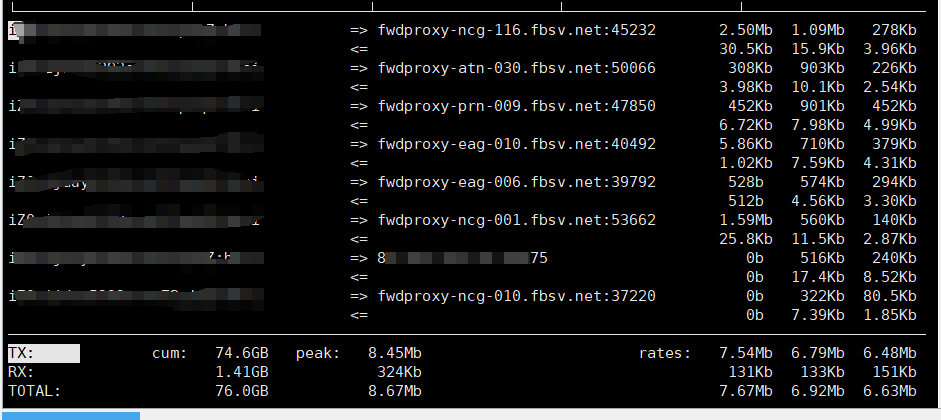
如图,这是一个node服务端,一直被这些爬虫以一秒一次左右的间隔不断访问资源,把6M的带宽吃的满满的,但是又考虑到这些爬虫可能有正向作用,比如利于我们推广?robots.txt 感觉他们不一定遵守。直接锁IP又太果断,哎呀好烦,请各位佬参谋参谋,跪谢~
不上cdn吗,我记得cf可以让这些搜索引擎爬虫从cdn获取内容
建议可以看看常见的UA,有部分比如搜索引擎可以放开(换一些推广);
看一下访问的目标是什么,如果是静态资源,比如图片的考虑上一下防盗链。
如果是影响到你的服务正常使用的话,可以ban掉,先保证你的正常用户访问。(看你获客来源?)
fbsv[.]net 搜了一下好像是facebook的?
去设置允许爬的时间段,可以设置晚上三更半夜的时候,Google和Bing没有记错都可以的,然后其他时间段就禁止所有就可以了
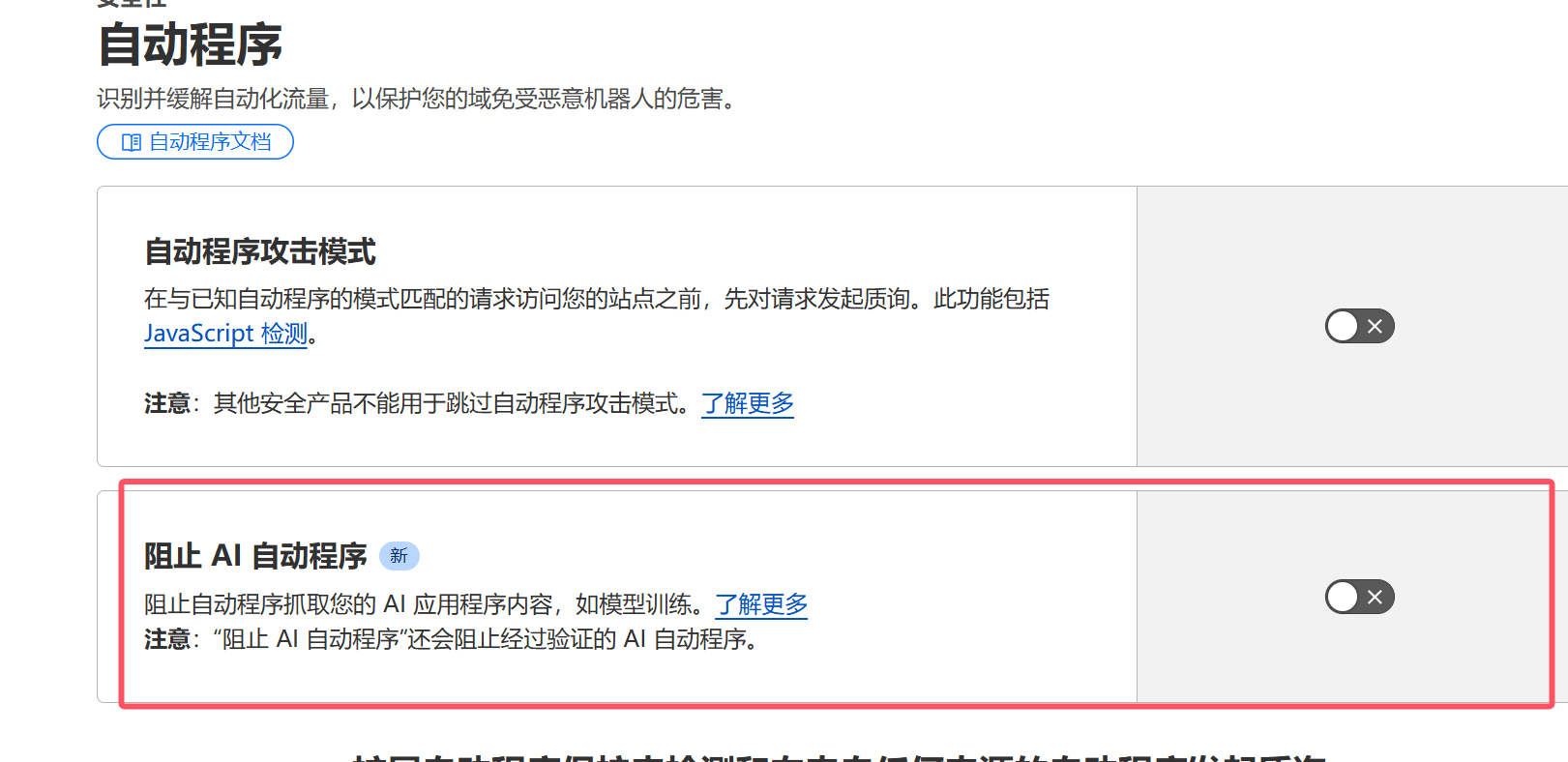
感谢各位佬的建议,不胜感激,最近有一些头绪,我们网站中进行了facebook pixle的数据埋点,然后有一些页面的埋点有问题,fb可能就是因为这个原因一直在尝试重新抓取,但是我很疑惑,这一块fb竟然没有做相关策略,比如延时策略之类的。置于apply和google的还在研究开始是什么问题,直接ban掉我估计弊大于利,总之,感谢各位佬,每个人我都认可!希望我们可以持续保持对L社区的热情
此话题已在最后回复的 30 天后被自动关闭。不再允许新回复。