抛砖引玉:了解到 L 站有 Telegram 群聊频道 LINUX DO Channel,于是就通过自己仅有的一点 Python 知识写了点代码,并在每周周一统一查看上一周的帖子合集。
具体代码(另存为 L.py):
import json
import csv
# constant variables
weekly = {
"01": ["2024-12-30", "2025-01-06"],
"02": ["2025-01-06", "2025-01-13"],
"03": ["2025-01-13", "2025-01-20"],
"04": ["2025-01-20", "2025-01-27"],
"05": ["2025-01-27", "2025-02-03"],
"06": ["2025-02-03", "2025-02-10"],
"07": ["2025-02-10", "2025-02-17"],
"08": ["2025-02-17", "2025-02-24"],
"09": ["2025-02-24", "2025-03-03"],
"10": ["2025-03-03", "2025-03-10"],
"11": ["2025-03-10", "2025-03-17"],
"12": ["2025-03-17", "2025-03-24"],
"13": ["2025-03-24", "2025-03-31"],
"14": ["2025-03-31", "2025-04-07"],
"15": ["2025-04-07", "2025-04-14"],
"16": ["2025-04-14", "2025-04-21"],
"17": ["2025-04-21", "2025-04-28"],
"18": ["2025-04-28", "2025-05-05"],
}
def get_messages_list(json_file):
return json.load(open(json_file))['messages']
def get_weekly_infos_csv(posts, weekly, rank):
rank = str(rank)
csvfile = f"Lurls-Weekly-{rank}.csv"
# fieldnames = ["Date", "URL", "Title"]
fieldnames = ["URL", "Needed", "Title"]
time_start, time_end = weekly[rank]
with open(csvfile, "w", newline="", encoding="utf-8-sig") as csvfile:
# writer the header
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, delimiter="\t")
writer.writeheader()
# traverse each post
for _ in range(len(posts)):
post = posts[_]
if time_start < post['date'] < time_end:
# traverse each part in the post
for part in post["text"]:
# find the part with ['href'] and ['text'] attributes
try:
writer.writerow({
# "Date": post["date"],
"URL": part["href"],
"Needed": "Yes",
"Title": part["text"],
})
except:
continue
return csvfile
def get_weekly_infos_md(posts, weekly, rank):
rank = str(rank)
mdfile = f"Lurls-Weekly-{rank}.md"
time_start, time_end = weekly[rank]
with open(mdfile, "w", newline="", encoding="utf-8-sig") as mdfile:
# traverse each post
for _ in range(len(posts)):
post = posts[_]
if time_start < post['date'] < time_end:
# traverse each part in the post
for part in post['text']:
# find the part with ['href'] and ['text'] attributes
try:
content = f"- [{part['text']}]({part['href']}) \n\n"
mdfile.write(content)
except:
continue
return mdfile
def transfer_weekly_csv2md(rank):
"""
运行文件,得到 .csv 文件
在 .csv 文件中遇到不需要的帖子,在 Needed 一栏中用空格把 Yes 给替换掉即可
遍历一遍之后,注释掉上方两行代码,同时取消注释下方的这一行代码
再运行文件,得到 .md 文件
.md 文件才是我想要放到周刊中的 digest 部分的内容
"""
csvfile = f"Lurls-Weekly-{rank}.csv"
mdfile = "((" + f"Lurls-Weekly-{rank}-csv2md.md"
with (
open(csvfile, "r", encoding="utf-8-sig") as csv_file,
open(mdfile, "w", encoding="utf-8-sig") as md_file,
):
reader = csv.DictReader(csv_file, delimiter="\t")
for row in reader:
if row["Needed"] == "Yes":
md_file.write(f"- [ ] [{row['Title']}]({row['URL']}) \n\n")
return mdfile
def main():
L_posts = get_messages_list("result.json")
get_weekly_infos_csv(L_posts, weekly, 12)
# transfer_weekly_csv2md(12)
if __name__ == "__main__":
main()
具体操作:
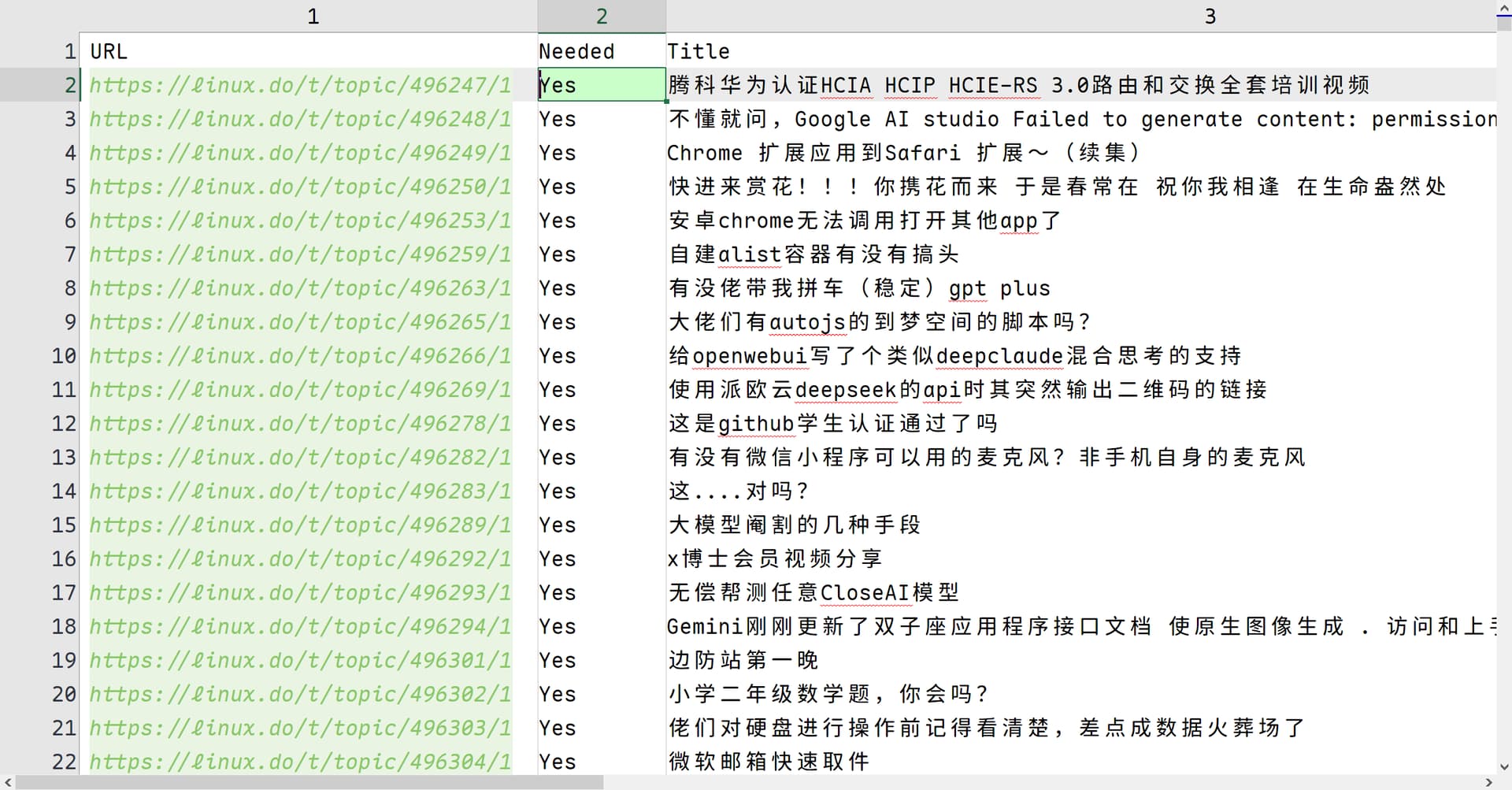
- 导出
json格式历史记录:每周一从 LINUX DO Channel 中导出频道历史记录result.json文件;当然哪天都行,反正处理的都是上一周的聊天记录。 - 修改周数:只需将
main()中的周期数(上面代码对应的是12)修改为上一周的周数即可。 - 运行:终端运行一遍
python L.py,得到Lurls-Weekly-12.csv文件,其中存储了发布于这一周的所有帖子的一些信息,一行对应一个帖子,默认每一个帖子的Needed列都是Yes。 - 陆陆续续有事没事就打开文件敲空格:(个人喜欢)在 Emeditor 中打开并编辑
.csv文件;对于不感兴趣的低质量的帖子,我会把这一行对应Needed这一列的那个格子中的Yes用空格替换掉。- 经验数据:一周对应的
.csv文件会有 3000-4000 行,最终保留下来 200-400 行。
- 经验数据:一周对应的
- 回到
L.py:注释掉main()的前两行代码,取消注释后面的代码,再在终端运行一遍python L.py,得到((Lurls-Weekly-12-csv2md.md文件,里面存储了剩下的这几百行链接,只不过改成了 markdown 能够识别的[]()语法,方便后续的别的操作。- 这里生成的
((Lurls-Weekly-12-csv2md.md文件名有((,是因为我在使用 git 时不跟踪这种“中间文件”。
- 这里生成的
效果图如下:

但是这样做肯定有缺点:
result.json- 对于 L 站的二级、三级帖子,在 Telegram 群聊中是不会自动生成相应帖子,即
result.json中仅存储一级帖子,因此帖子整体含金量不算高。
- 对于 L 站的二级、三级帖子,在 Telegram 群聊中是不会自动生成相应帖子,即
L.py- 筛选条件只有“是否发布于某一周”,没有更多的筛选器;即筛选力度太弱,至少下面的功能都没实现
 谁发的帖子我不看
谁发的帖子我不看- 带有哪些标签的帖子我不看
- 带有哪些关键字的帖子我不看
- 只有几个人关注/回答的帖子我不看
- …
- 筛选条件只有“是否发布于某一周”,没有更多的筛选器;即筛选力度太弱,至少下面的功能都没实现
.csv- 这就导致每周都要在
.csv文件中敲击几千下空格,虽然空格不算很麻烦,但是几千下。。。这种操作可以在简化一下吧。
- 这就导致每周都要在
总之,欢迎各位能够提供一下改进的思路或者是别的思路,感谢喵。
