感觉medium也不咋地啊。
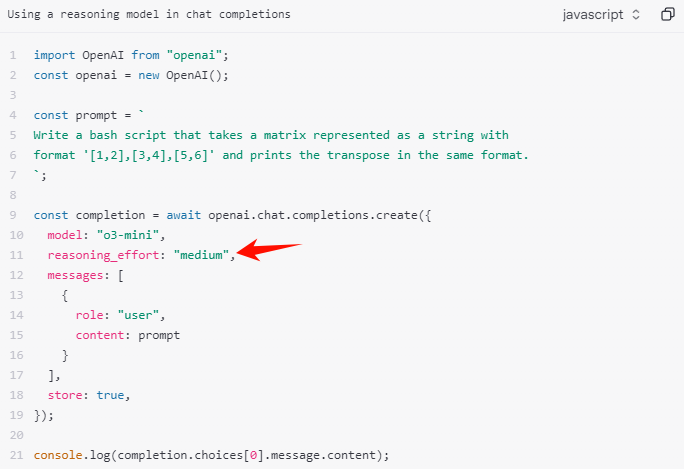
Reasoning effort
In the examples above, the reasoning_effort parameter (lovingly referred to as the “juice” during the development of these models) is used to give the model guidance on how many reasoning tokens it should generate before creating a response to the prompt. You can specify one of low, medium, or high for this parameter, where low will favor speed and economical token usage, and high will favor more complete reasoning at the cost of more tokens generated and slower responses. The default value is medium, which is a balance between speed and reasoning accuracy.