有没有佬友分享的,![]()
![]() 了
了
如果是iOS,可以用代理工具+插件实现
1 个赞
佬能给点提示吗,用什么脚本
1 个赞
便捷下载app
1 个赞
可莉的小红书去广告插件,可以去广告+去水印+解除下载限制
自己找一下: ProxyResource/README.md at main · luestr/ProxyResource · GitHub
3 个赞
好的,我试试,谢谢佬
1 个赞
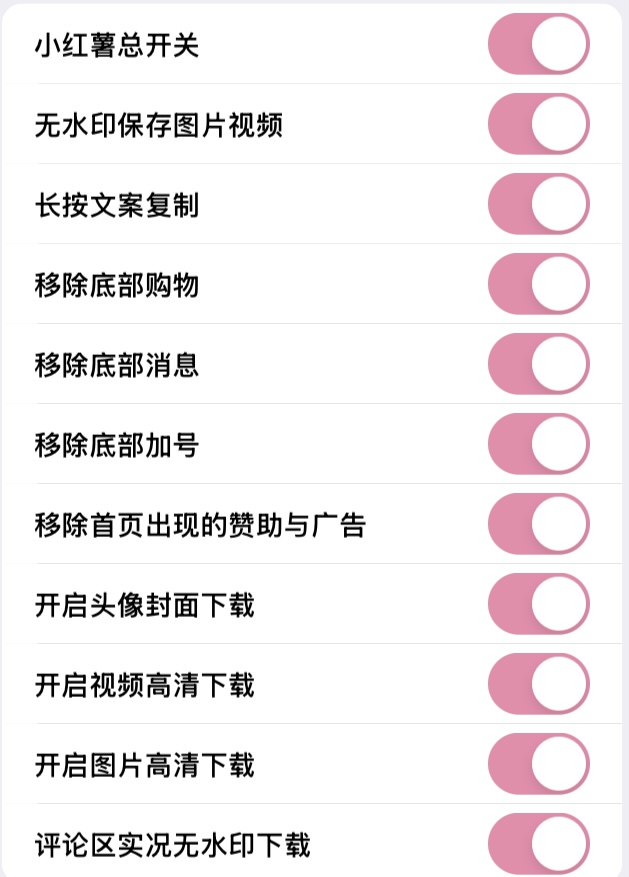
PicSeed 图片下载器
微博、小红书、推特、即刻图片下载器,高质量、无水印、批量快速。
#网页 #下载 #工具
短视频无水印下载工具,支持快手、抖音、小红书、秒拍、tiktok、贴吧、微博、微视、美拍等平台,复制粘贴视频链接,即可直接下载,免费使用,无需注册
3 个赞
感谢分享 ![]()
1 个赞
复制连接,微信小程序解析
有ipa吗
1 个赞
电脑下载图片是没有水印的
1 个赞
我记得有一个小程序可以
1 个赞