PSP
1
测试的结果很有意思
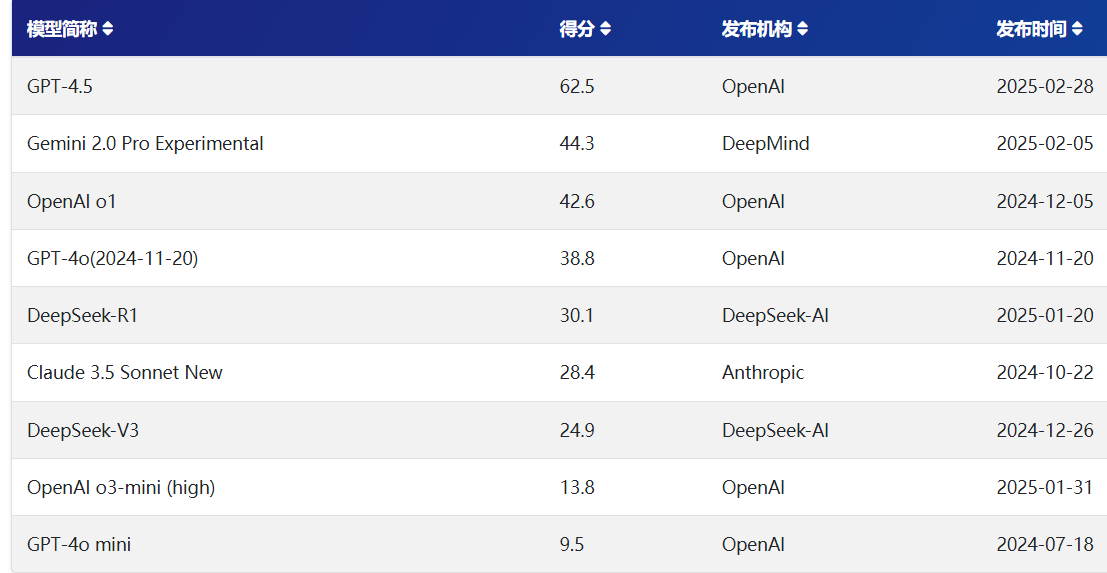
SimpleQA的全新评测基准,旨在解决语言模型生成内容中的问题(即模型生成看似合理但实际错误的信息),并通过开源方式推动AI生成内容的可靠性发展。这一基准的发布标志着AI领域在事实性评估方面迈出了重要一步。通俗的说法是,【模型世界知识的能力的测试】
SimpleQA的核心目标包括:
- 高正确性:每个问题由两名独立AI训练师验证答案,并附上来源链接,确保参考答案的权威性。
- 挑战性:即使如GPT-4o等前沿模型,在SimpleQA上的正确率也低于40%。
- 多样性:涵盖历史、科学、技术、艺术、娱乐等领域的4326个问题,避免模型过度专门化。
- 高效性:问题与答案简短,评估过程快速且结果稳定,适用于大规模测试。
9 个赞
PSP
2
参考V3和R1,两个版本的得分差距。
这个测试结果也基本证实了o1-mini,o3 mini,就是GPT-4o mini的推理版。知识量太低,不是充满幻觉,就是一问三不知。
而不是新模型。
最后个人非常期待grok 3和Claude 3.7 sonnet的表现,理论上不会低于gemini 2.0 pro
1 个赞
PSP
7
这个测试是你给他假消息,让他来判断是否是事实。
R1虽然幻觉强,但是在指出提问者的幻觉(事实性评估)应该比V3更强。
PSP
10
是的。专门用来测试模式的模型的基座能力。比如o3 mini 一度号称最强模型,大部分测试项目都击败了o1。但是本质是基座模型就是4o-mini这种8B-30B这种范围等级的小模型。
以上模型除了gpt4.5全部深度使用过 主要用于科研任务 个人感觉ds r1是这里面幻觉最严重的
2 个赞
slashkkk
(空气动力学)
14
也不知道是是不是我主观感受,我觉得r1思考有深度,但输出质量没深度了,而且幻觉怎么越来越严重。
awz707
(awz707)
18
呃,,,这个测试,不会是OpenAI为了推广GPT-4.5找来的吧 
话说我日常是使用的幻觉问题,可以通过联网来修正啊,对我来说代码能力和逻辑能力以及性价比才是我看重的,所以我还是不可能选择GPT-4.5的 
是这样的,r1幻觉非常严重,不知道能不能用prompt规避一下,老是会给自己带入莫名其妙的背景