yiwu
(疑无)
1
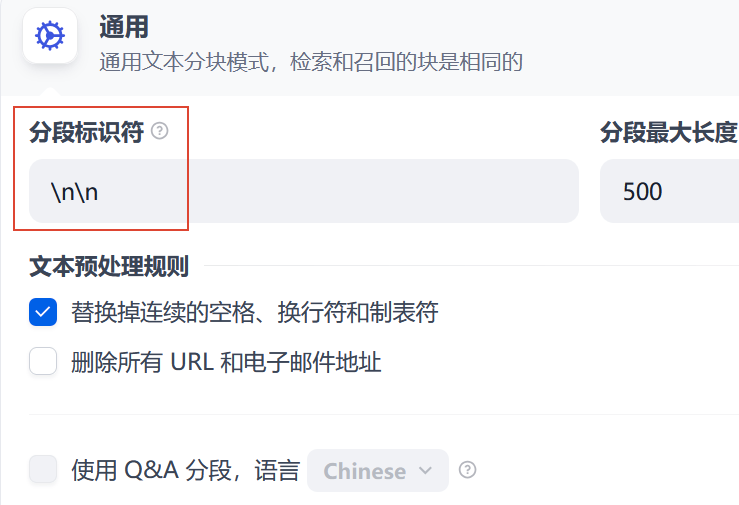
最近在研究自建在线 RAG,目前把 fastgpt, dify, ragflow 都试了试,发现 dify 在导入文档时有一个大坑。以 诡秘之主 小说全本 txt 为例,如下图:
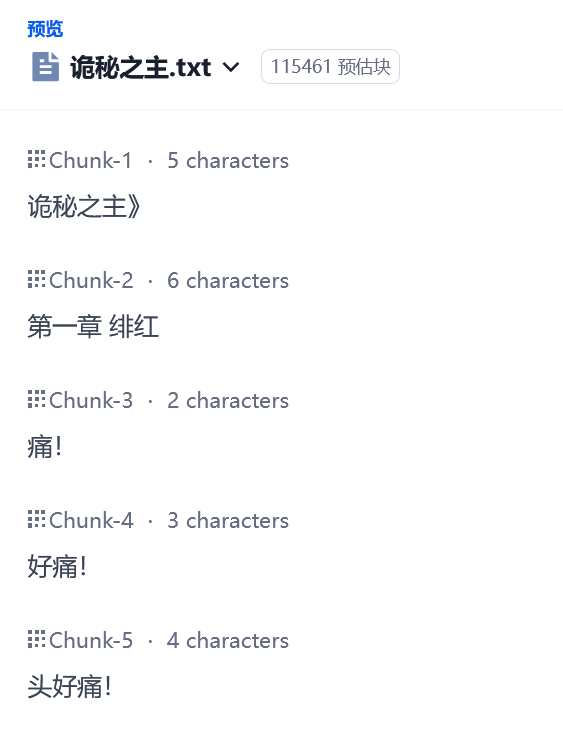
如果这里“分段标识符”按照默认选择"\n\n“,那么分块会出现这样的:
对你没看错,就算选了 500 tokens 的块,由于小说文件里这几句话后面连续\n,所以它们每个都单独分块了。什么概念呢?如果这时候我以"痛“为关键词搜索知识库,那么排名前三相关的取回结果大概率就是”痛!好痛!头好痛!“这三个块没有任何上下文!实际上在另一个库里我已经遇到了这个非常难绷的现象,按一个角色名字取回数据,返回10个块8个里头都只有这个人的名字

基本没取回什么有用的东西。
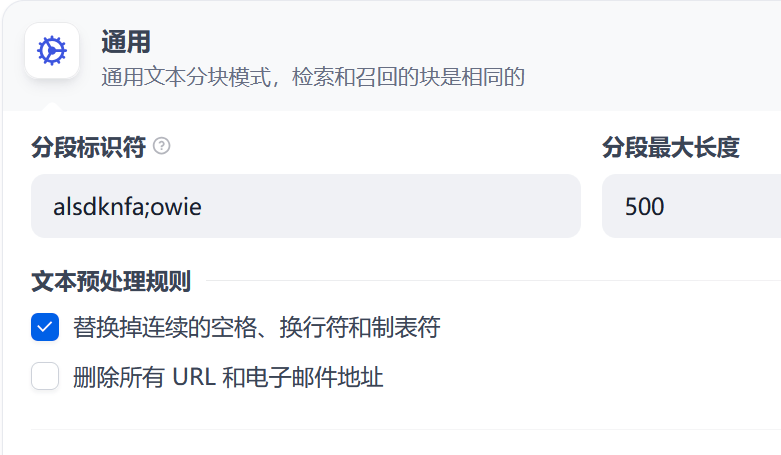
反之,我们把这个劳什子”分段标识符“换成滚键盘获得的任意字符串比如:
就会获得合理得多的分块:
实测这时候取回的质和量已经跟 fastgpt 相当(不完全一样,有很多重合,而且剩下的也都合理)。
我也不知道说什么好。。。大概 dify 开发组觉得这个默认的分段标识是个好主意吧 
再补充一件事:fastgpt 的默认分块大小是理想 512,而 dify 的默认分块大小是最大 500。实际上 fastgpt 每一块基本上都比 512 更大,比如举例的这本小说差不多每一块都是 700 多,而 dify 这本小说每一块也就不到 400。建议大家模型允许的情况下把分块大小调高一些,这样每次模型才能拿到更多的参考信息。
60 个赞
user792
(muyuan)
2
靠,原来还有这么个bug,不过话说这个知识库怎么给他利用起来
4 个赞
也不算bug吧,不过rag就这点不好,没有一个通用的分块算法,分块的好坏直接决定了最后检索的质量
8 个赞
yiwu
(疑无)
5
不算 bug 但我觉得是一个很奇怪的设计,按我理解 ai 每次都只能取到几块内容,尽可能提高每一块的内容密度才是正确的做法。它这样设计可能是想利用自然段落提高每一块内容的相关性,但我觉得这对 LLM 来说价值不大,反而是因此损失的信息却常常造成严重问题,很多时候获取结果根本就不可用。
3 个赞
Yusheng
(Yusheng)
8
这几天我都在折腾这个 dify,对比 ragflow,我觉得他的整体回答和使用是最好的,可能是我不会用 ragflow。我用的 csv 格式的,一行一条数据,每组数据有个明显的的规律就是都有同名的一列,比如a 这个列里,同名有 64 行。后续在 dify 进行默认的分块时,分列的没有问题,但是使用他的 agent 进行检索的时候,他又只能回答 4 行数据,明明符合条件的有 64 行,目前我还没有找到为什么会这样的原因(尝试过他的父子分块逻辑)。我打算换成微乳的那个 graphrag 看看,不知道效果会不会好
2 个赞
qtls
9
dify 好像聊天体验不太好?之前用的时候代码拷贝似乎很麻烦
1 个赞
yiwu
(疑无)
12
是不是因为 top_k 设置的是 4?默认 top_k 好像就是 4,最大是 10,配置文件里可能能改更大。
Yusheng
(Yusheng)
13
我试着修改topk,然后确实返回的结果变大了,但是最高就这么多,实际能匹配的应该要有64行才对。修改哪个变量哇
Yusheng
(Yusheng)
18
哎~大家都一起整吧,自己研究,摸石头过河。你可以去研究研究微软的graphrag,针对非结构化数据的清洗梳理很不错。然后可以配合dify进行工作流,形成可用的agent