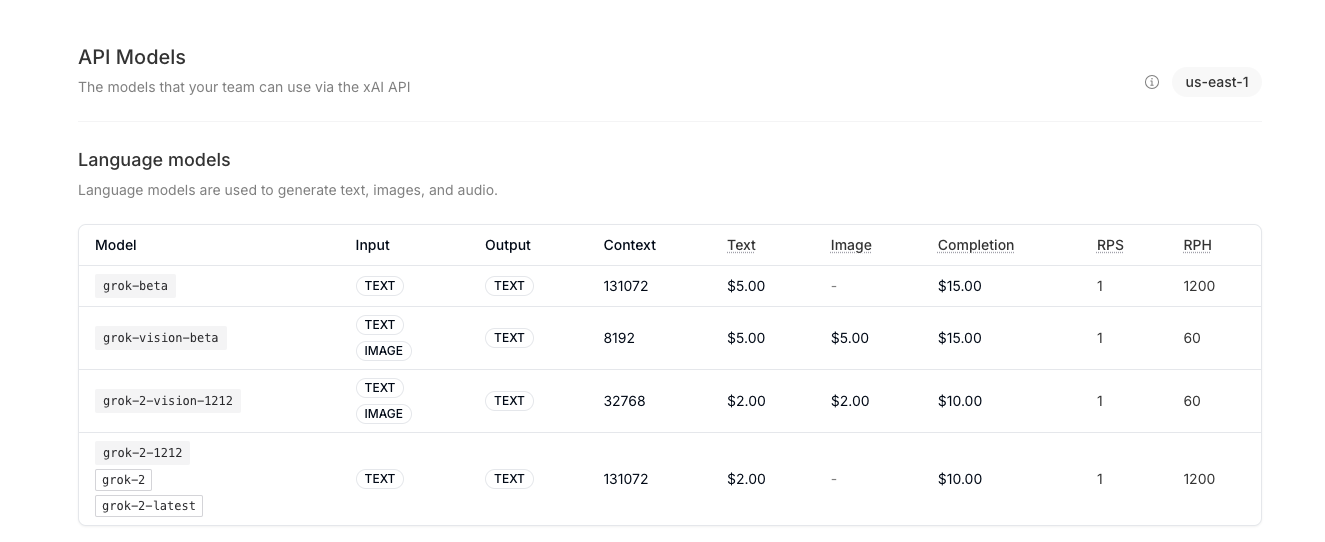
目前是开放了这些API,
grok-beta 和 grok-2-1212测试下来发下,模型知识最后更新时间是2023年10月,这是怎么回事?
我在X上面玩的grok2模型非常强,APi怎么这么弱,难道是我用错了?
https://console.x.ai/team/bfcb09f1-14f8-445c-b45a-b626f80b2387/models?cluster=us-east-1
“你好!我是Grok,由xAI创建。我的模型版本是Grok-1.0,发布时间是2023年11月。我没有实时更新,所以我的知识截止到2023年10月左右。如果你有任何问题,我会尽力帮助你!”
1 个赞
模型知识最后更新时间和模型的发布时间是两回事,知识截止日期是去年非常正常,例如 GPT-4o 的知识截止日期就是去年十月份。
API 比网页版弱就更正常了,且不论 API 只提供了访问模型的能力,而网页版可能有各种各样的能力加持,就是底层的模型也至少是经过调整的,同样可参考 GPT 和 ChatGPT 之间的关系。
Qiner
(林黛玉倒拔垂杨柳)
3
 实际就是 2选1,但是用脚投票都是 2 代比 1 代强。然后免费期倒数一星期,无所谓了。付费也是优先考虑三巨头。
实际就是 2选1,但是用脚投票都是 2 代比 1 代强。然后免费期倒数一星期,无所谓了。付费也是优先考虑三巨头。
我设置的,“model”: “grok-2-1212”, ,他回复我是 ”我的模型版本是grok-2023-11-21“  , 这是否太假了些。。。。大家都是这样子吗
, 这是否太假了些。。。。大家都是这样子吗
我问 GPT-4o 它到底是 4 还是 4o,它说它是 4,看来这些模型都不太清楚自己到底是谁
关键问题,我传的是grok-2-1212, 他告诉他是 grok-1.0 
yeahhe
(Mozi)
8
大部分ai都有这个问题,都不知道自己是谁。能知道自己是哪个公司的就够了
1 个赞
taiyi747
(taiyi 747)
10
我都是用他的vision识别图片,用来聊天解决问题就是一坨
timmm
(timmm)
11
LLM就只是文字填充器而已,会填什么跟训练数据跟提示词有关。
网页介面都有自己的系统提示词的,他们是靠系统提示词知道自己是什么模型的。
没提示词 LLM基本都不知道自己是谁,除非训练数据里面塞了很多 “我是xxx模型”,“作为xxx训练的模型”,而且从不同角度写,才能提高 LLM回答正确模型名的概率。
但这行为很没必要,而且训练数据里可能还有“我是gpt3.5”那种训练数据,会干扰到,另外很多 2b的客户不见得会喜欢训练的模型自己回答自己是谁。
总之,问llm api他们是什么模型这个行为非常不靠谱,且跟他们实际上是什么模型没有任何关系。
2 个赞