继上篇帖子 【个人项目】做了一个 github 增强搜索网站,欢迎大家使用 继续讨论:
在社区分享了我的项目之后,发现大家反响不错,确实有帮助到用户,于是就有了把网站持续迭代、运营下去的想法
网站地址:https://githubhunt.top/
第一件事情是最近两天爆肝版本  ,新增了一些功能:
,新增了一些功能:
- 新增以库搜库模式:即指定一个仓库名称,搜索与这个仓库相似的其他仓库
- 支持 文档语言 过滤选项
- 支持 明亮/暗黑主题,支持 I18N 国际化
- 界面样式优化
(另外想问下大家有什么好用的 ai logo 生成器吗,现在的 logo 有点丑 
第二件事情是关于是否开源:
首先,我个人还是想把它做成一个有些收益的项目,项目本身技术难度还好,都是用的比较成熟的 pipline 和模型,主要成本在数据质量(以及 token 成本)和推理(服务器成本)上,而且后续有引入 rerank 模型精排的想法,会进一步提高搜索质量,但是对算力要求会更高,这靠开源可能无法满足,或者大家有不同意见也可以讨论 
第三件事情是如何运营:
练习时长两年半的开发练习生表示,对运营和产品化没有一点想法  ,最近也在学习跳脱开发思维去思考产品,也希望大家能多给点建议
,最近也在学习跳脱开发思维去思考产品,也希望大家能多给点建议 
14 个赞
祝好运,不过日后收费的话,站内不能推广了哟,帖子要去深海了哟
1 个赞
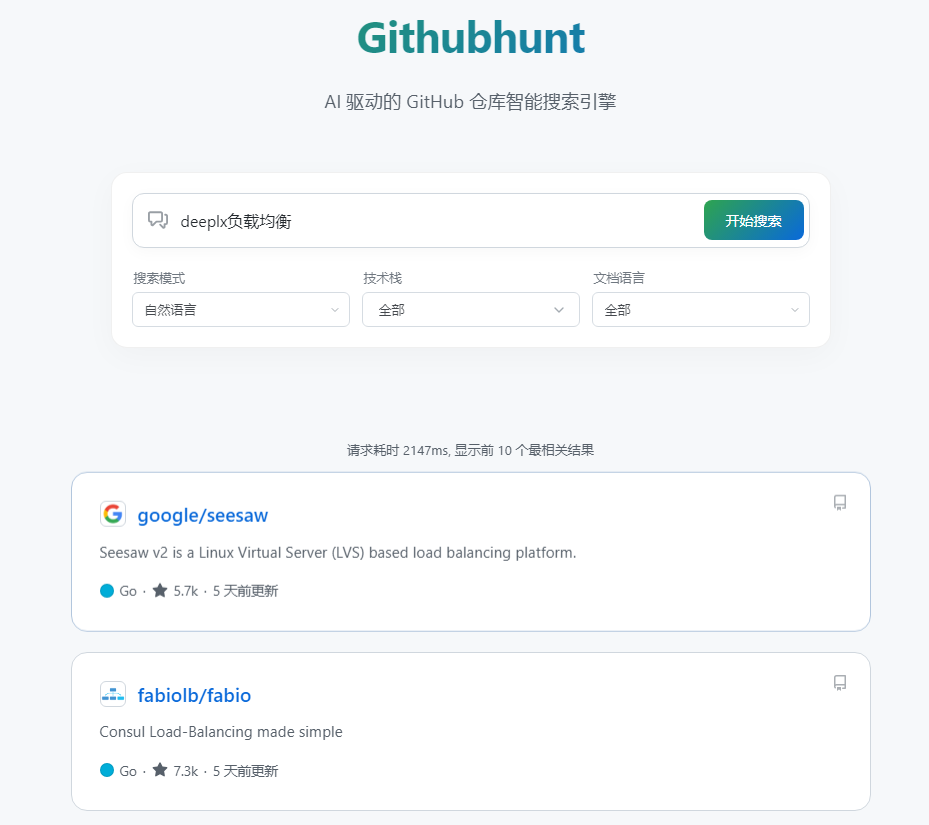
这种类似的项目,最差至少要和deeplx相关,deeplx才是主题,负载均衡是修饰
现在的结果只有负载均衡了deeplx直接被省略了
1 个赞
GET,我理解了,这确实是个问题,看看后续如何优化
这里可能是因为网站只收录了 1k star 以上的,没包含进这些仓库 
我以为是现场在github搜的返回结果再处理的 ,收录的形式感觉无法应对一下小的仓库
,收录的形式感觉无法应对一下小的仓库
小仓库的话主要数据量太大,之前想过,可以结合搜索引擎去做聚合,这样网站自身的数据压力就下来了
赞一个,确实有这个痛点,但感觉搜索结果还可以继续提高,已经有用了。
1 个赞
建议先把功能和性能完善下去,把用户体量和粘性积累起来,然后再考虑运营的事情。
说句现实的,用户粘性不高,很难会有啥收益。
system
(system)
关闭
19
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。