最近升到 3 级了,才发现自己有很多权利可以使用,包括AI机器人的使用,年关已过,年兽已走,投投简历,动动小手,懒惰成性,脚本来投
于是用python开发了一个批量投递脚本,并通过 linux.do AI 机器人协助完成
话又说回来,就算有了脚本又如何呢,已经痛苦了如此之久,内心早就没有了希望之火,人若没了希望和死人又有什么区别,人心隔肚皮,我又怎知,怎又知我呢,
虽说是在
macOS系统上开发的,但是实际上跨平台系统也可以使用,毕竟 webdriver 有官方提供,python 又是可以根据解释器跨平台,这不挺好吗,一个脚本到处运行。这个脚本需要本地环境中有 webdriver 驱动来启动本地浏览器以及python环境实现自动化,我觉得很复杂,我尝试描述一下怎么使用吧?
系统环境
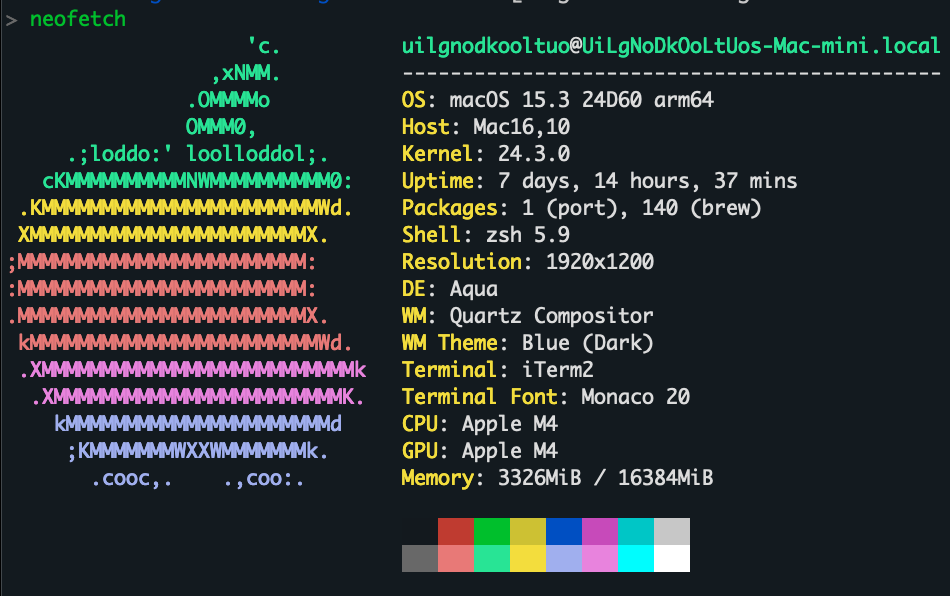
OS: macOS 15.3 24D60 arm64
Host: Mac16,10
Kernel: 24.3.0
Uptime: 7 days, 14 hours, 37 mins
Packages: 1 (port), 140 (brew)
Shell: zsh 5.9
Resolution: 1920x1200
DE: Aqua
WM: Quartz Compositor
WM Theme: Blue (Dark)
Terminal: iTerm2
Terminal Font: Monaco 20
CPU: Apple M4
GPU: Apple M4
Memory: 3326MiB / 16384MiB
通过访问 edge://version/ 查看edge浏览器的版本,134.0.3120.0
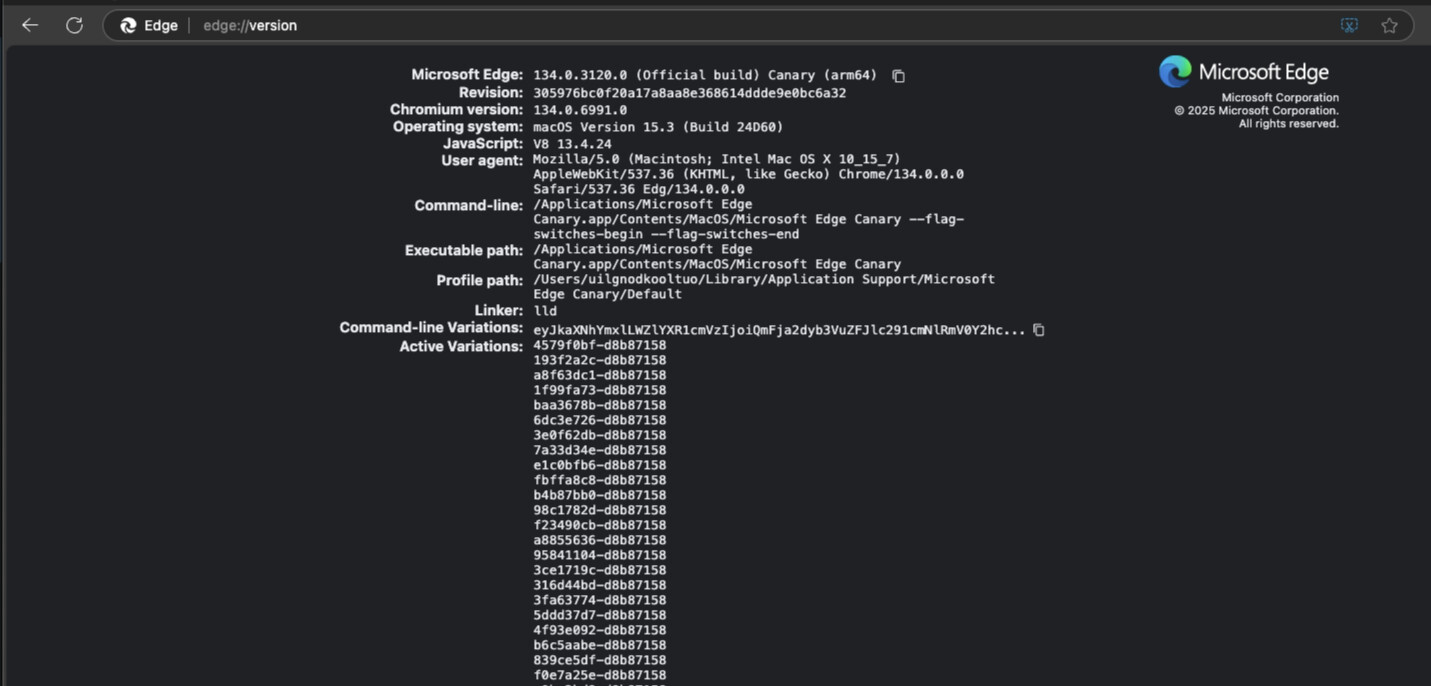
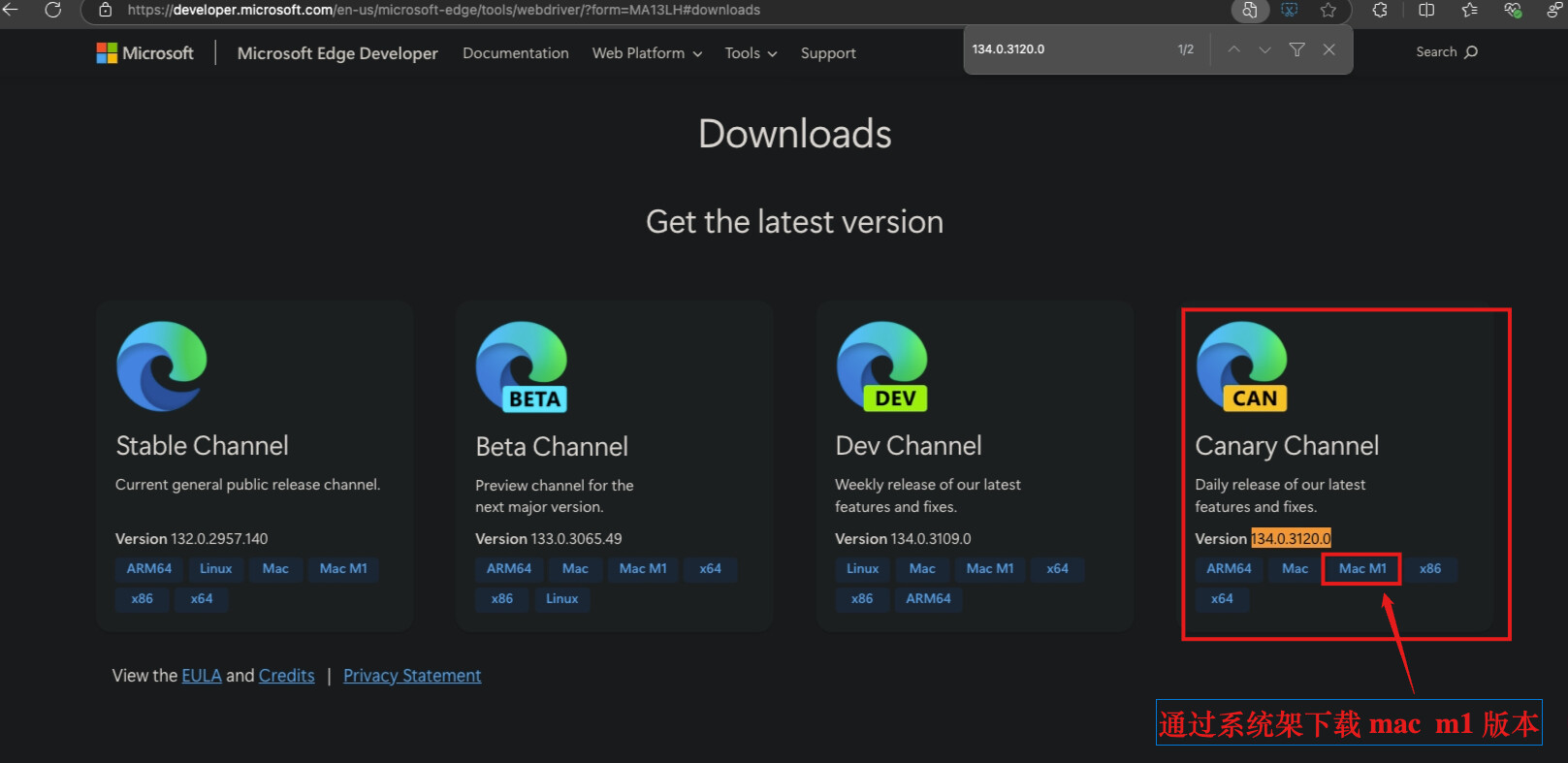
通过浏览器版本下载 edge 浏览器的 webdriver 驱动
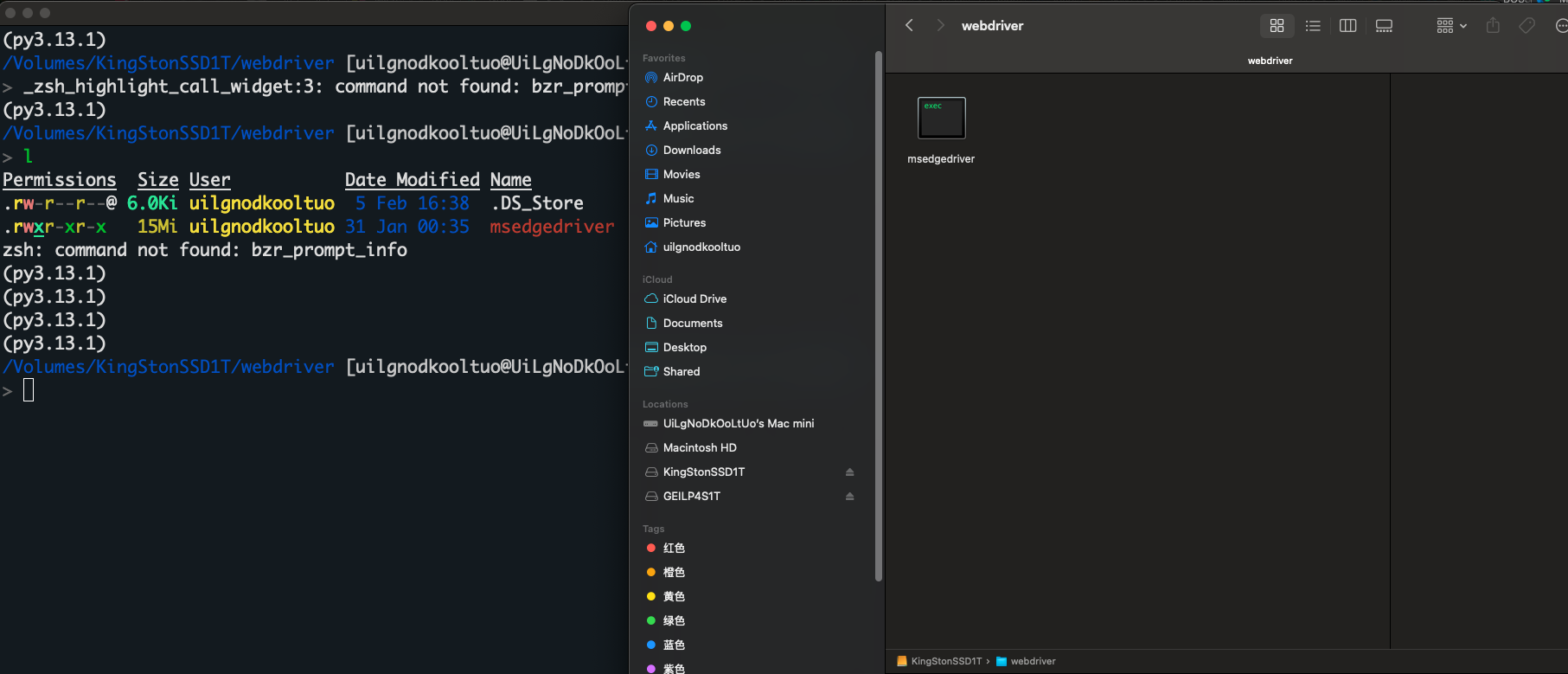
将其解压到指定目录,比如 /Volumes/KingStonSSD1T/webdriver
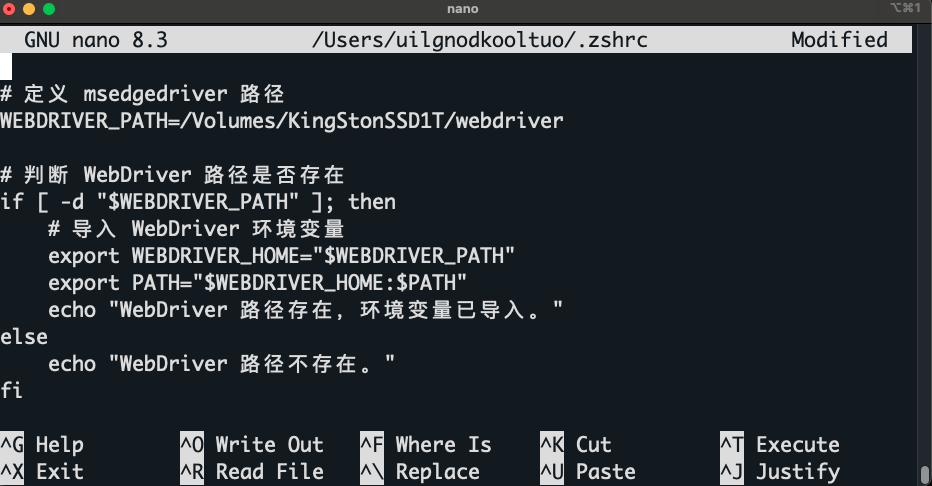
配置 zsh shell 环境变量
nano $HOME/.zshrc
在配置文件中最后一行,添加如下内容,其中
WEBDRIVER_PATH=/Volumes/KingStonSSD1T/webdriver是我自定义的路径可以自行更改
# 定义 msedgedriver 路径
WEBDRIVER_PATH=/Volumes/KingStonSSD1T/webdriver
# 判断 WebDriver 路径是否存在
if [ -d "$WEBDRIVER_PATH" ]; then
# 导入 WebDriver 环境变量
export WEBDRIVER_HOME="$WEBDRIVER_PATH"
export PATH="$WEBDRIVER_HOME:$PATH"
echo "WebDriver 路径存在,环境变量已导入。"
else
echo "WebDriver 路径不存在。"
f
为 zsh shell 更新环境变量
source $HOME/.zshrc
测试 WebDriver 驱动
msedgedriver --version
使用 boss 直聘批量自动沟通脚本
更新 pip 包管理工具,安装第三方库
# 更新 pip 工具
python -m pip install --upgrade pip
# 安装依赖包
pip install requests pandas selenium lxml
下载py脚本,或者是用下面的源代码,存储为.py文件比如 zhipin.py,完整代码如下:
import csv
import datetime
import json
import os
import time
from turtle import st
import requests
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from lxml import etree
'''
# 脚本基于 python 3.10.X 、 edge 浏览器、edge webdriver 和 edge J2TEAM-Cookie 插件
# 更新 pip 工具
python -m pip install --upgrade pip
# 安装依赖包
pip install requests pandas selenium lxml
# 下载 edge webdriver
# edge驱动版本要和浏览器版本一致否则会报错 msedgedriver --version
driver url:https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver/
# edge 浏览器版本
edge://version/
# 下载 edge 提取用户登陆 cookie 插件
j2team-cookies url:https://microsoftedge.microsoft.com/addons/detail/j2team-cookies/lmakhegealefmkbnagibiebebncemhgn?hl=en-US
# 第一次使用脚本登陆会检测 www.zhipin.com 的 .json 文件是否存在,不存在则给用户70秒扫码登录,提取cookie
# 用户可以通过插件 J2TEAM-Cookie 提取 cookie 方便在其他浏览器登录boss直聘
edge插件:J2TEAM-Cookie
'''
login_url='https://login.zhipin.com/?ka=header-login'
home_url='https://www.zhipin.com/'
# 软件测试应届 | 运维工程师 | ai标注
# jobs_name='软件测试应届'
# jobs_name='运维工程师'
jobs_name='ai标注'
# 浏览器搜索参数的链接地址 过滤条件可以自己设置再复制 url 至此
# 北京 互联网/AI->测试 类型->全职 工作经验->应届|经验不限 薪资->3~5k 学历->本科
#search_url=f'https://www.zhipin.com/web/geek/job?query={jobs_name}&city=101010100&experience=102,101°ree=203&position=100301,100309,100303,100304,100306,100310,100302,100305,100308,100307&jobType=1901&salary=403'
# 北京 互联网/AI->运维 类型->全职 工作经验->1~3年 薪资->4~8k 学历->大专|本科
#search_url=f'https://www.zhipin.com/web/geek/job?query={jobs_name}&city=101010100&experience=104°ree=203,202&position=100401,100402,100406,100410,100408,100403,100404,100405&jobType=1901&salary=404'
# 哈尔滨 自定义链接,互联网/AI->测试|运维 类型->全职 工作经验->应届生|无经验|1~3年 薪资->不限 学历->大专|本科
# search_url=f'https://www.zhipin.com/web/geek/job?city=101050100&experience=101,104,102°ree=203,202&position=100301,100309,100303,100401,100405,100402&jobType=1901'
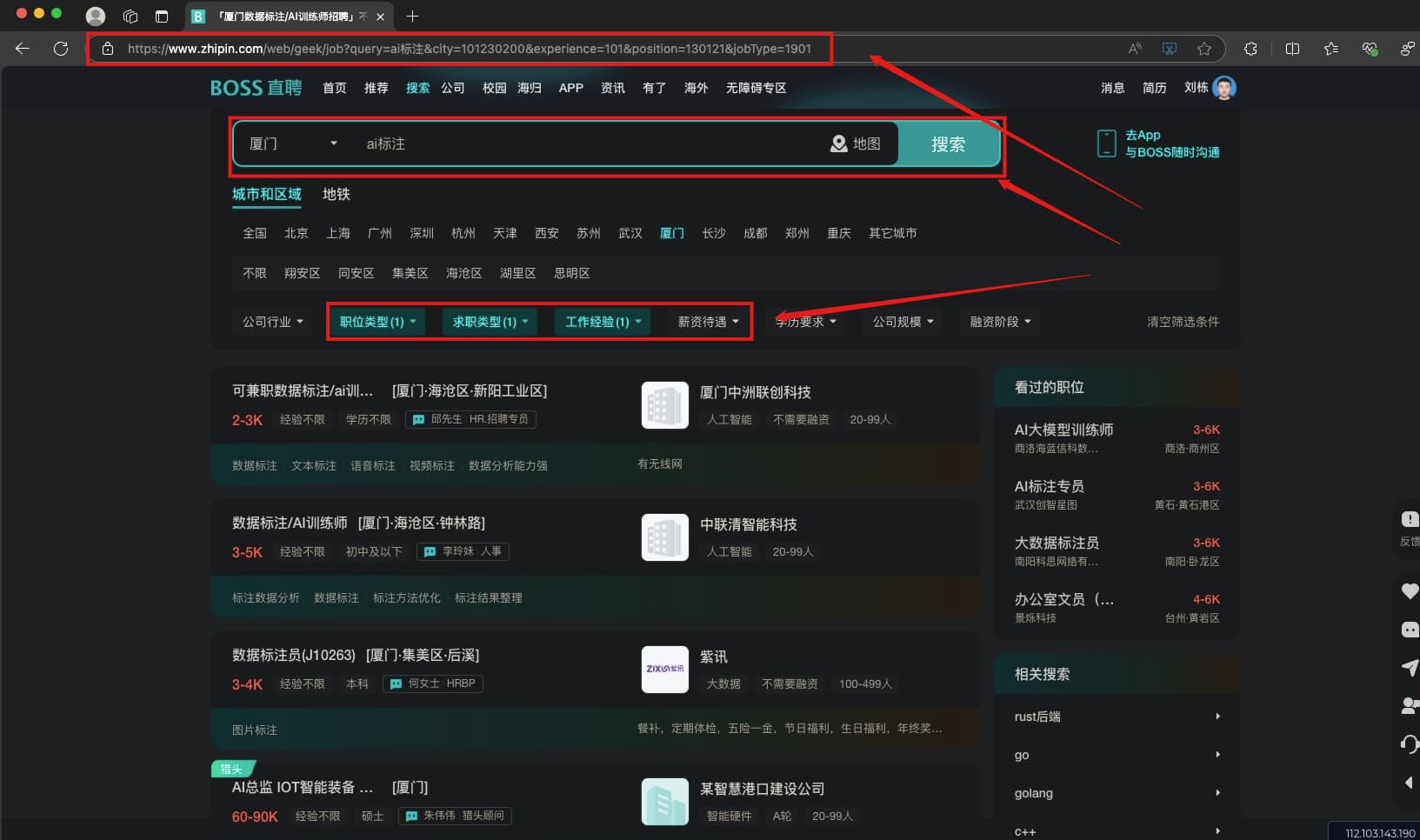
# 厦门 职位类型->不限 类型->全职 工作经验->不限经验 薪资->不限
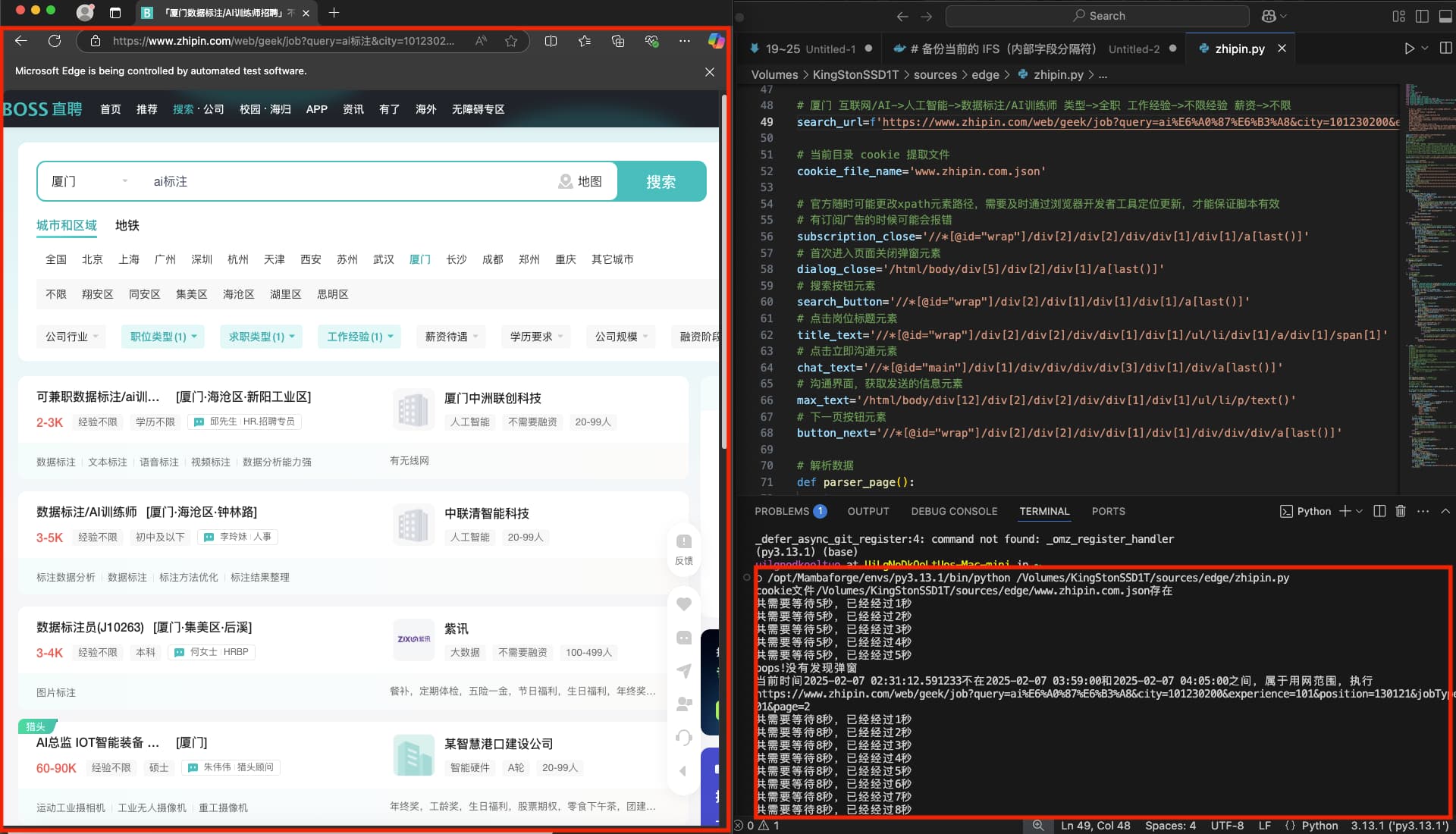
search_url=f'https://www.zhipin.com/web/geek/job?query=ai%E6%A0%87%E6%B3%A8&city=101230200&experience=101&jobType=1901'
# 当前目录 cookie 提取文件
cookie_file_name='www.zhipin.com.json'
# 官方随时可能更改xpath元素路径,需要及时通过浏览器开发者工具定位更新,才能保证脚本有效
# 有订阅广告的时候可能会导致元素错位而导致脚本报错,需要关闭,让所有元素在可控范围内
subscription_close='//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/a[last()]'
# 首次进入页面关闭无用安全或广告弹窗元素
dialog_close='/html/body/div[5]/div[2]/div[1]/a[last()]'
# 搜索按钮元素
search_button='//*[@id="wrap"]/div[2]/div[1]/div[1]/div[1]/a[last()]'
# 点击岗位标题元素
title_text='//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/ul/li/div[1]/a/div[1]/span[1]'
# 点击立即沟通元素
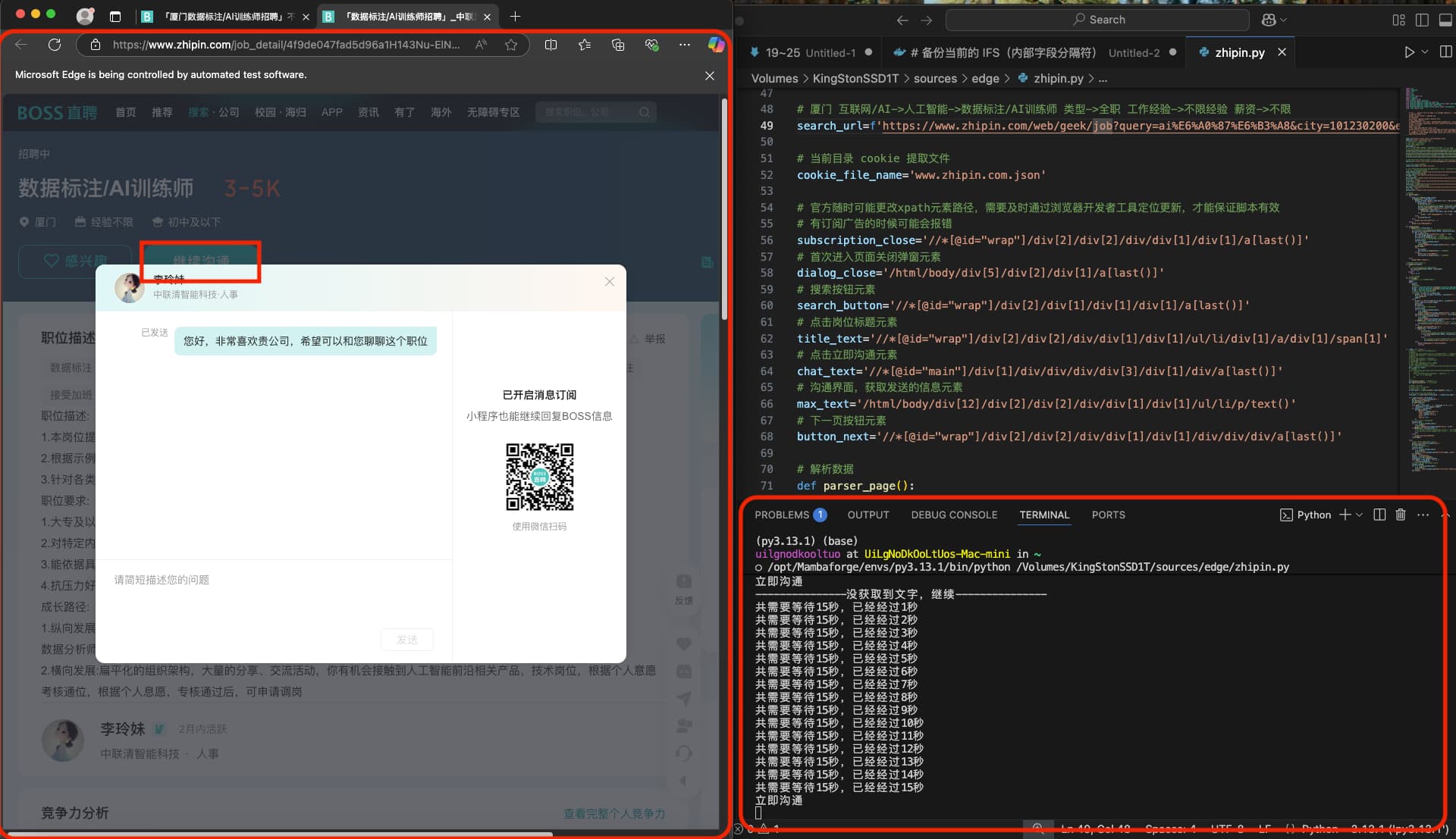
chat_text='//*[@id="main"]/div[1]/div/div/div/div[3]/div[1]/div/a[last()]'
# 沟通界面,获取发送的信息元素
head_img='/html/body/div[11]/div[2]/div[1]/h3/div/img'
max_text1_element='/html/body/div[11]/div[2]/div[1]/h3/div/div/div[1]'
max_text2_element='/html/body/div[11]/div[2]/div[1]/h3/div/div/div[2]'
# 输入框元素
input_textarea = '/html/body/div[11]/div[2]/div[2]/div/div[1]/div[2]/textarea'
# 自定义发送消息内容
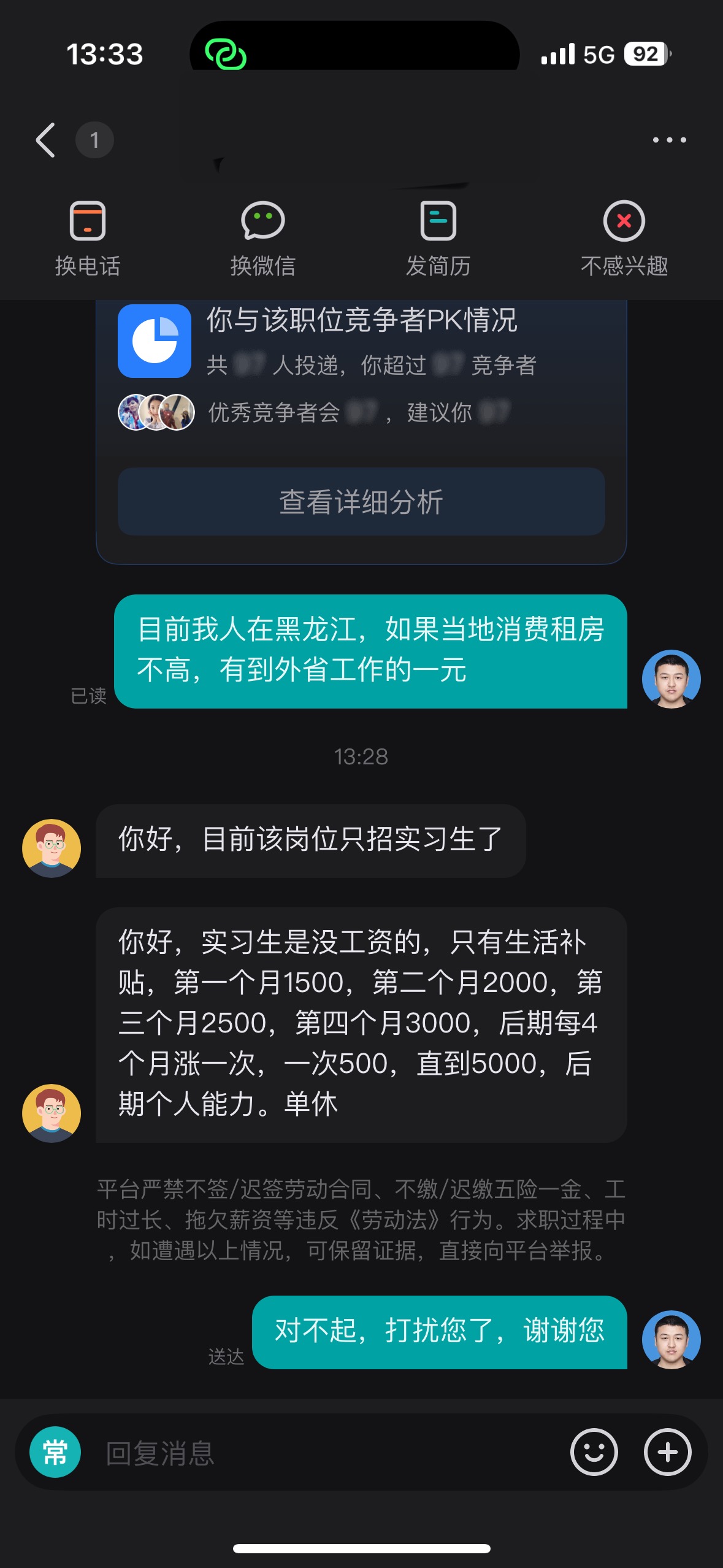
custom_info='目前我人在黑龙江,如果当地消费租房不高,有到外省工作的意愿!'
# 发送按钮元素
send_button = '/html/body/div[11]/div[2]/div[2]/div/div[1]/div[2]/div'
# 下一页按钮元素
button_next='//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[last()]'
# 解析数据
def parser_page():
try:
html = etree.HTML(bro.page_source)
# 检查有没有立即沟通按钮元素,有就点击,没有跳过
if NodeExists(f'{chat_text}'):
button_str = html.xpath(f'{chat_text}/text()')[0].strip().replace(" ", "")
if button_str == '立即沟通':
print(button_str)
div = bro.find_elements(by=By.XPATH, value=chat_text)[0]
bro.execute_script("arguments[0].click();", div)
time.sleep(2) # 增加等待时间,确保弹窗加载完毕
# 处理头像、名字、等级
try:
# 头像
if NodeExists(f'{head_img}'):
img_element = bro.find_element(by=By.XPATH, value=head_img)
img_src = img_element.get_attribute('src')
print(f'HR头像的src属性值: {img_src}')
else:
print('-'*15+'没获取到HR头像链接,继续'+'-'*15)
# 名字
if NodeExists(f'{max_text1_element}'):
name_element = bro.find_element(by=By.XPATH, value=max_text1_element)
hr_name = name_element.text.strip().replace(" ", "")
print(f'HR名字: {hr_name}')
else:
print('-'*15+'没获取到HR名字,继续'+'-'*15)
# 级别
if NodeExists(f'{max_text2_element}'):
name_element = bro.find_element(by=By.XPATH, value=max_text2_element)
hr_name = name_element.text.strip().replace(" ", "")
print(f'HR级别: {hr_name}')
else:
print('-'*15+'没获取到HR名字,继续'+'-'*15)
except Exception as e:
print(f'处理头像、名字、等级时出错: {str(e)}')
# 输入自定义内容并发送
try:
# 输入自定义沟通内容
if NodeExists(f'{input_textarea}'):
text_area = bro.find_elements(by=By.XPATH, value=input_textarea)[0]
bro.execute_script("arguments[0].click();", text_area)
text_area.send_keys(f'{custom_info}')
else:
print('-'*15+'没获取到输入框元素,无法输入自定义内容,继续'+'-'*15)
# 点击发送按钮
if NodeExists(f'{send_button}'):
send_btn = bro.find_elements(by=By.XPATH, value=send_button)[0]
bro.execute_script("arguments[0].click();", send_btn)
else:
print('-'*15+'没获取到发送按钮元素,无法点击发送自定义内容,继续'+'-'*15)
except Exception as e:
print(f'处理输入自定义内容并发送时出错: {str(e)}')
else:
print(button_str)
else:
print('oops!没有发现沟通按钮')
except Exception as e:
print(f'oops!页面解析失败, 错误信息: {str(e)}')
# 判断节点是否存在捕获异常
def NodeExists(xpath):
try:
bro.find_element(by=By.XPATH, value=xpath)
return True
except Exception as e:
print(f'元素 {xpath} 不存在,错误信息: {str(e)}')
return False
def click_title():
# 如果岗位标题元素存在,点它!
if NodeExists(f'{title_text}'):
# div_list=bro.find_elements_by_xpath(f'{title_text}')
div_list=bro.find_elements(by=By.XPATH, value=title_text)
for div in div_list:
bro.execute_script("arguments[0].click();", div)
ws = bro.window_handles # 当前所有页面
bro.switch_to.window(ws[-1]) # 切换新页面,详情页
# 让浏览器等待 15 秒刷新页面,或者可能会需要手动验证
seconds_num=15
for i in range(1,seconds_num+1):
time.sleep(1)
print(f'共需要等待{seconds_num}秒,已经经过{i}秒')
parser_page()
try:
bro.close()
bro.switch_to.window(ws[0]) # 回到列表页
except:
print('oops!尝试关闭失败')
bro.switch_to.window(ws[0]) # 回到列表页
else:
print('列表标题不存在')
# 加载拼接链接页面
def click_page(page):
'''
:param: page:传输页码的形参
:type: page:num
'''
while True:
page+=1
# 3:59~4:05 是不想联网的时间范围
d_start = datetime.datetime.strptime(str(datetime.datetime.now().date())+'3:59', '%Y-%m-%d%H:%M')
d_end = datetime.datetime.strptime(str(datetime.datetime.now().date())+'4:05', '%Y-%m-%d%H:%M')
n_time = datetime.datetime.now()
# 判断当前时间是否在不想联网的范围时间内
if n_time > d_start and n_time<d_end:
print(f'当前时间{n_time}在{d_start}和{d_end}之间,属于断网范围休息4分钟')
time.sleep(240)
page-=1
else:
print(f'当前时间{n_time}不在{d_start}和{d_end}之间,属于用网范围,执行')
url=f'{search_url}&page={page}'
print(url)
bro.get(url)
# 让浏览器等待 8 秒刷新页面
seconds_num=8
for i in range(1,seconds_num+1):
time.sleep(1)
print(f'共需要等待{seconds_num}秒,已经经过{i}秒')
# 点击搜索按钮元素,搜索
bro.execute_script("arguments[0].click();", bro.find_element(by=By.XPATH, value=search_button))
for i in range(1,seconds_num+1):
time.sleep(1)
print(f'共需要等待{seconds_num}秒,已经经过{i}秒')
# 如果是订阅元素,立刻关闭
if NodeExists(f'{subscription_close}'):
# bro.execute_script("arguments[0].click();", bro.find_elements_by_xpath(f'{subscription_close}')[0])
bro.execute_script("arguments[0].click();", bro.find_elements(by=By.XPATH, value=subscription_close)[0])
else:
print('oops!没有发现订阅广告')
# 页面分页的下一页按钮元素,如果存在点击下一页翻页
if NodeExists(f'{button_next}'):
while True:
click_title()
# 如果下一页按钮元素包含不许点击的class属性,就终止脚本循环
# if bro.find_element_by_xpath(f'{button_next}').get_attribute("class")=="disabled":
if bro.find_element(by=By.XPATH, value=button_next).get_attribute("class")=="disabled":
break
else:
# bro.execute_script("arguments[0].click();", bro.find_element_by_xpath(f'{button_next}'))
bro.execute_script("arguments[0].click();", bro.find_element(by=By.XPATH, value=button_next))
else:
print('页数走到了尽头,或者cookie失效,退出脚本循环')
break
if __name__ == "__main__":
# option = webdriver.ChromeOptions()
# 代理模式
# option.add_experimental_option('excludeSwitches', ['enable-automation']) # 开启实验性功能
# option.add_argument('--proxy-server=http://127.0.0.1:9000')
# 无头模式
# option.add_argument('--headless')
# option.add_argument('--disable-gpu')
# 不等待页面加载执行
# caps = DesiredCapabilities().CHROME
# caps["pageLoadStrategy"] ="none"
# bro = webdriver.Chrome(options=option,desired_capabilities=caps)
# 下载指定版本浏览器并执行
# bro = webdriver.Edge()
# 使用已安装的Edge浏览器
options = webdriver.EdgeOptions()
options.use_chromium = True
# 确保浏览器路径正确
browser_path = "/Applications/Microsoft Edge Canary.app/Contents/MacOS/Microsoft Edge Canary"
options.binary_location = browser_path
bro = webdriver.Edge(options=options)
# 实现规避检测
# bro.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
# "source": """
# Object.defineProperty(navigator, 'webdriver', {
# get: () => undefined
# })
# """
# })
bro.maximize_window() # 最大化浏览器
bro.implicitly_wait(5) # 浏览器等待
# 获取当前工作目录
#current_path = os.getcwd()
# 获取当前脚本所在目录
current_path = os.path.dirname(os.path.abspath(__file__))
# 拼接 cookie_file_name 文件的路径
file_path = os.path.join(current_path, f'{cookie_file_name}')
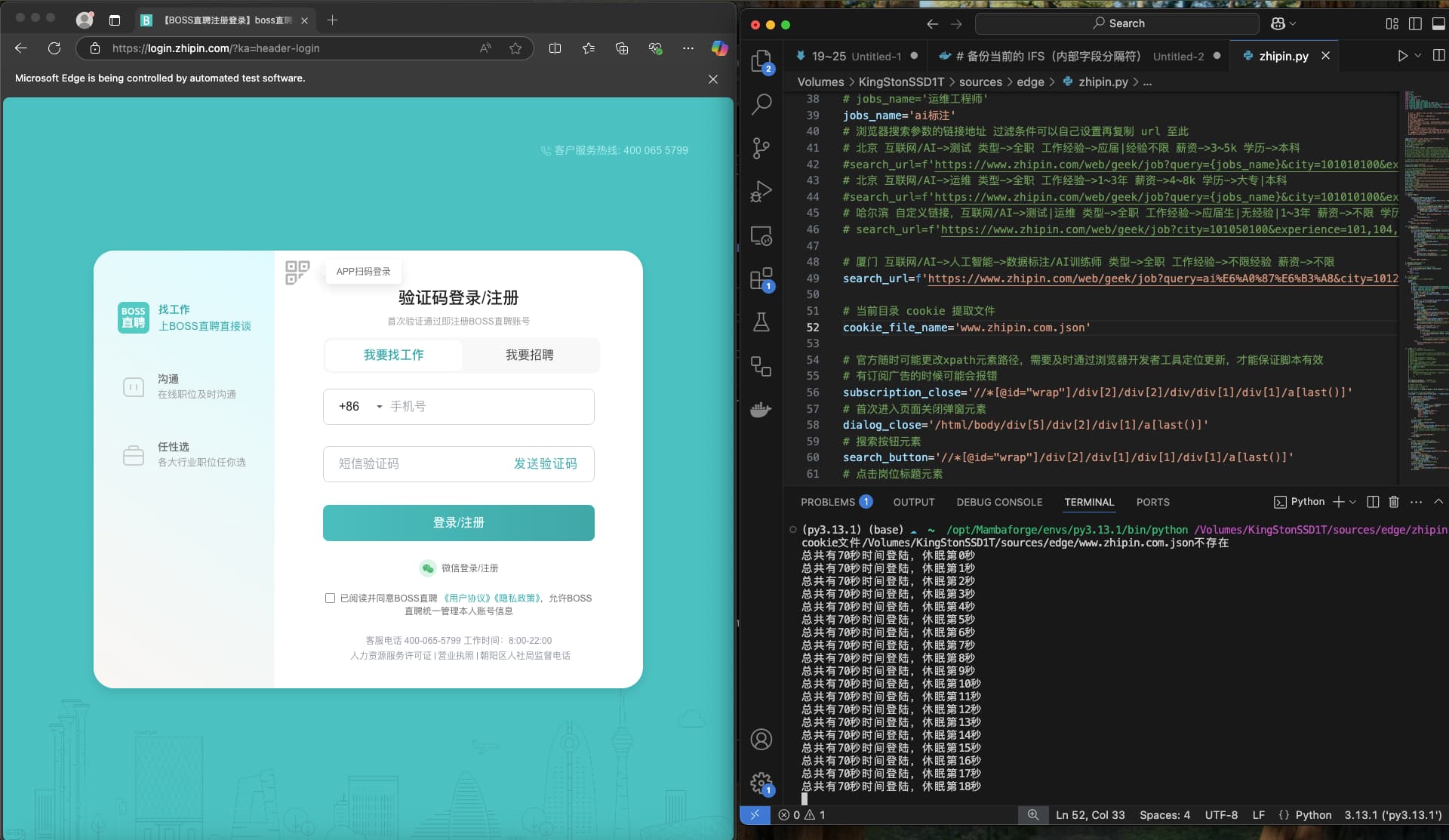
if os.path.exists(f'{file_path}'):
print(f'cookie文件{file_path}存在')
bro.delete_all_cookies()
bro.get(home_url)
# 添加使用cookie
with open(f'{file_path}', 'r', encoding='utf-8') as f:
listCookies = json.loads(f.read())
for cookie in listCookies:
bro.add_cookie({
'domain': cookie['domain'],
'name':cookie['name'],
'value':cookie['value'],
'path':'/',
'expires':None
})
# 让浏览器等待 5 秒刷新页面
seconds_num=5
for i in range(1,seconds_num+1):
time.sleep(1)
print(f'共需要等待{seconds_num}秒,已经经过{i}秒')
# 如果有弹窗元素立刻关闭
if NodeExists(f'{dialog_close}'):
# bro.execute_script("arguments[0].click();", bro.find_elements_by_xpath(f'{dialog_close}')[0])
# bro.execute_script("arguments[0].click();", bro.find_elements(by=By.XPATH, value=dialog_close)[0])
pass
else:
print('oops!没有发现弹窗')
# page 分页页码数变量初始化
# 比如,再次执行脚本,你不想从第1页从头循环点击立即沟通,就可以修改此变量
click_page(page=1)
else:
# 没有 cookie 文件,获取 cookie
print(f'cookie文件{file_path}不存在')
bro.get(login_url)
# 给用户 70 秒时间登陆
seconds_num=70
for i in range(0,seconds_num+1):
time.sleep(1)
print(f'总共有{seconds_num}秒时间登陆,休眠第{i}秒')
bro.refresh()
print('开始获取cookid')
cookies = bro.get_cookies()
jsonCookies = json.dumps(cookies)
with open(f'{file_path}', 'w') as f:
f.write(jsonCookies)
# 或者给用户 300 秒登陆提取 cookie
seconds_num=300
for i in range(0,seconds_num+1):
time.sleep(1)
print(f'总共有{seconds_num}秒时间登陆,安装 J2TEAM-Cookie 插件提取 cookie 文件,用来导入其他浏览器可以防止被本次登录顶掉,如果提取json提取成功请直接终止此过程,休眠第{i}秒')
bro.close()
新增获取HR头像,名字,等级,并允许用户发送自定义消息,这样提升代码灵活度,也增加了冗余度(对不起,我能力真的很差,有新需求直接就堆代码,这是不好的习惯)
部分新增代码如下
# 沟通界面,获取发送的信息元素
head_img='/html/body/div[11]/div[2]/div[1]/h3/div/img'
max_text1_element='/html/body/div[11]/div[2]/div[1]/h3/div/div/div[1]'
max_text2_element='/html/body/div[11]/div[2]/div[1]/h3/div/div/div[2]'
# 输入框元素
input_textarea = '/html/body/div[11]/div[2]/div[2]/div/div[1]/div[2]/textarea'
# 自定义发送消息内容
custom_info='目前我人在黑龙江,如果当地消费租房不高,有到外省工作的意愿!'
# 发送按钮元素
send_button = '/html/body/div[11]/div[2]/div[2]/div/div[1]/div[2]/div'
# 下一页按钮元素
button_next='//*[@id="wrap"]/div[2]/div[2]/div/div[1]/div[1]/div/div/div/a[last()]'
# 解析数据
def parser_page():
try:
html = etree.HTML(bro.page_source)
# 检查有没有立即沟通按钮元素,有就点击,没有跳过
if NodeExists(f'{chat_text}'):
button_str = html.xpath(f'{chat_text}/text()')[0].strip().replace(" ", "")
if button_str == '立即沟通':
print(button_str)
div = bro.find_elements(by=By.XPATH, value=chat_text)[0]
bro.execute_script("arguments[0].click();", div)
time.sleep(2) # 增加等待时间,确保弹窗加载完毕
# 处理头像、名字、等级
try:
# 头像
if NodeExists(f'{head_img}'):
img_element = bro.find_element(by=By.XPATH, value=head_img)
img_src = img_element.get_attribute('src')
print(f'HR头像的src属性值: {img_src}')
else:
print('-'*15+'没获取到HR头像链接,继续'+'-'*15)
# 名字
if NodeExists(f'{max_text1_element}'):
name_element = bro.find_element(by=By.XPATH, value=max_text1_element)
hr_name = name_element.text.strip().replace(" ", "")
print(f'HR名字: {hr_name}')
else:
print('-'*15+'没获取到HR名字,继续'+'-'*15)
# 级别
if NodeExists(f'{max_text2_element}'):
name_element = bro.find_element(by=By.XPATH, value=max_text2_element)
hr_name = name_element.text.strip().replace(" ", "")
print(f'HR级别: {hr_name}')
else:
print('-'*15+'没获取到HR名字,继续'+'-'*15)
except Exception as e:
print(f'处理头像、名字、等级时出错: {str(e)}')
# 输入自定义内容并发送
try:
# 输入自定义沟通内容
if NodeExists(f'{input_textarea}'):
text_area = bro.find_elements(by=By.XPATH, value=input_textarea)[0]
bro.execute_script("arguments[0].click();", text_area)
text_area.send_keys(f'{custom_info}')
else:
print('-'*15+'没获取到输入框元素,无法输入自定义内容,继续'+'-'*15)
# 点击发送按钮
if NodeExists(f'{send_button}'):
send_btn = bro.find_elements(by=By.XPATH, value=send_button)[0]
bro.execute_script("arguments[0].click();", send_btn)
else:
print('-'*15+'没获取到发送按钮元素,无法点击发送自定义内容,继续'+'-'*15)
except Exception as e:
print(f'处理输入自定义内容并发送时出错: {str(e)}')
else:
print(button_str)
else:
print('oops!没有发现沟通按钮')
except Exception as e:
print(f'oops!页面解析失败, 错误信息: {str(e)}')
# 判断节点是否存在捕获异常
def NodeExists(xpath):
try:
bro.find_element(by=By.XPATH, value=xpath)
return True
except Exception as e:
print(f'元素 {xpath} 不存在,错误信息: {str(e)}')
return False
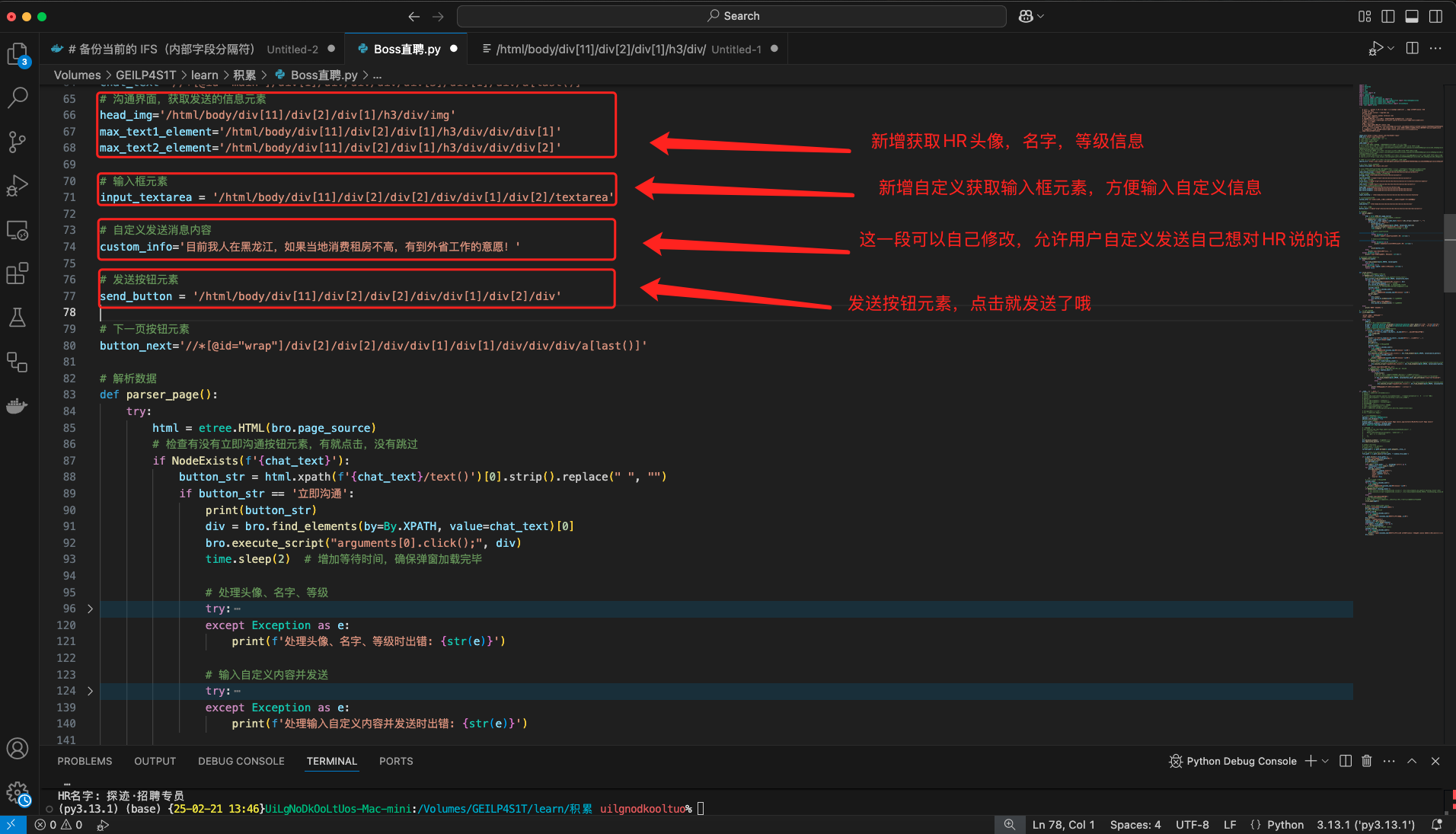
你可以找到并自定义修改
custom_info发送内容变量,来说出想对hr说出的心里话
# 自定义发送消息内容
custom_info='目前我人在黑龙江,如果当地消费租房不高,有到外省工作的意愿!'
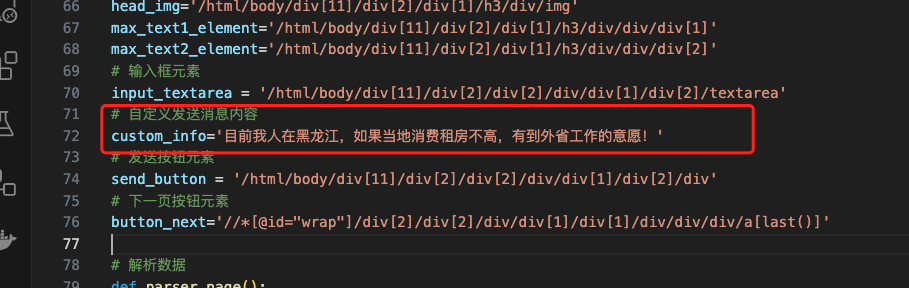
新增允许用户手动指定浏览器路径
可以按照需要解除部分代码注释,你可以找到并自定义修改
browser_path浏览器路径变量实现,部分代码如下
# 下载指定版本浏览器并执行
# bro = webdriver.Edge()
# 使用已安装的Edge浏览器
options = webdriver.EdgeOptions()
options.use_chromium = True
# 确保浏览器路径正确
browser_path = "/Applications/Microsoft Edge Canary.app/Contents/MacOS/Microsoft Edge Canary"
options.binary_location = browser_path
bro = webdriver.Edge(options=options)
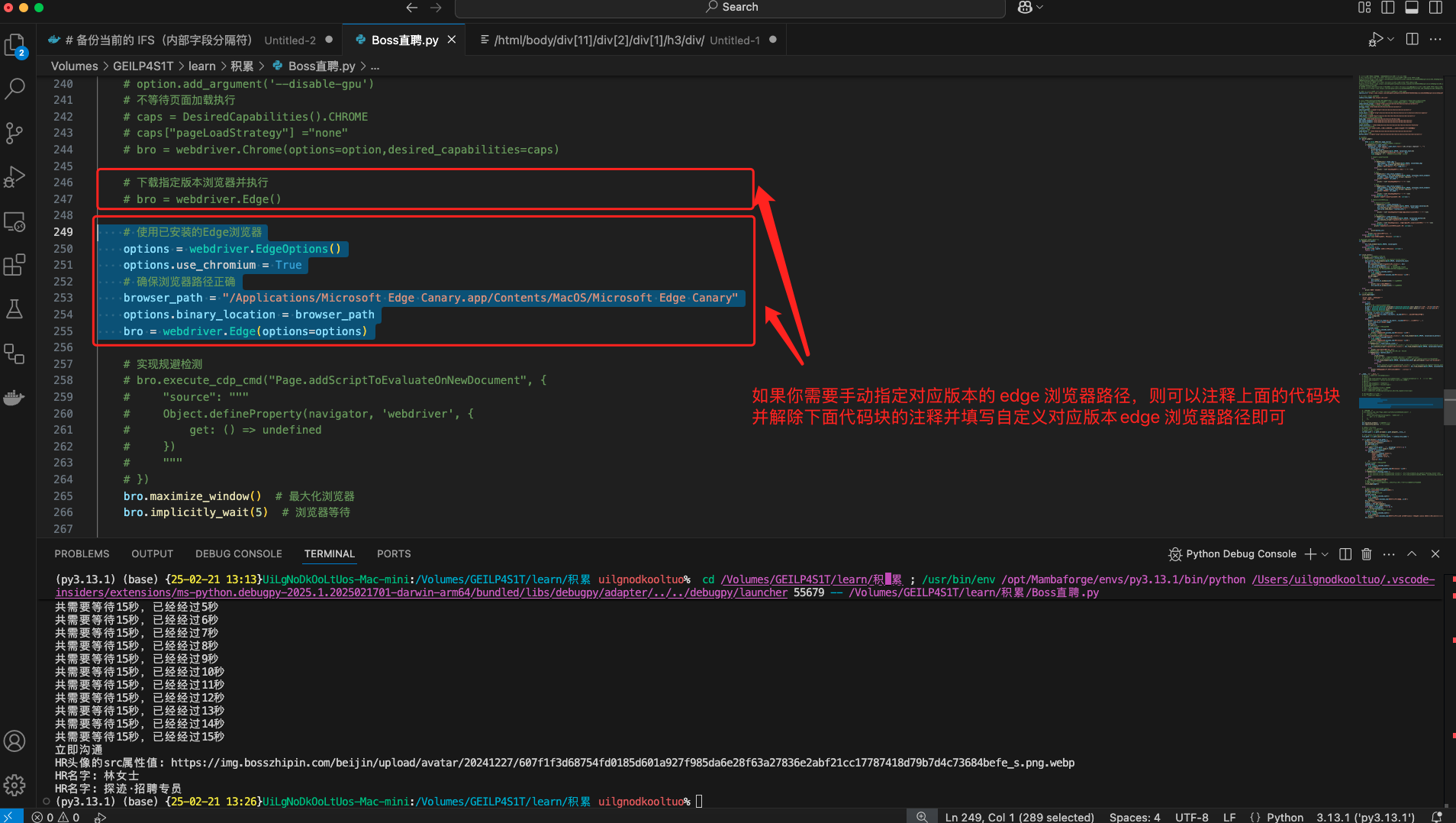
你也可以不做任何修改,可以按照需要解除部分代码注释实现,部分代码如下
# 下载指定版本浏览器并执行
bro = webdriver.Edge()
# 使用已安装的Edge浏览器
#options = webdriver.EdgeOptions()
#options.use_chromium = True
# 确保浏览器路径正确
#browser_path = "/Applications/Microsoft Edge Canary.app/Contents/MacOS/Microsoft Edge Canary"
#options.binary_location = browser_path
#bro = webdriver.Edge(options=options)
修改脚本找工作的链接
打开浏览器,登陆boss直聘
搜索职位,并找自己喜欢的地区,岗位,类型,经验,薪资 并复制链接比如 职位
ai标注厦门职位类型->不限类型->全职工作经验->不限经验薪资->不限得到链接
https://www.zhipin.com/web/geek/job?query=ai%E6%A0%87%E6%B3%A8&city=101230200&experience=101&jobType=1901
修改脚本中的链接参数
search_url替换刚才得到的链接

执行脚本
python zhipin.py
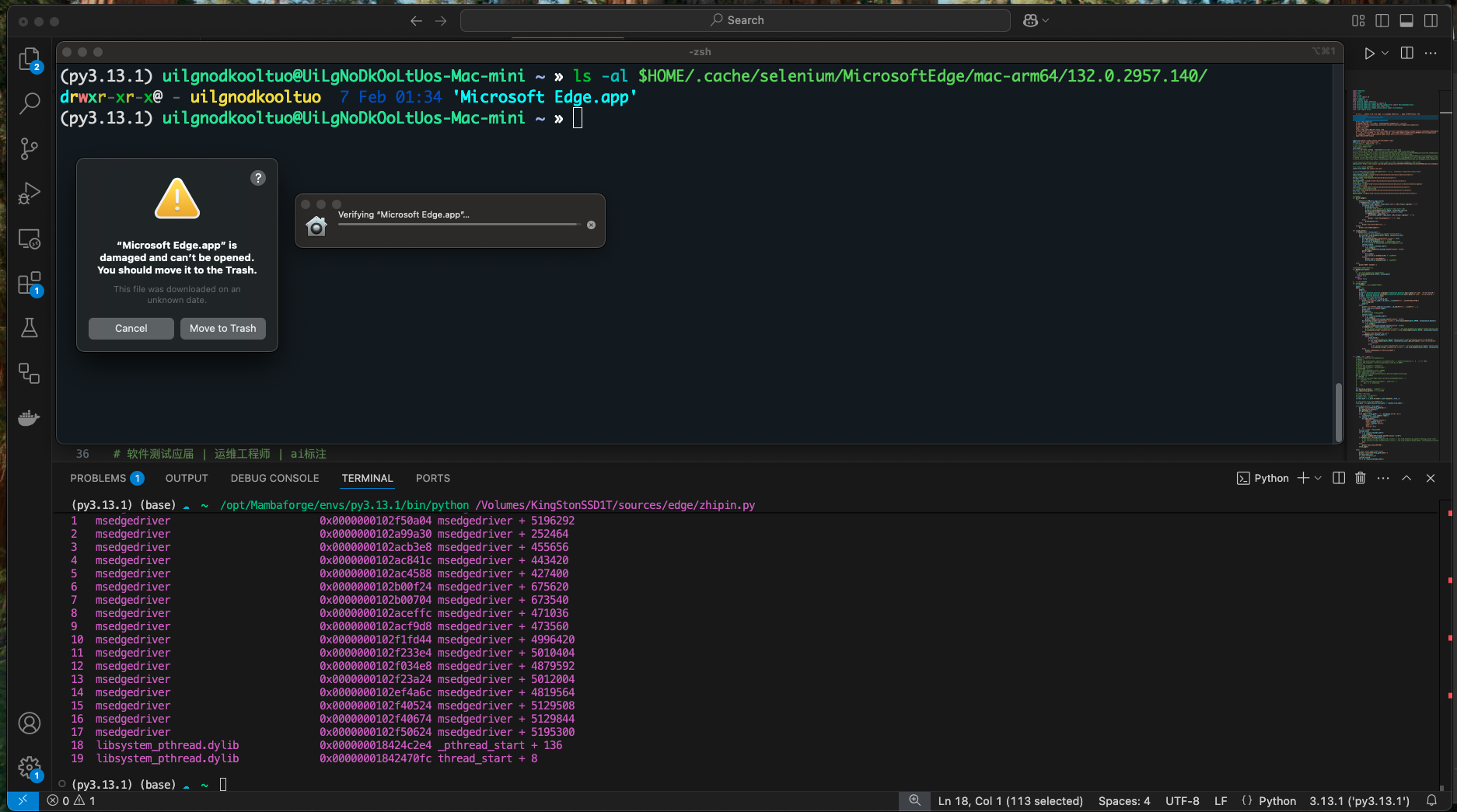
执行脚本时 selenium 会下载对应版本的 edge 浏览器 app 到
$HOME/.cache/selenium/MicrosoftEdge/mac-arm64/缓存路径
macOS有个特点,就是遇到新的app就会校验,校验不通过就会提示删除,并且终端也会报错,请点击cannel取消
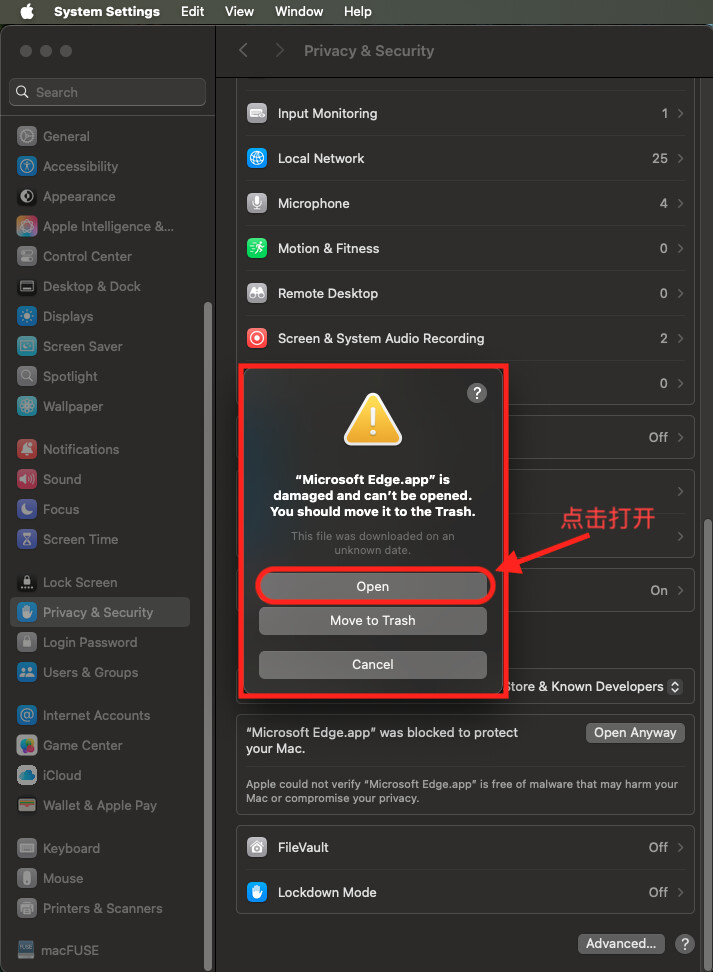
此时点击
System Settings→Privacy & Security→Security找到 新的 app 提示,点击始终打开Open Anyway
会弹出提示,是否打开,选择打开
open
会弹出密码框让用户再次确认,输入密码点击
ok
此时,会有一个全新的 edge 浏览器打开,连按两次快捷键
command + Q退出即可
此时再执行脚本,应该就没问题了


脚本运行说明
脚本第一次执行后,会给用户70秒时间登陆
然后70秒结束就会从登陆页面获取cookie存储为
www.zhipin.com.json文件
随后会给用户300秒的时间,下载安装 J2TEAM Cookies插件
导出 cookie 保存为文件,这个文件可以随时通过 J2TEAM Cookies插件 导入,这样在关闭脚本之后可以使用这个 cookie 文件将boss直聘登录信息恢复到已经被顶掉的正常浏览器中,就不用在反复扫码登录了,这段操作300秒够用了,300秒之后脚本会自动退出

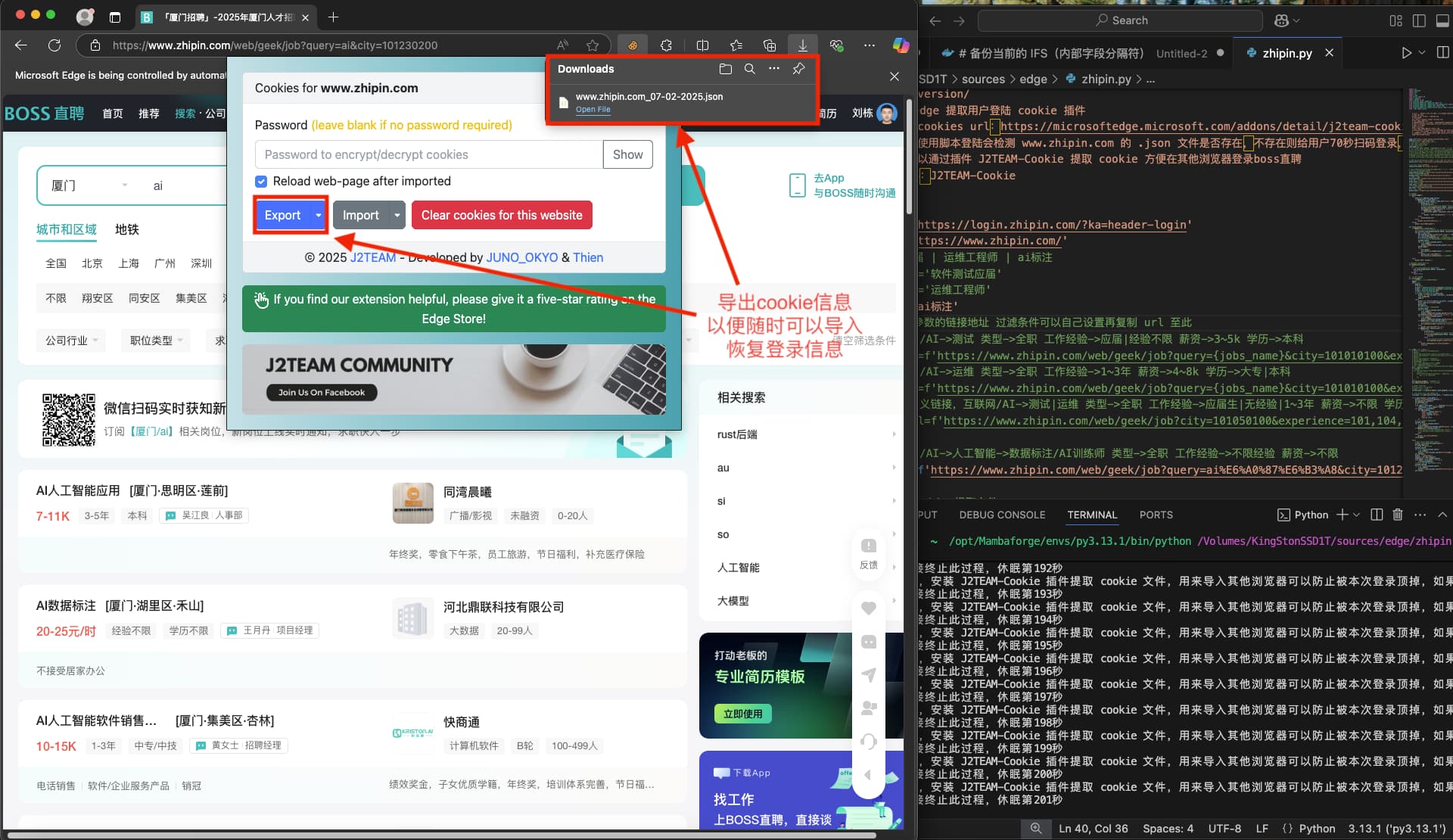
再次执行脚本,脚本会检测自己保存的
cookie文件www.zhipin.com.json是否存在,并加载登录信息,然后就可以自动化简历沟通了
我觉得,这样就满足了我对批量立即沟通的需求,只要能引起人事的反应就行
这个脚本肯定有更高的优化空间,不过目前就够用了
python zhipin.py