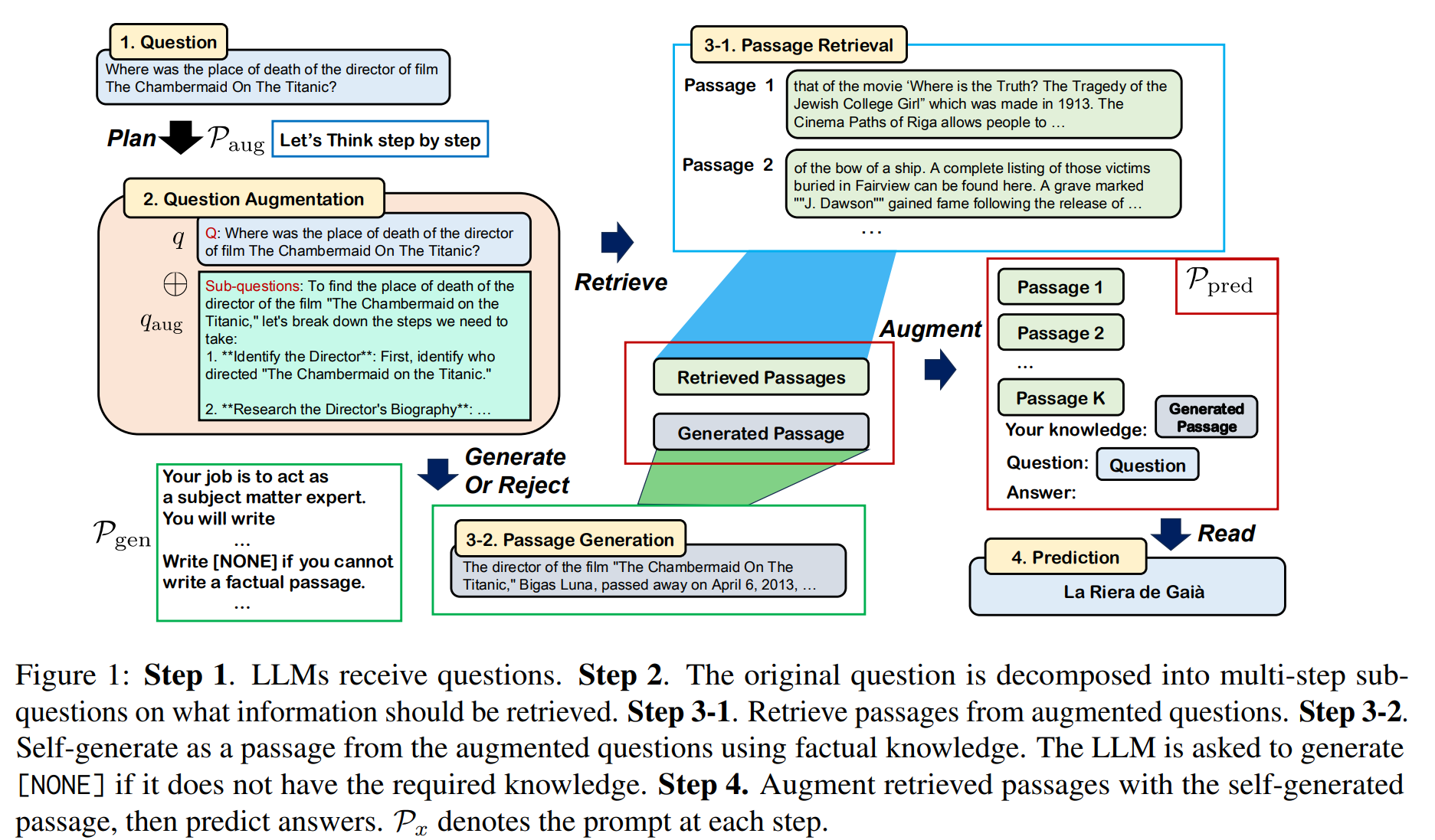
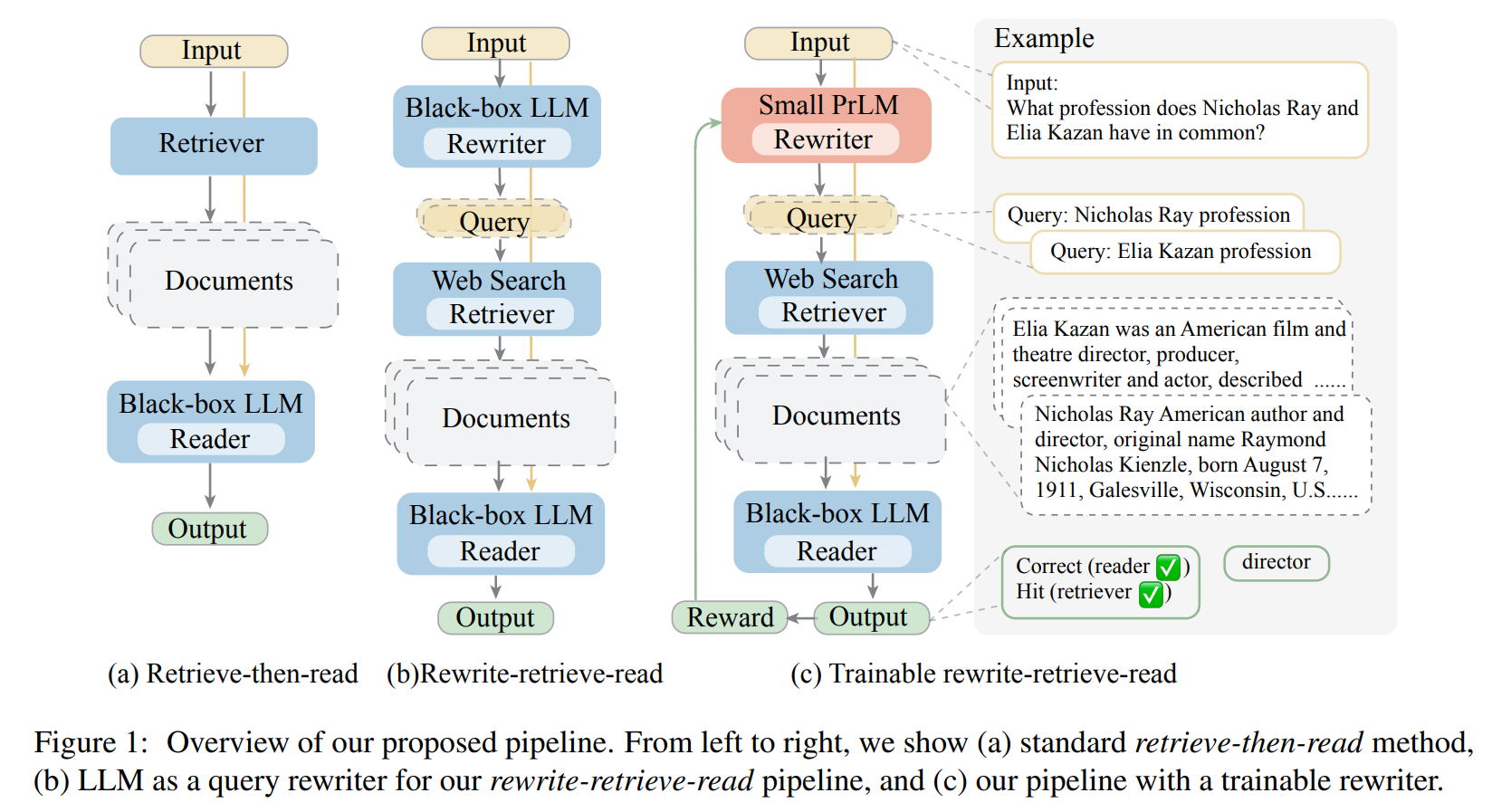
研二档,目前做RAG,开题开的是信息稀疏下进行RAG的优化,但是完全不知道应该怎么优化。
目前想到的也都是缝合怪。
- 缝一个Web搜索更新知识库
- 缝一个多重检索(单词匹配+语义相似度)
- 缝一个验证模块,验证检索到的知识和问题是否相关
- 缝一个重排序模块,
- 最后缝一个嵌入过程,不把知识作为prompt,而是把知识作为参数传给LLM,使其不用解析。
但这些现在都有人做了,还有什么可以做的啊。
开题写的是缝一个数据增强模块,将检索到的知识重构成为新的格式,然后微调一下LLM,使其能够更好的从新的格式下的知识里面挖掘有效信息。
但是完全不知道该怎么做,现在没baseline,也没数据,也没想法。
求帮助,有大佬带可以有偿(分期),目前学生,一次可能给的比较少,找到实习后可以+钱。
可以弄个合同,(我不会跑路)
看了很多科研机构,但都太贵了,最便宜的也要3w块,一次属实拿不出来。
孩子想毕业。
7 个赞
Yohanes
(Yohanes)
3
大佬好!对于语义稀疏的场景,个人感觉本质无非就是扩展信息渠道,使得语义稠密。像你说的 1,2,3都是在这方面下功夫!但我从实际的 RAG 工程来看,语义稀疏的问题,不单单要从这方面下功夫,更重要的是诱导用户去提供更多的内容信息,或许你可以试试从诱导信息这方面入入手呢? 有机会可以加个好友一起聊一下,我只是对这方面比较感兴趣,但并不是什么高学历人士~
1 个赞
你说的这个方向,实际上是扩展知识库把。这个怎么发文啊,
但我针对的场景就是信息稀疏的场景。
比如说某个县城1950年的历史什么的,这类信息不管怎么样都不多。
Yohanes
(Yohanes)
5
说的跑题了啊哈哈哈,不过真的只是 idea 的话,可以试试图数据库之类的思想,建立一个数学模型,让他信息补充的更贴近语义?(或者专项小模型之类的)
这是让LLM生成的内容填充数据库么?
这样会有幻觉的吧,
Yohanes
(Yohanes)
7
幻觉是必然会产生的,但问题是如果带来的好处大于坏处,那这个幻觉也不是不能容忍
对于信息稀疏的领域,领域内知识几乎不可能出现在LLM的内部知识中,那这样得到的几乎全部是幻觉把
Yohanes
(Yohanes)
9
做一个强化学习的模型(语料都是专门用来解析用户意图并识图补充完善意图的语料 + 深度思考过程的)
1 个赞
qs,最近已经忙疯了。
疯狂的看Java八股,Java项目和力扣,准备投Java实习,还差70%把,每天全力干,月底应该可以过完一轮有个大概印象。
现在还要组会上说说最近的进展,我最近科研啥也没干,水都不知道可以水什么。
头疼的要死
1 个赞
我没有自己的实现,但是现在论文基本都开源代码。现在还有很多开源的RAG框架。
哪个都可以试试看吧,
1 个赞
有没有什么不扩充知识库的想法?
我的想法倾向于对检索到的结果进行数据增强,使得LLM可以更好的挖掘数据中的知识。
目前普适的方法是用重排序,把相关性高的知识放在给LLM的输入的前面以提高其权重。
Praxis
20
重排不重排的,如果llm上下文够大,资料全丢进入,llm自己就能重排,因为本身重排也是rerank模型在做
rag研究如果不做rag本身,就应该做自动化扩充知识库->由llm信息交叉验证->呈现有序可信的知识,因为这个是使用llm+rag的根本目的。
比如某个县城1950年的历史,县志,地方类型小说,历史类书籍,报纸,这都是人类需要消耗大量精力才能整理归纳的知识,通过llm快速搜索快速整理,交叉验证出可信的部分,其余的孤证也一起列出或者二次搜索验证,这种效率上的显著提升怎么也够你过关了。