book-searcher 介绍
其实有点标题党,咱们实际要搭建的是个基于索引的搜索网站,索引的是IPFS与实际电子书资源的映射,再配合IPFS网关,咱们就能轻松下载想要的电子书啦,如下图所示
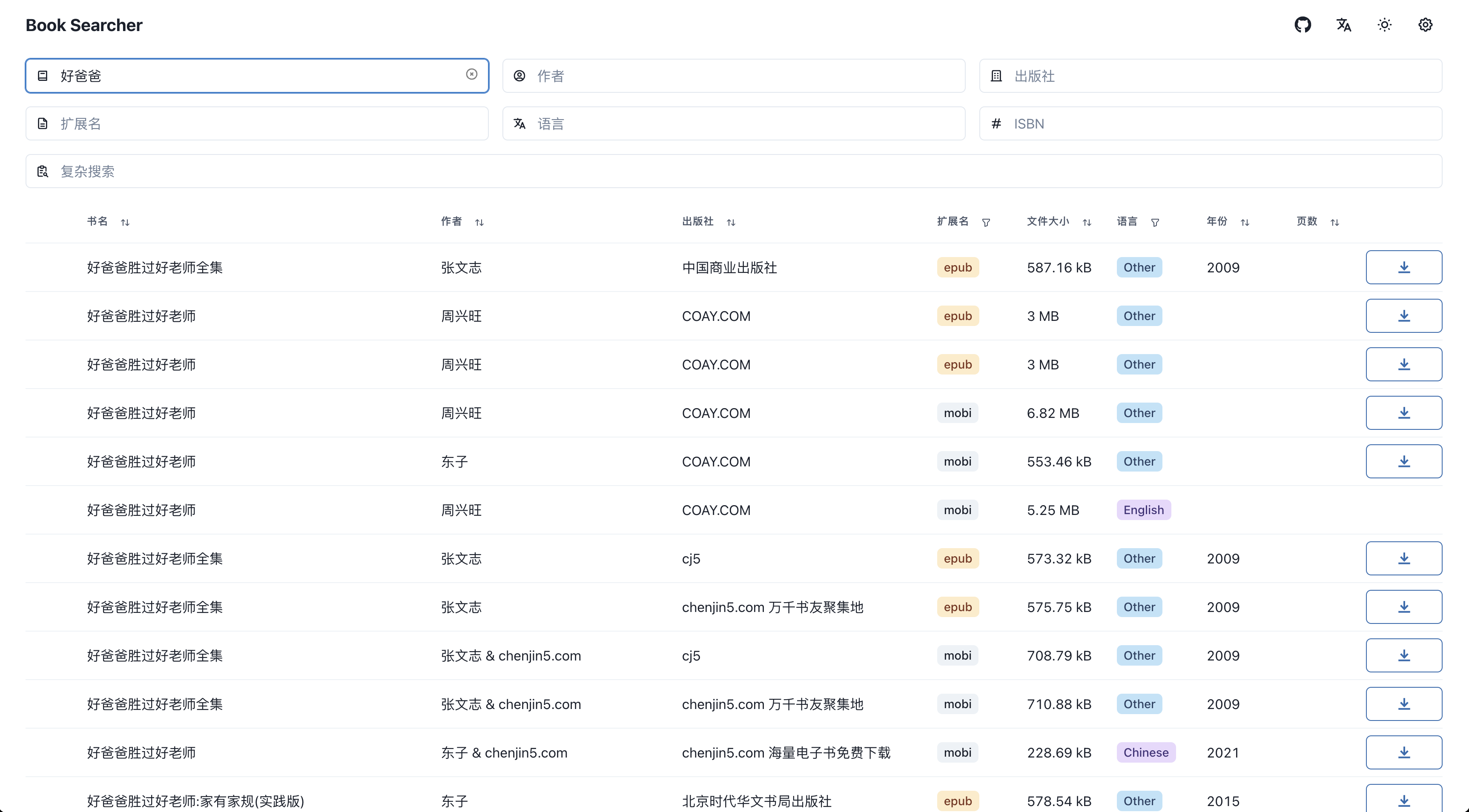
搭建
1. 下载图书索引
- 网站最关键的核心就是索引文件(很大,大家忍一下),大概有3点多个G
推荐去这里下载1.2.0版本,最新数据是到23年10月
Cmj's OneDrive - 下载好后找个地方解压,解压后会得到一个index文件夹
2. 准备docker-compose文件
docker 相关的安装我就不过多赘述了
book-searcher原始的gayhub 仓库及dockerhub仓库都惨遭封禁,我基于zu1k大佬的仓库重新编译并上传了镜像,地址在https://github.com/zu1k/bs-core,我只编译了x86的,各位大佬如有其他架构的需要可自行编译。
version: '3'
services:
book-searcher:
image: langhai8045/book-searcher:latest
restart: always
ports:
- 7070:7070
volumes:
#这里填上一步index文件夹的路径,下面是我的例子
- /volume1/docker/book-searcher/index:/index
3. 启动
docker compose up -d
执行好后就可以以 http://机器IP:7070 打开页面啦
4. 配置IPFS网关
启动后大家可以试试能否搜索到电子书,如果发现没有下载按钮的话,大概率是初次启动时IPFS网关没有配置,可以点击图示按钮,在弹出的输入框中输入以下内容
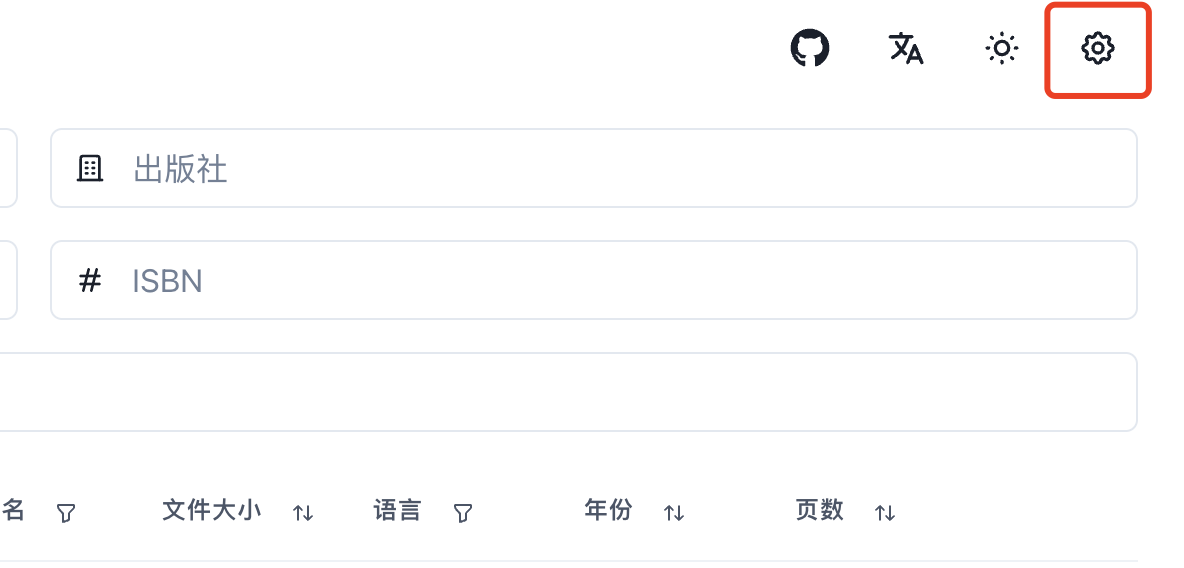
https://cloudflare-ipfs.com
https://dweb.link
https://ipfs.io
https://dw.oho.im
一定要加https:// 一定要加https:// 一定要加https:// 重要的事说三遍
提醒下各位,这里面能搜索很多平时看不到的书籍,所以建议大家自建自用,尽量少分享
当然不想自建也可以看大佬整理的帖子,上面有很多在线方式