唯一的缺点是:没有 README ![]() ,一副「我们就是这么豪横」的气质。
,一副「我们就是这么豪横」的气质。
官方:“README?我们还没来得及写,因为在忙着上传权重。” ![]()
权重链接:
唯一的缺点是:没有 README ![]() ,一副「我们就是这么豪横」的气质。
,一副「我们就是这么豪横」的气质。
官方:“README?我们还没来得及写,因为在忙着上传权重。” ![]()
权重链接:
官网还没有,不好说哈哈哈哈
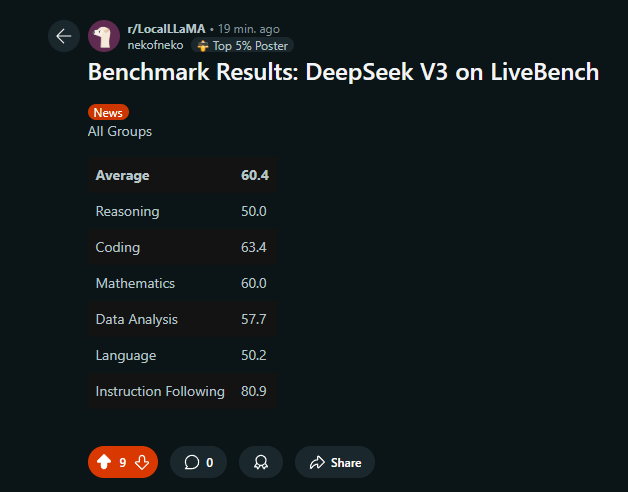
这个数据是没问题的,我自己跑的是62出头,群友也跑了,60.几,都是误差范围
685b比gpt4o能力强我倒不是很惊讶,问题是真比Claude3.5强吗,(opus在榜上都看不见?我觉得opus能力还是挺猛的)
livebench官网上3opus是49.12,我截掉了
4o这越更新越落后也是给我整笑了
這波能不能逼出claude的3.5-opus或者claude-4-sonnet?
貌似干翻了哈哈哈
根据大家的回复,思考了一些内容:
评测数据来源分析 ![]()
![]()
LiveBench 数据:
P3
P4
该数据来源于公开的 P3 数据,这是基于 10.22 的测试数据。![]()
最新数据测试:
P5
最新的测试数据为 P5 数据,目前尚未开源,所以佬提供的数据可能是与 P4 结果对标的测试数据,预计分数接近 60 分。![]()
结合佬提供的 DeepSeek-v3 的成绩:
DeepSeek-v3 的测试分数为 60+ 分,直逼 o1。
卧槽,果然很猛
不思考的模型能和思考模型碰一碰的也就只有谷歌和deepseek了
如果是真的话就很厉害了
这波很猛啊
感觉openai再憋一个大招哈哈 ![]()
就是豪横!
跑这个模型需要至少30张4090,或者10张H100,成本大概60万-100万之间。有钱的佬可以部署一个玩玩。
![]() 非常人可玩版
非常人可玩版
编程的排行还是挺靠谱的,用过 OpenAI01.net 的o1,远超 Claude-3.5-Sonnet 和 gemini-exp-1206