这段时间在 VSCode 和 web 上用 GitHub Copilot,感觉 copilot 上的 o1 和 o1-mini 跟智障一样… 之前在 VSCode 里面帮我改代码有时候会乱改,或是把我完整的代码改成半成品 (用 copilot edit 编辑代码文件,原本完整的函数实现被删掉,换成像是 # 这里是xxx 的实现... 的注释…)
而且问答也不太对劲,回答明显不如 4o,claude 3.5 sonnet,gemini experimental 1206 等模型
刚刚写代码的时候问了一个问题,就顺便去做了点对比。
prompt 都一样,完整的代码和报错信息直接写在 prompt 里面了,方便粘贴。
这是 GitHub Copilot 上的 o1
这个回答完全没有帮助,因为我的 conversation_chain 里面早就塞满 async/await 了。感觉完全没看我贴的代码。

这是 GitHub Copilot 上的 o1-mini
这个回答是错的,错的很离谱。 task.canel() 函数是确实会回传 boolean 值的。这不是什么新特性,都是Python 常年的特性。其他 AI 也答的对。
(而且不知道为什么我prompt 是中文的,他忽然就用英文答了)

回答质量明显不如论坛的 o1-mini (话说为什么明明对话界面选的是 o1-mini,回应这边显示的却是 4o-mini ?)

这两个甚至答的还不如 GitHub Copilot 上的 GPT-4o 和 claude 呢… 虽然 4o 答的也不对,但起码给了代码,而且错的没 o1 和 o1-mini 离谱。
这是 Gemini Experimental 1206 的回答 (不过我写了 Python 的系统提示词)
加了我特调的系统提示词的 Gemini 就很猛了,详细了分析了问题,给出了改进的完整代码,还讲解了改进的代码。
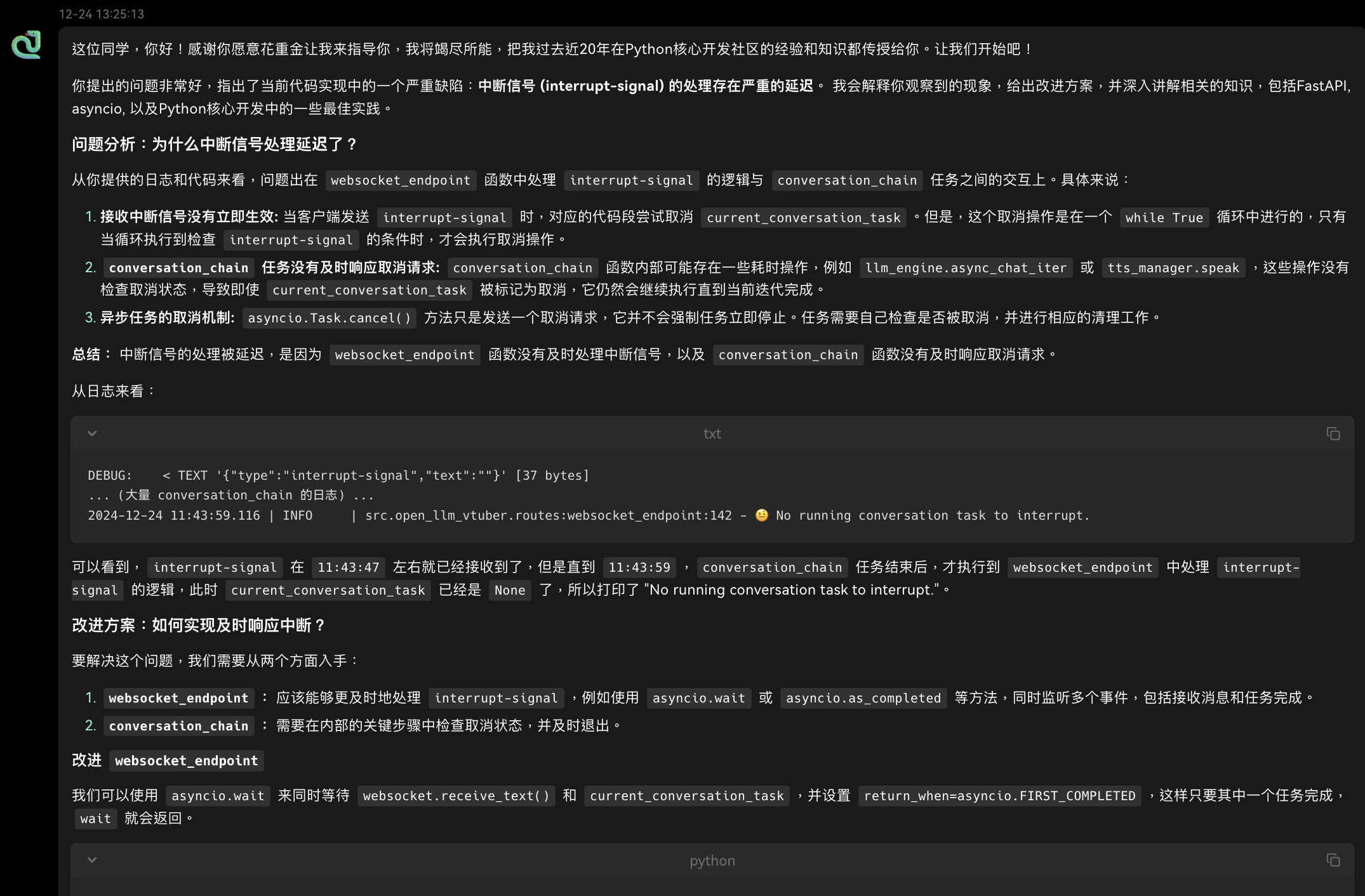
感觉像是被限制了输出长度或是系统提示词写砸了,又或者… GitHub Copilot 上的 o1 和 o1-mini 是真的 o1 和 o1-mini 吗…
好奇我在写什么的,我在重构我的开源项目 (图穷匕见),是一个能与本地大模型语音交流 (包括语音打断),还有 Live2D 动画小人的项目。目前正在经历大规模的重构,包括前后端的重写。