趁着春节有时间,搓了个 perplexity 的 api 函数,虽然大家都说deepseek的联网搜索很强大,但是我个人使用下来,perplexity 的查询准确度,查询速度目前还是顶尖的,在查询最新的资料和时事新闻的时候还是很好用滴。那么废话不多说,直接上代码
v1.0.2更新 修复最新推出的 sonar-reasoning 普通文本错位BUG ,
v1.0.3更新 修复最新推出的 sonar-reasoning 思维链模型吞字BUG
修复<think> 标签导致输出内容缺字或错位的 Bug (2025.2.2更新)
在 @zgccrui 的帮助下完成代码修改
pipe代码
"""
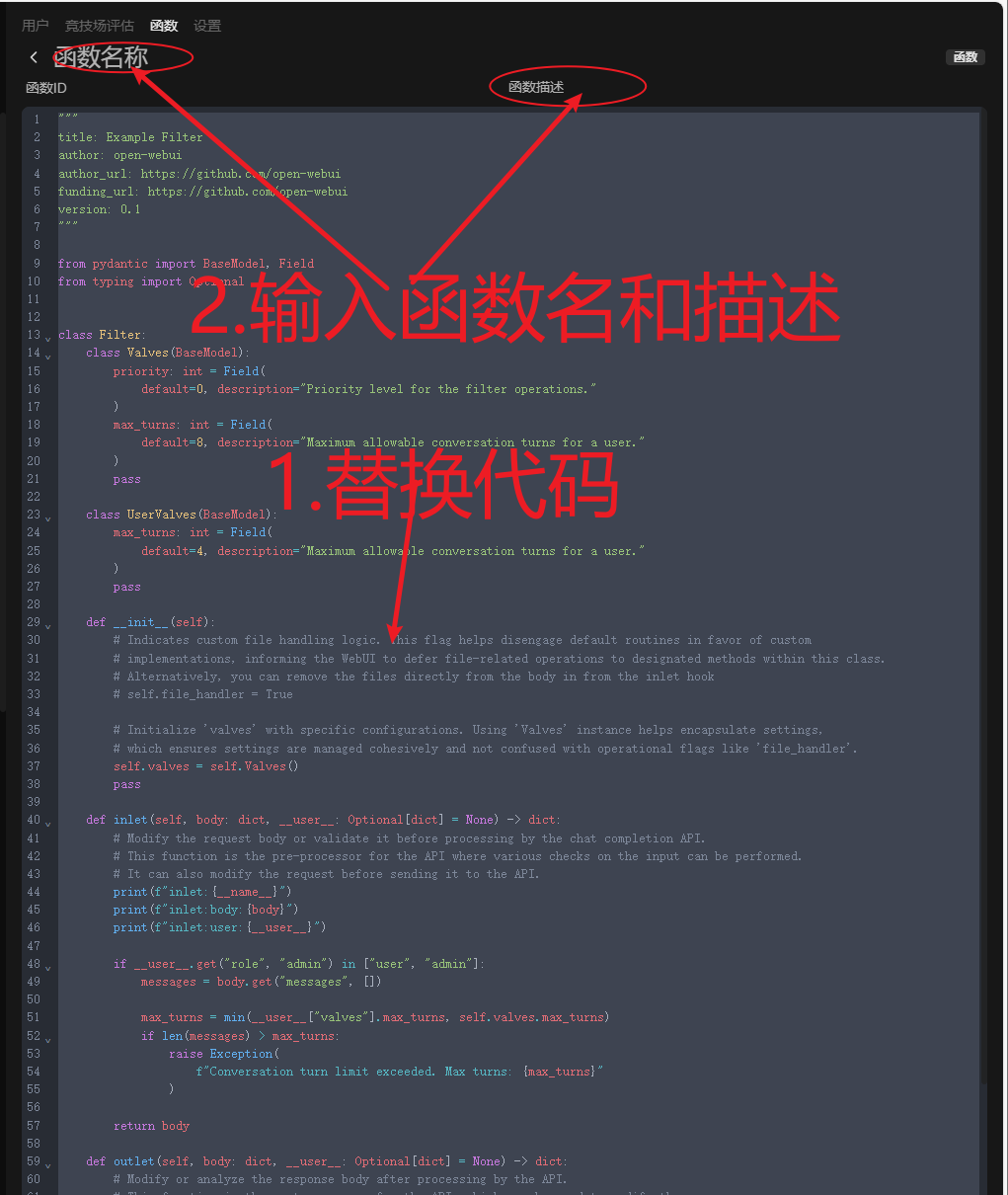
title: chat01流式输出代码(含爬取网页标题,可选模型,格式改进)
author: konbakuyomu
description: 在OpwenWebUI中,根据不同模型做不同的屏蔽策略。
version: 1.0.3
licence: MIT
"""
import json
import httpx
import re
import traceback
import asyncio
from typing import AsyncGenerator, Callable, Awaitable
from pydantic import BaseModel, Field
from urllib.parse import urlparse
TITLE_REGEX = re.compile(r"<title>(.*?)</title>", re.IGNORECASE | re.DOTALL)
def fetch_page_title(url: str, timeout: float = 10.0) -> str:
try:
resp = httpx.get(url, timeout=timeout)
if resp.status_code != 200:
return ""
html_content = resp.text
match = TITLE_REGEX.search(html_content)
if match:
return match.group(1).strip()
except Exception as e:
print(f"请求或解析页面时出错: {e}")
return ""
def extract_domain(url: str) -> str:
try:
parsed = urlparse(url)
return parsed.netloc or ""
except:
return ""
class Pipe:
class Valves(BaseModel):
PERPLEXITY_API_BASE_URL: str = Field(
default="https://api.perplexity.ai", description="Perplexity 的基础请求地址"
)
PERPLEXITY_API_TOKEN: str = Field(
default="", description="用于访问 Perplexity 的 Bearer Token"
)
PERPLEXITY_MODEL: str = Field(
default="sonar-reasoning",
description=(
"可选的模型名称,必须是以下之一:"
"sonar-reasoning, sonar-pro, sonar, "
"llama-3.1-sonar-small-128k-online, "
"llama-3.1-sonar-large-128k-online, "
"llama-3.1-sonar-huge-128k-online"
),
)
VALID_MODELS = [
"sonar-reasoning",
"sonar-pro",
"sonar",
"llama-3.1-sonar-small-128k-online",
"llama-3.1-sonar-large-128k-online",
"llama-3.1-sonar-huge-128k-online",
]
def __init__(self):
self.valves = self.Valves()
self.data_prefix = "data: "
self.emitter = None
self.current_citations = []
# 多个关键词,仅删除一次。在对话结束后会自动重置。
self.keywords_once = {"嗯": False, "好": False}
def pipes(self):
return [{"id": "perplexity", "name": "Perplexity"}]
async def pipe(
self, body: dict, __event_emitter__: Callable[[dict], Awaitable[None]] = None
) -> AsyncGenerator[str, None]:
"""
当模型 == sonar-reasoning 时,执行:
1) 只保留 <think> 后的内容(含 <think>)。
2) 屏蔽 {"嗯", "好"} (在整个对话流程中,只删一次)。
其它模型不做上述处理,直接输出原始增量文本。
对话结束时,会自动把只删一次的标记重置。
"""
self.emitter = __event_emitter__
self.current_citations = []
# (A) 检查TOKEN
if not self.valves.PERPLEXITY_API_TOKEN:
err_msg = "未配置 Perplexity API Token"
yield json.dumps({"error": err_msg}, ensure_ascii=False)
return
# (B) 检查模型是否合法
if self.valves.PERPLEXITY_MODEL not in self.VALID_MODELS:
err_msg = (
f"模型 '{self.valves.PERPLEXITY_MODEL}' 不在可选范围:"
f"{', '.join(self.VALID_MODELS)}"
)
yield json.dumps({"error": err_msg}, ensure_ascii=False)
return
# 处理用户输入中的图片链接
self._inject_image_if_any(body)
# 组装payload
payload = {**body}
payload["model"] = self.valves.PERPLEXITY_MODEL
if "stream" not in payload:
payload["stream"] = True
headers = {
"Authorization": f"Bearer {self.valves.PERPLEXITY_API_TOKEN}",
"Content-Type": "application/json",
}
url = f"{self.valves.PERPLEXITY_API_BASE_URL}/chat/completions"
try:
async with httpx.AsyncClient(http2=True) as client:
async with client.stream(
"POST", url, json=payload, headers=headers, timeout=120
) as response:
if response.status_code != 200:
error_content = await response.aread()
err_str = self._format_error(
response.status_code, error_content
)
yield err_str
return
# 1) 连接成功 => "😃 AI回答正在生成中……"
if self.emitter:
await self.emitter(
{
"type": "status",
"data": {
"description": "😃 AI回答正在生成中……",
"done": False,
},
}
)
first_chunk = True
# 2) 逐行读取 SSE
async for line in response.aiter_lines():
if not line.startswith(self.data_prefix):
continue
data_str = line[len(self.data_prefix) :].strip()
if not data_str:
continue
try:
data = json.loads(data_str)
except:
continue
if "citations" in data:
self.current_citations = data["citations"]
choice = data.get("choices", [{}])[0]
delta = choice.get("delta", {})
delta_text = delta.get("content", "")
if delta_text:
# 如果是第一块有效回答 => "🚀 Perplexity 联网查询中..."
if first_chunk and self.emitter:
await self.emitter(
{
"type": "status",
"data": {
"description": "🚀 Perplexity 联网查询中,请稍候…",
"done": False,
},
}
)
first_chunk = False
# ============== think标签后必须单独一次返回换行符 ==============
if delta_text:
if delta_text.startswith("<think>"):
match = re.match(r"^<think>", delta_text)
if match:
delta_text = re.sub(r"^<think>", "", delta_text)
yield "<think>"
await asyncio.sleep(0.1)
yield "\n"
elif delta_text.startswith("</think>"):
match = re.match(r"^</think>", delta_text)
if match:
delta_text = re.sub(
r"^</think>", "", delta_text
)
yield "</think>"
await asyncio.sleep(0.1)
yield "\n"
# 仍然可以对引用进行转换处理
delta_text = self._transform_references(
delta_text, self.current_citations
)
yield delta_text
# 3) 服务器断开 => "🔎 正在获取参考网站标题..."
if self.emitter:
await self.emitter(
{
"type": "status",
"data": {
"description": "🔎 正在获取参考网站标题,请稍候…",
"done": False,
},
}
)
if self.current_citations:
yield self._format_references(self.current_citations)
# 4) 最终完成 => "✅ Perplexity生成结束"
if self.emitter:
await self.emitter(
{
"type": "status",
"data": {
"description": "✅ Perplexity生成结束",
"done": True,
},
}
)
# 对话结束后 => 重置只删一次的标志
self._reset_keywords_once()
except Exception as e:
traceback.print_exc()
err_str = self._format_exception(e)
yield err_str
# ------------------------------------------------------------------------
# 只保留从 <think> 开始(含)到文本结尾
# ------------------------------------------------------------------------
def _filter_before_think_tag_in_chunk(self, text: str) -> str:
idx = text.find("<think>")
if idx == -1:
return text
return text[idx:]
# ------------------------------------------------------------------------
# 针对多个关键词(如 "嗯", "好"),只在全局移除它们的首次出现
# ------------------------------------------------------------------------
def _remove_keywords_once_in_chunk(self, text: str) -> str:
for kw, removed_flag in self.keywords_once.items():
if not removed_flag:
idx = text.find(kw)
if idx != -1:
text = text[:idx] + text[idx + len(kw) :]
self.keywords_once[kw] = True
return text
# ------------------------------------------------------------------------
# 对话结束后重置一次性删除标记
# ------------------------------------------------------------------------
def _reset_keywords_once(self) -> None:
"""
当一轮回答/对话完全结束后(发送“✅ Perplexity生成结束”),
将 self.keywords_once 的值全部设回 False,
以便下一次对话又可以再删一次。
"""
for kw in self.keywords_once:
self.keywords_once[kw] = False
# ------------------------------------------------------------------------
# [n] => [[n]](url) 引用替换
# ------------------------------------------------------------------------
def _transform_references(self, text: str, citations: list[str]) -> str:
def _replace_one(m: re.Match) -> str:
idx_str = m.group(1)
idx = int(idx_str)
if 1 <= idx <= len(citations):
url = citations[idx - 1]
return f"[[{idx_str}]]({url})"
else:
return f"[[{idx_str}]]"
return re.sub(r"\[(\d+)\]", _replace_one, text)
# ------------------------------------------------------------------------
# 输出参考网址,并顺便获取其标题
# ------------------------------------------------------------------------
def _format_references(self, citations: list[str]) -> str:
if not citations:
return ""
lines = []
lines.append("\n\n> 参考网站")
for i, url in enumerate(citations, 1):
page_title = fetch_page_title(url)
if page_title:
lines.append(f"{i}: [{page_title}]({url})")
else:
domain = extract_domain(url)
if not domain:
domain = "unknown"
lines.append(f"{i}: [新闻来源: {domain}]({url})")
return "\n".join(lines)
# ------------------------------------------------------------------------
# 其他辅助
# ------------------------------------------------------------------------
def _format_error(self, status_code: int, error: bytes) -> str:
try:
err_msg = json.loads(error).get("message", error.decode(errors="ignore"))[
:200
]
except:
err_msg = error.decode(errors="ignore")[:200]
return json.dumps(
{"error": f"HTTP {status_code}: {err_msg}"}, ensure_ascii=False
)
def _format_exception(self, e: Exception) -> str:
err_type = type(e).__name__
return json.dumps({"error": f"{err_type}: {str(e)}"}, ensure_ascii=False)
def _inject_image_if_any(self, payload: dict) -> None:
messages = payload.get("messages", [])
if not messages:
return
last_msg = messages[-1]
if last_msg.get("role") != "user":
return
content_str = last_msg.get("content", "")
if not isinstance(content_str, str):
return
cleaned_text = re.sub(
r"(https?://[^\s]+?\.(?:png|jpg|jpeg|gif|bmp|tiff|webp))",
"",
content_str,
flags=re.IGNORECASE,
).strip()
last_msg["content"] = cleaned_text
目前代码实现的功能
1.分阶段更新动态状态
1) 😃 AI回答正在生成中……
2) 🚀 Perplexity 联网查询中,请稍候…
3) 🔎 正在获取参考网站标题,请稍候…
4) ✅ Perplexity生成结束
用户可以根据状态来判断当前代码执行到什么阶段了
2.自定义模型
目前 Supported Models - Perplexity perplexity API官方支持5个模型
"sonar-reasoning",
"sonar-pro",
"sonar",
"llama-3.1-sonar-small-128k-online",
"llama-3.1-sonar-large-128k-online",
"llama-3.1-sonar-huge-128k-online",
可以在设置中任选一个作为AI处理的模型,个人推荐 sonar-pro ,因为官方也说 llama这三个模型These models will be deprecated and will no longer be available to use after 2/22/2025,也就是要弃用了,目前就使用sonar系列的模型就OK
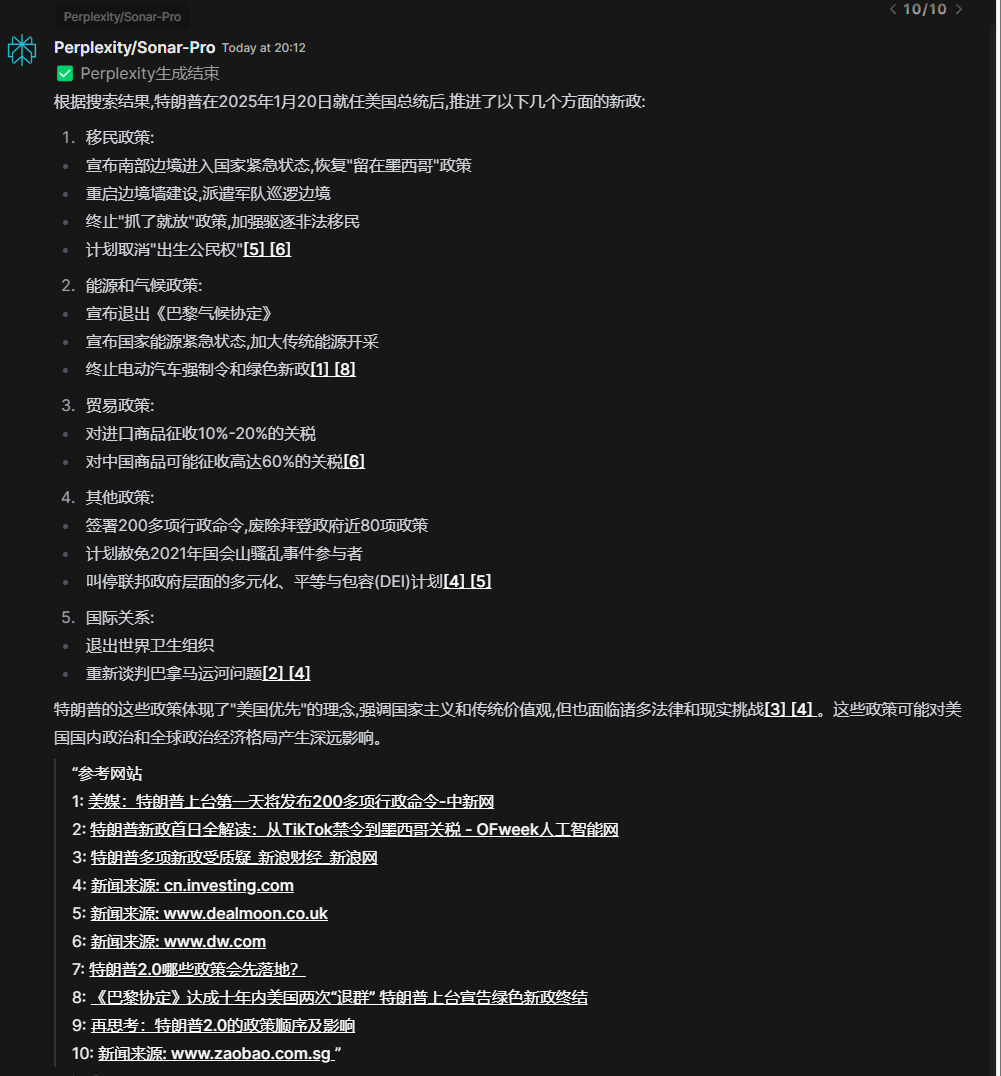
3.自动获取网站标题
嘛,效果直接看下图就行了,就是能自己爬取当前网站的标题,无法获取标题的网站也会注释他的来源是什么
闲扯两句
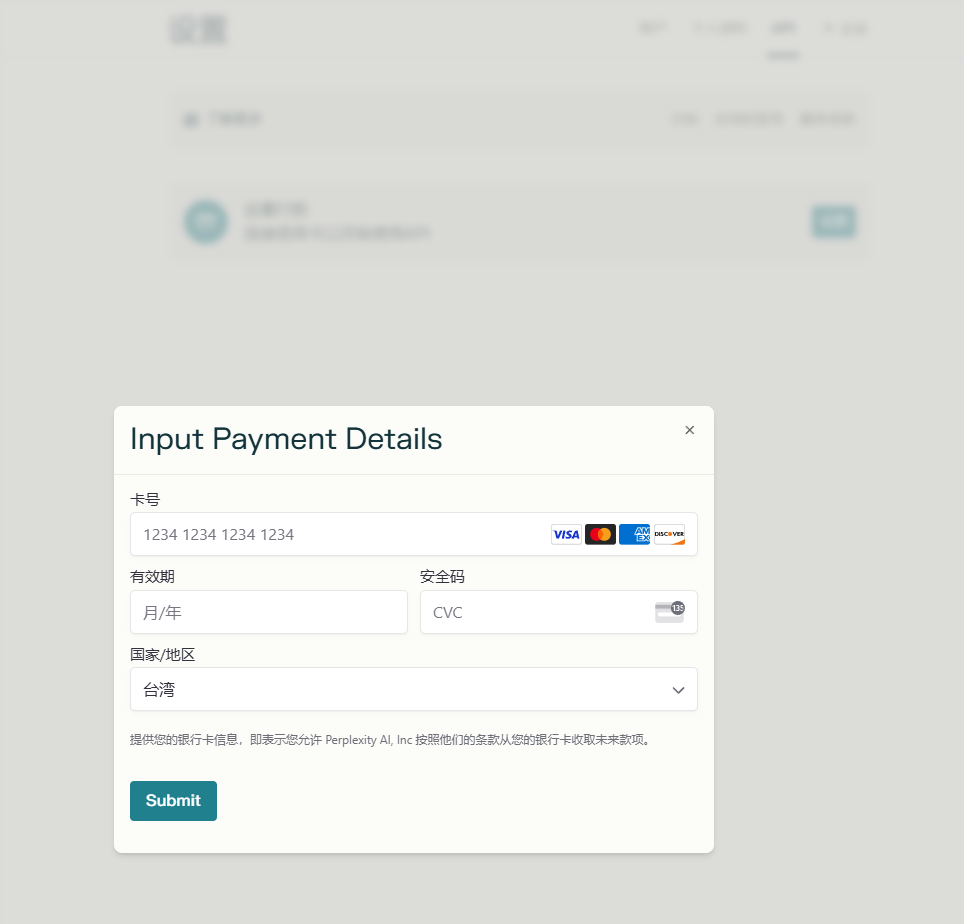
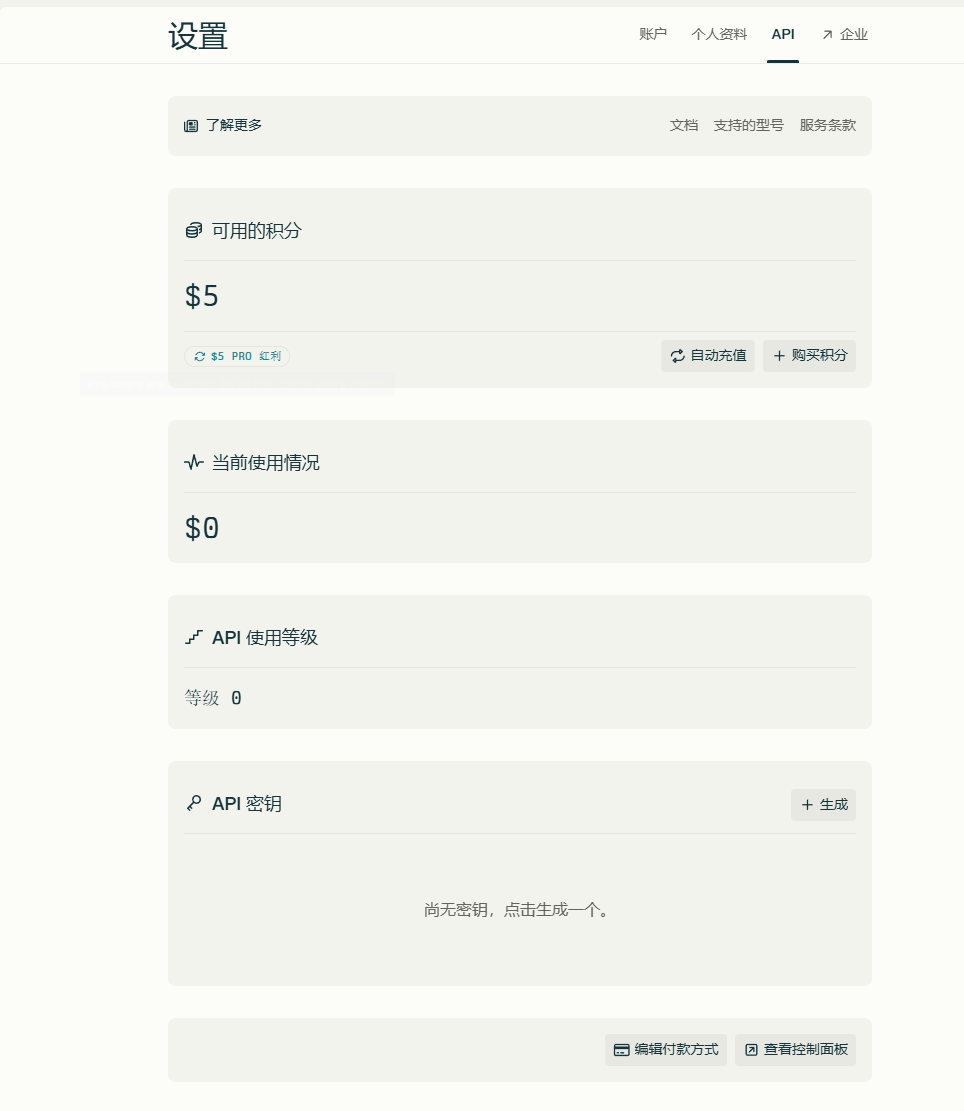
Tips:这个是能白嫖的,只要之前购买过pro或者通过大学教育账号绑定的一年的pro的帐号的话,在 perplexity API 界面直接绑国内visa或者MasterCard卡就能送5刀的额度。
另外,perplexity 的会员真没必要花钱买,直接api冲就完事儿了,现在那么多ai付费,没必要浪费20刀在这个上面,除非极个别情况,api完全足够了,虽说现在这个sonar系类的模型上下文长度不行,但用pplx的人不需要上下文(暴论),你就把这玩意儿当成one-shot就行了,反正也就看一次的搜索效果,不行再搜(
另外,虽然之前论坛内有大佬做出来了类似的函数
OpenWebui 函数Perplexity: llama-3.1-sonar-large-128k-online API完整支持 - 开发调优 - LINUX DO
但是我这个强迫症总感觉哪儿不对,所以自己搓了个自己满意的,基本上能满足我的日常需求了,我就是希望ui,过渡动画好看点,再加上把参考网站弄出来自己看着挺舒服的,over,摸鱼打阿尔比恩去了 -v-