想弄一个深度学习服务器 直接买全新的太贵了 打算弄2080ti 22G * 4(或者2卡) 来跑一些深度学习的东西,但是没玩过多卡主板,这一方面属于知识盲区,求大佬给几个推荐,最好是具体型号,性价比越高越好,短期想法是跑个70B的来体验一下
12 个赞
这就不得不
@xiaolinkangna
佬没来。。 ![]()
问题不大,小林佬专业又热心,等等就好
坐等大佬
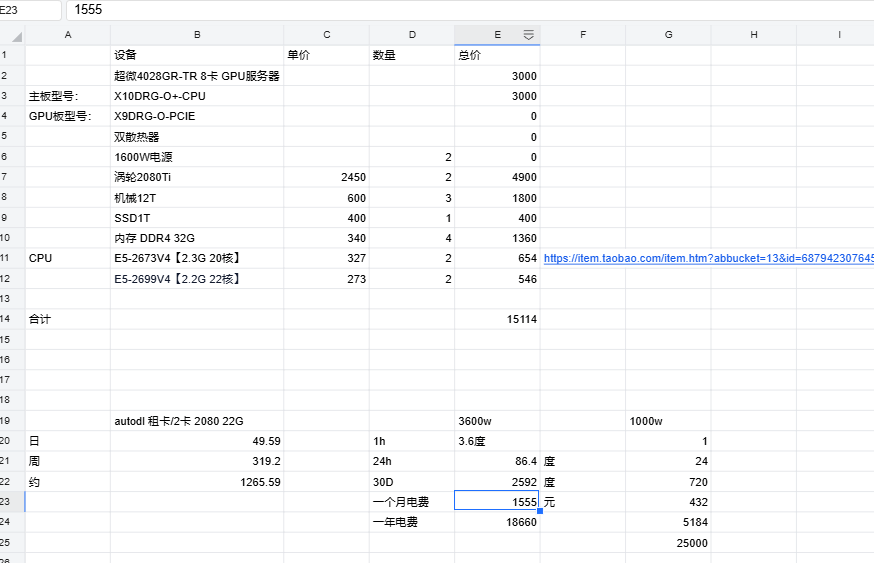
觉得真的要跑就租云,70B就丢api,可能成本还比较低
租云有点贵了,API的话会把本地一些隐私数据弄上去,不太想这样操作,本地搭70B主要是想弄一个个人的全能助理,然后再通过内网穿透的方式,跟我所有设备连在一起,试过14B和32B的,效果都不太理想,他们说个人至少要从70B开始。 当然后面不只跑70B 有些时候还需要训练一些东西
1 个赞
首先佬要明白一个问题就是4卡能run的推理显存可不是22x4=88GB啊
然后呢你要考虑下是只做推理还是训练、推理都要搞
其次还要知道每颗cpu的pcie通道数是有限的
最后建议佬如果对速度要求不那么苛刻的话,看看隔壁的mac m4(32、64G内存)的配置
emmm第一点我不是太理解,我看他们双2080ti跑70B说的都是44G,逻辑说的好像是单卡推理,双卡存储,加起来就是44G的一张2080ti,然后第二点我的想法是推理和训练都弄,第三点我也知道每颗cpu的PICE是有限的,有考虑过双U平台,第四点速度的话我其实大差不差,70B能有个5到10token就差不多了,mac m4我有考虑过,但是价格太贵了,丐版不是pro芯片,跑70B的效率太低,雷电4接口又不如pro芯片的雷电5接口,pro芯片价格又翻倍,加上内存也贵,一个48G要1W5以上了64好像2W起步
这种会很吵吗,电费的话,应该不用担心,我打算蹭公司的电 ![]() ,反正公司也有好多个服务器,跟领导说清楚,同意就好
,反正公司也有好多个服务器,跟领导说清楚,同意就好
ollama在推理过程中是支持多GPU的,但是我为什么说不能这样算呢?因为多GPU推理的时候,速度是伴随GPU数量指数下降的。多卡之间要频繁的进行device to device的操作,而这些又是完全通过pcie来实现的,进而发现因为pcie之间的io都是cpu负责的,反馈到前端命令的结果就是一个字一个字的往外蹦。
就因为这个弊端,nvidia最初在民用级gpu上搞了nvlink,后来nvlink被广泛使用在企业级gpu上(v100、a100、a800、h100等等吧)他们就是为了让cuda再做运算的时候,实现gpu——gpu之间的高速io互联,避免去用牛车一样的pcie,也不会被cpu羁绊。
假如佬你有条件可以自己试试看无nvlink环境多卡推理ollama的70b模型速度如何,我可以告诉你的就是m4-mini-64g环境ollama推理70b-4bit的r1大概是5tokens/s
Nvlink双卡70b也很卡
我觉得卡就是因为模型被ollama平均分配到2张GPU上了,而推理的时候只能是一个gpu去做运算,虽然显存没有oom,但是速度肯定是会慢的。因为原理就是需要海量的数据在两张gpu之间的pcie通道或者nvlink通道来回来去的copy
是的 个人本地部署基本没有意义
不过双卡32b 速度还行 就是 4bit 32b 到底能干吗也不好说了
最后 70b 的推理效果也很一般 完全不能当作 助理使用
本地耍一耍是可以的,学习原理,体验搭建环境的乐趣,自娱自乐还不受管控![]()
那佬,买个macmini m4 pro 24G+macmini m4 32G,这样可以通过集群调用跑70B的模型吗,我看他们说mac集群是通过雷电接口来传输数据的,但是pro是雷电5,丐版是雷电4,不太清楚能不能做到我想要的效果:m4pro芯片运算,24+32G的内存容纳70B模型
![]() 我好像,忽略了一个重要的问题,70B效果在咋样我没体验过。。32B我觉得蠢蠢的,我应该先去租一个云环境体验一下,在考虑搭建本地是用macmini还是用多卡2080ti,还是放弃这个想法
我好像,忽略了一个重要的问题,70B效果在咋样我没体验过。。32B我觉得蠢蠢的,我应该先去租一个云环境体验一下,在考虑搭建本地是用macmini还是用多卡2080ti,还是放弃这个想法
m4适合我个人验证自娱自乐,反正2-3个字/秒的推理输出速度我也能忍。用n卡跑模型推理的确比m4快,但因为我最高配置就是单卡3090,所以没法体验70b的ollama推理场景。
佬,你m4买的是pro还是丐的m4,内存多大啊