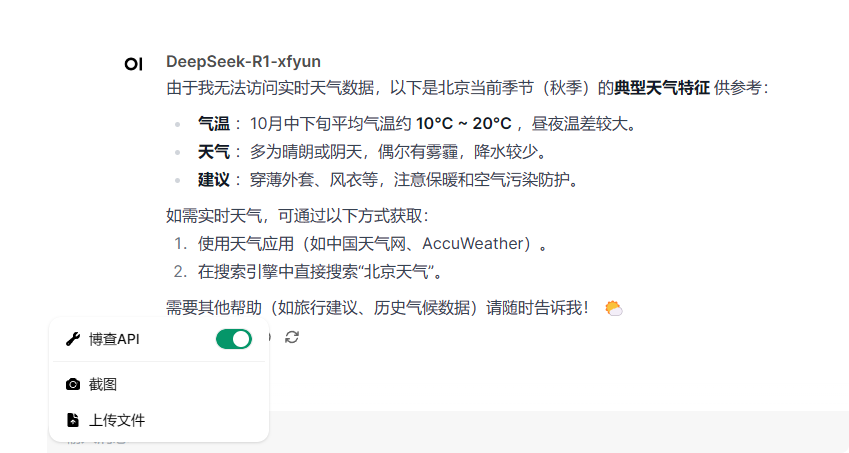
- 速度其实还可以
- 我不是博查的人,不是来给他们打广告的!部署AI服务只是自用的,要不是OpenWebUI自带联网方案介入后的都卡的一笔(我都试过了),我肯定不用博查,他们是不是应该给我打钱啊

- 效果如上图所示,只是照着开源社区模板改的代码,保证实现基本的功能,没有什么折叠展示网页之类的花里胡哨的效果,如果有大佬会做的话,发出来我肯定抄了

- 不支持流式传输,所以配置中的那个开关目前不能开启
1.0.1 更新:通过参考R1思考过程,重新整理了传递给AI的数据格式,可以避免很多不必要的无效思考(一直在纠结一些数据格式上的事情)
还是不知道怎么折叠展示url,有方法的话欢迎踢我一脚
开源社区代码连接
Web Search using Bocha Search API Tool | Open WebUI Community
工具代码1.0.1
"""
title: Web Search using Bocha Search API
author: windbylocus (基于原有代码 https://openwebui.com/t/velepost/bing_web_search 适配)
funding_url: https://api.bochaai.com
version: 1.0.1
license: MIT
"""
import os
import requests
import json
from pydantic import BaseModel, Field
import asyncio
from typing import Callable, Any
class HelpFunctions:
def __init__(self):
pass
def get_base_url(self, url):
parsed_url = urlparse(url)
base_url = f"{parsed_url.scheme}://{parsed_url.netloc}"
return base_url
def generate_excerpt(self, content, max_length=200):
return content[:max_length] + "..." if len(content) > max_length else content
def format_text(self, original_text):
soup = BeautifulSoup(original_text, "html.parser")
formatted_text = soup.get_text(separator=" ", strip=True)
formatted_text = unicodedata.normalize("NFKC", formatted_text)
formatted_text = re.sub(r"\s+", " ", formatted_text)
formatted_text = formatted_text.strip()
formatted_text = self.remove_emojis(formatted_text)
return formatted_text
def remove_emojis(self, text):
return "".join(c for c in text if not unicodedata.category(c).startswith("So"))
def process_search_result(self, result, valves):
title_site = self.remove_emojis(result["name"])
url_site = result["url"]
snippet = result.get("snippet", "")
if valves.IGNORED_WEBSITES:
base_url = self.get_base_url(url_site)
if any(
ignored_site.strip() in base_url
for ignored_site in valves.IGNORED_WEBSITES.split(",")
):
return None
try:
response_site = requests.get(url_site, timeout=20)
response_site.raise_for_status()
html_content = response_site.text
soup = BeautifulSoup(html_content, "html.parser")
content_site = self.format_text(soup.get_text(separator=" ", strip=True))
truncated_content = self.truncate_to_n_words(
content_site, valves.PAGE_CONTENT_WORDS_LIMIT
)
return {
"title": title_site,
"url": url_site,
"content": truncated_content,
"snippet": self.remove_emojis(snippet),
}
except requests.exceptions.RequestException as e:
return None
def truncate_to_n_words(self, text, token_limit):
tokens = text.split()
truncated_tokens = tokens[:token_limit]
return " ".join(truncated_tokens)
class EventEmitter:
def __init__(self, event_emitter: Callable[[dict], Any] = None):
self.event_emitter = event_emitter
async def emit(self, description="Unknown State", status="in_progress", done=False):
if self.event_emitter:
await self.event_emitter(
{
"type": "status",
"data": {
"status": status,
"description": description,
"done": done,
},
}
)
# 新增部分:Bocha AI 对接代码
# 在 Tools.Valves 中增加新的配置参数,例如搜索数量
class Tools:
class Valves(BaseModel):
BOCHA_API_ENDPOINT: str = Field(
default="https://api.bochaai.com/v1/ai-search",
description="The endpoint for Bocha AI Search API",
)
BOCHA_API_KEY: str = Field(
default="YOUR_BOCHA_API_KEY",
description="Your Bocha AI Search API key",
)
FRESHNESS: str = Field(
default="noLimit",
description="Freshness parameter for Bocha AI Search",
)
ANSWER: bool = Field(
default=False,
description="Whether to include AI-generated answer",
)
STREAM: bool = Field(
default=False,
description="Whether to use streaming response",
)
CITATION_LINKS: bool = Field(
default=False,
description="If True, send custom citations with links",
)
SEARCH_COUNT: int = Field(
default=10,
description="Number of search results to return",
)
def __init__(self):
self.valves = self.Valves()
async def search_bocha(
self,
query: str,
__event_emitter__: Callable[[dict], Any] = None,
) -> str:
"""
使用 Bocha AI Search API 进行搜索
:param query: 搜索查询关键词
:return: 返回 JSON 格式的搜索结果,附加搜索到的网页链接数量及链接列表
"""
emitter = EventEmitter(__event_emitter__)
await emitter.emit(f"Initiating Bocha AI search for: {query}")
api_url = self.valves.BOCHA_API_ENDPOINT
headers = {
"Authorization": f"Bearer {self.valves.BOCHA_API_KEY}",
"Content-Type": "application/json",
}
payload = {
"query": query,
"freshness": self.valves.FRESHNESS,
"answer": self.valves.ANSWER,
"stream": False, # 固定为非流式传输
"count": self.valves.SEARCH_COUNT, # 新增搜索数量参数
}
try:
await emitter.emit("开始搜索......")
resp = requests.post(api_url, headers=headers, json=payload, timeout=120)
resp.raise_for_status()
data = resp.json()
# 新增的处理逻辑
source_context_list = []
counter = 1
if "messages" in data:
for msg in data["messages"]:
if (
msg.get("role") == "assistant"
and msg.get("type") == "source"
and msg.get("content_type") == "webpage"
):
try:
content_obj = json.loads(msg.get("content", "{}"))
if "value" in content_obj and isinstance(
content_obj["value"], list
):
for item in content_obj["value"]:
url = item.get("url", "")
snippet = item.get("snippet", "")
summary = item.get("summary", "")
name = item.get("name", "")
siteName = item.get("siteName", "")
source_context_list.append(
{
"source_id": f"{counter}",
"source_title": name,
"siteName": siteName,
"source_link": url,
"content": snippet + "\n" + summary,
}
)
counter += 1
except json.JSONDecodeError:
pass
data["source_context"] = source_context_list
await emitter.emit(
status="complete",
description=f"搜索完毕,搜索到 {len(source_context_list)} 个网页链接",
done=True,
)
return json.dumps(data["source_context"], ensure_ascii=False)
except requests.exceptions.RequestException as e:
error_details = {"error": str(e), "headers": headers, "payload": payload}
await emitter.emit(
status="error",
description=f"Error during Bocha AI search: {json.dumps(error_details, indent=2)}",
done=True,
)
return json.dumps(error_details, ensure_ascii=False)
导入方法:
和函数类似,添加工具,粘贴代码,设置key即可
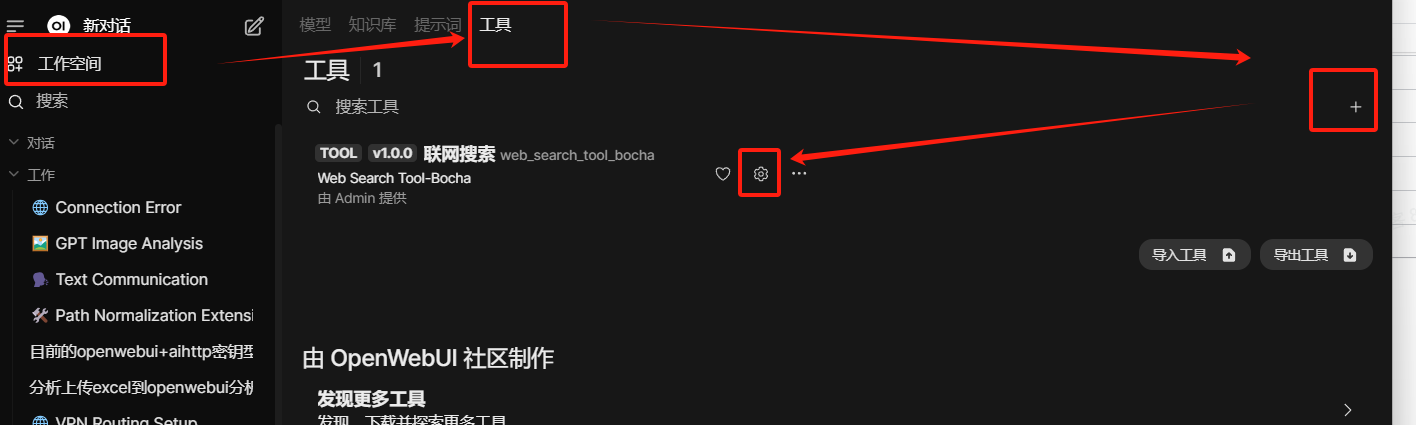
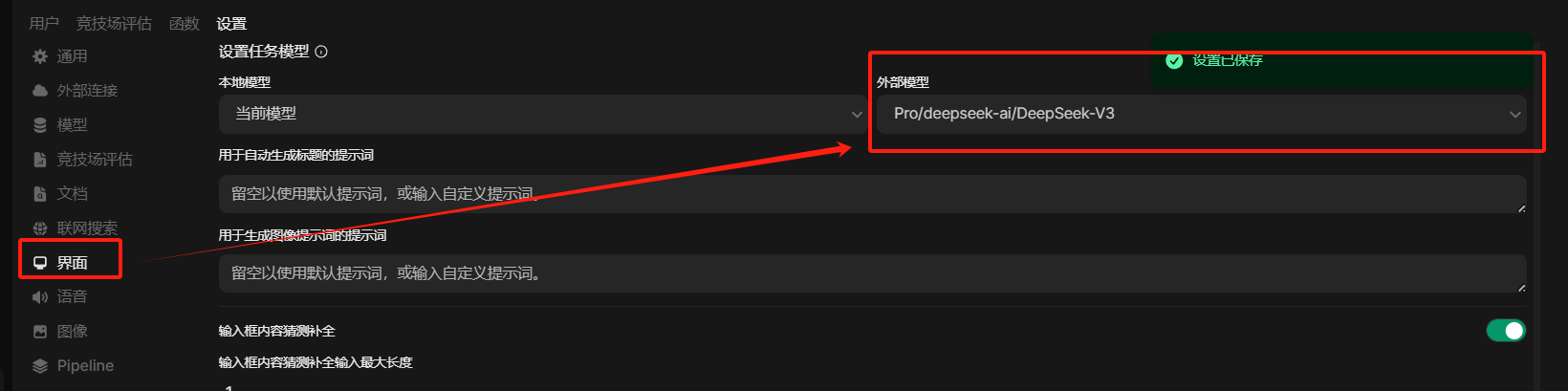
如果搜索慢、无法搜索,可能是需要设置一个具体的外部模型。主要用于解析搜索关键字的(且此模型解析速度不能太慢)。来自: