yhp666
(yhp666)
1
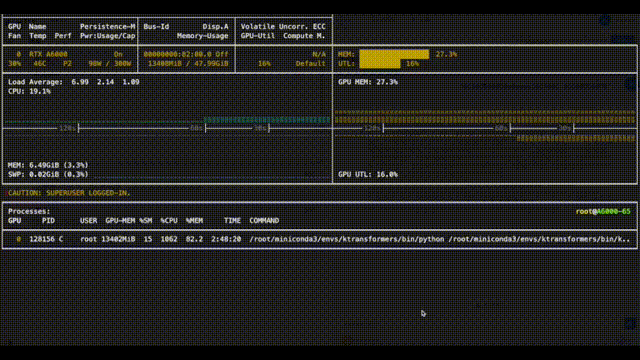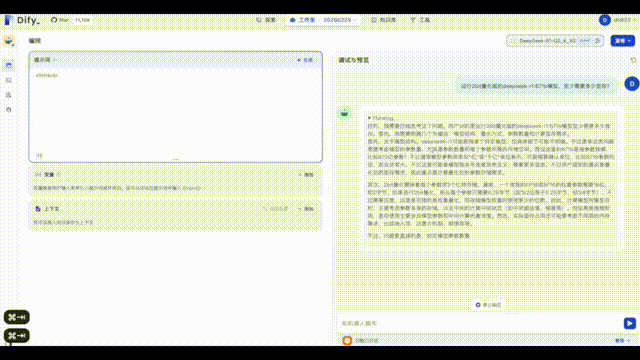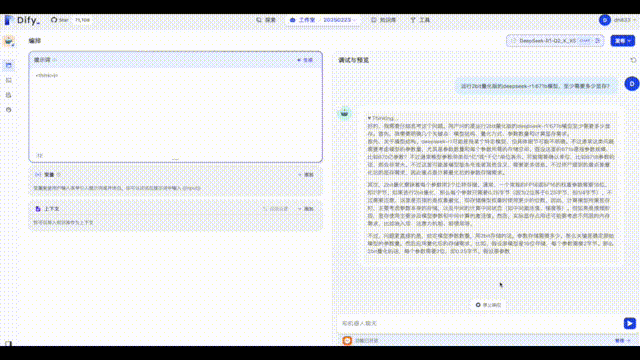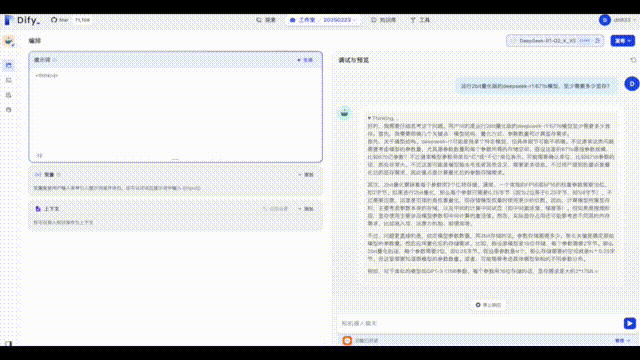
先上效果图,可以看下CPU、GPU、显存利用率,以及大概15kotens/s在Dify里的效果
1、一定要仔细看官方文档,虽然前后有点绕嘴,但是实际上已经把需要注意的点交代清楚了。
2、没有256GB的物理内存,没有16GB的显存就可以放弃了。就算是2bit量化版本,也不是随便找个机器就能运行的。
3、或多或少也得有点基础,对于0基础纯靠gpt、claude、deepseek就想搞定私有化部署恐怕还有点困难。
4、这种环境也就是自己dev耍耍而已,真正企业应用甚至商业化去售卖绝对使不得。
详细文档如下:
ktransformer测试.pdf (462.3 KB)
文档里漏了一张Dify配置模型的截图
42 个赞
佬分隔符那里用默认的行?
我去连 vllm 跑的 70b 感觉显示不对啊
1 个赞
yhp666
(yhp666)
6
有可能vllm跟ktransformers不一样?我这边用\n\n肯定是ok的
2 个赞
都是走的 OpenAI标准接口 不应该啊
不应该啊
明天换个模型试试
我这边 dify 接 ollama 的 70b 输出总是会截断
发布的应用 新开一个对话问一个问题都会的那种
是不是 dify 的会话隔离没做好(´・_・`)
1 个赞
嗯我的也是
fastgpt 就没有流式返回分隔符这个必填项也没问题╮(¯▽¯)╭
另外佬你的会话会自动重命名话题吗?
1 个赞
dify 官网就可以然后有提供重命名话题的 api
好家伙自部署版本没实装吗?
2 个赞
BenSu
12
佬友也关注过这个…测试下来基本就是自己个人玩的那种么?多并发比如给几个人用是不是会卡顿之类的
3 个赞
多并发还是得 vllm
kt框架对多并发的支持目前好像不好 感觉未来可期
2 个赞
taiyi747
(taiyi 747)
14
前几天我在b站腾讯云TDP直播间,跟大佬们已经部署成功了,好用是好用,问题很多,需要处理好久
3 个赞
BenSu
17
感谢,那只能用dev了……不过单卡可以671已经OK了
1 个赞
Brantfang
(Brantfang)
18
果然是慢点,但是能用。这种异构效果其实很不错。降本增效。
1 个赞