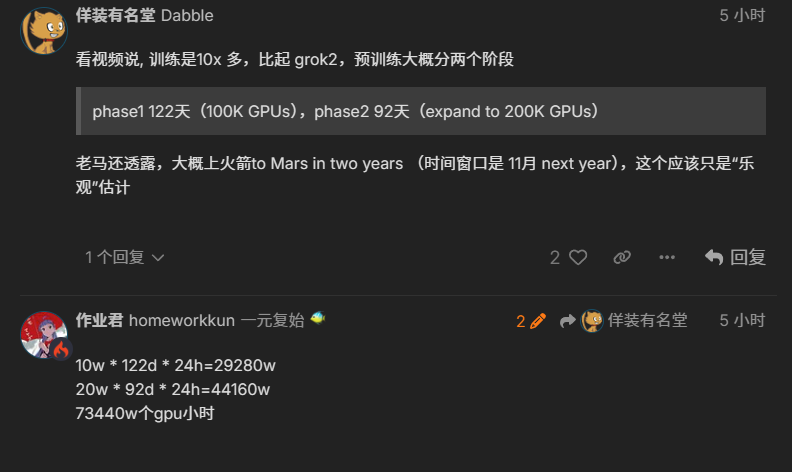
虽然gork 3看上去确实是比其他模型强,但也就强了20分左右?换算下来也就1%左右的差距啊,这个实际体感真的能感觉出来吗?或者说对大多数人能感觉出来吗?
不论是之前周树人的问题,还是一些脑静急转弯,这个测智商最起码是有目共睹的,但是现在的模型做一些高精尖的问题都没什么太大问题了吧?那现在这些提升是提升了些什么?更会做题了?那这样的话,总感觉马斯克用了数以万计的成本,纯粹的力大砖飞,就好像培养出了一个小镇做题家?
而且算法和架构上有什么创新吗?好歹deepseek最起码能让人眼前一亮啊,没有吹deepseek的意思,只是感觉大家都是老一套,老一套也行,可是这么大的资本砸下去也没能带来什么质变?
当然,不排除砸着砸着就出质变了,但是就目前这种情况,这种以微不足道的踩头式宣发真的有必要吗 
————————————————————————
说一点题外话,我真的很好奇,吃了这么多,什么时候ai能反哺人类?
或者,说的科幻一点,抛开伦理不谈,如果可控,ai什么时候能出现自主意识?
感觉ai距离我想象中的越来越远了,变得像一个工具了,本来还期待会发生工业革命类型的巨变,但是感觉还是很远
32 个赞
Candy
(Candy)
5
不针对观点发表看法,说一点:这个分数
不是 做同一套试卷,打分排名;
而是 反映“胜率”的数值,比赛是:网友自行输入任意问题,随机抽取两个模型对比。
所以,讨论提升了多少分的比例是不正确的。
4 个赞
taiyi747
(taiyi 747)
7
PPT多多少少会有点水分,马圣的也一样,而且他也不敢标openai o3mini high,所以我觉得他自己还是很清楚的,而且不排除他在训练时已经把题目放进去训练过了
3 个赞
Alfred6
(格里菲斯)
9
还没放开呢不好说,不可能为了用他去充值吧,等api 
不过预期应该不会差,10w块h100摆在那里(后期到了20w块),抄ds也不会差到哪里去
3 个赞
Azide
14
等详细的测试咯,各家 LLM 永远都是在 ppt 上最强。不过目前看反馈还成。
另外个人感觉, LM Arena 的评分偏离我的个人体验是比较大的。
不管咋样,多了家入局都是好的。
不如说这两年搞 ai 的力大砖飞才是常态……所以 deepseek 才特别惊艳。
2 个赞
目前没有完整版公开吧,现在x上自媒体和论坛佬们用的都是早期版本的,不好说。
拉垮一步来说,反正能刺激三大家赶紧把藏货拿出来就算达到目的了,好的来说,真的能20美元用到媲美o1-pro的,那也够了
Miochan
(Mio)
16
我一直认为ai是否牛逼是看用途的,有的逻辑推理能力强但代码能力不行,有的则反之,好不好用还得看用来干什么
当然哪方面都不行的那是真不行
biribiri
(biribiri)
18
反正arena那个grok3early我感觉一般,问了下经典的找不带e的奇数问题,先是给我乱回答,然后我让它仔细想想就直接给我死循环了,31到39一直死循环来回检测,最后在死循环中直接被截断。我猜底模是数学和编程特化?benchmark很强,但实际体验不一定好
1 个赞