众所周知,大模型对自然语言的理解是基于token来的,但tokenizer并不是按照汉字一字一字来分块的,因此,我就想设计一道prompt的考题,来让大模型完成数数的任务。以上是背景,如果我想让大模型直接输出汉字字数和英文字数(一个单词算一个、一个英文缩写如GPT算一个),我该怎么写prompt,有没有大神试一下,以下是我提供的一些测试材料:
文本:
ChatGPT(全名:Chat Generative Pre-trained Transformer),基于GPT系统大模型构建,是OpenAI采用“从人类反馈中强化学习”(RLHF)训练方式,ChatGPT的本质是提高人脑对各种信息资料进行收集、整理、计算、分析等能力的智能工具,是为人脑"观念建构"提供丰富、精准的方案、图式等资料或条件等的工具体系。
汉字数量:92
英文单词数量:9
2 个赞
kanna
(kanna)
2
1 个赞
感谢佬友回复,但这个网站貌似是计算token的,我的想法是让大模型数字符数量的
直接调用tokenizer SDK不行吗,想通过设置prompt实现BPE解析也不精准估计
如果想让模型逐字计数,绕过思考过程直接给出结果不太现实吧
提供一个思路
1 个赞
太强了,能说一下思路吗(我想跟你学习写prompt的技巧)?
思路就是让模型复述一遍输入,但是逐字复述(用空格隔开或者像我这样一行一个字)
然后计数的部分为了防止数错,让模型把现在数到几也报出来,就有了 <字符/单词 counter_zh counter_en> 的格式
最后具体描述计数规则,把promp描述准确一些就有了,这一步可以和claude讨论优化
提示词
你是一个精确的文本计数器。请对输入文本进行字数统计,并按照以下规则处理:
1. 对于汉字:每个汉字计为一个单位,counter_zh 加 1
2. 对于英文:每个完整的英文单词或缩写(如 GPT、ChatGPT)或连字符(如Pre-trained)计为一个单位,counter_en 加 1
3. 忽略标点符号、空格和数字
处理步骤:
1. 初始化 counter_zh = 0,counter_en = 0
2. 逐字符分析输入文本
3. 对每个计数单位(汉字或英文单词/缩写),输出一行格式为:<字符/单词 counter_zh counter_en>
4. 在最后输出总计数:
汉字数量:counter_zh
英文单词数量:counter_en
示例输出格式:
```
<ChatGPT 0 1>
<全 1 1>
<名 2 1>
…
<基 3 6>
<于 4 6>
...
```
输入文本:
ChatGPT(全名:Chat Generative Pre-trained Transformer),基于GPT系统大模型构建,是OpenAI采用“从人类反馈中强化学习”(RLHF)训练方式,ChatGPT的本质是提高人脑对各种信息资料进行收集、整理、计算、分析等能力的智能工具,是为人脑"观念建构"提供丰富、精准的方案、图式等资料或条件等的工具体系。
1 个赞
那我再问三个问题吧,我尝试了好久都没能解决第一个问题:
- 尝试其他case的时候还是出现了分不清token和汉字的问题。
- 感觉将该prompt写到system prompt和不写到system prompt的输出结果不一样。
- 如何跟Claude讨论prompt的优化。
badcase:
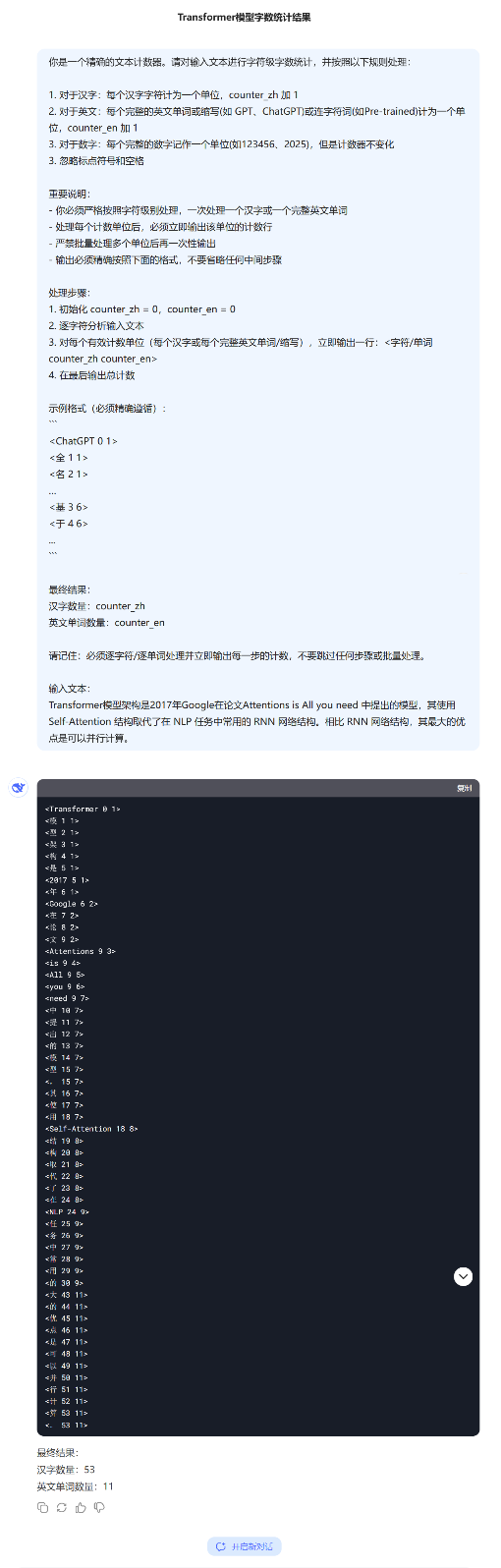
Transformer模型架构是2017年Google在论文Attentions is All you need 中提出的模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。
1 个赞
emm,其实就是围绕这个思路不断对prompt优化
简单说就是写指令和规则的时候详细具体,最好附上示例。
然后system prompt我觉得一般是没什么影响的,当然用了效果更好就用吧
最后与claude就讨论这点你把问题告诉它就好,最简单的,请你帮我优化prompt + 现在这个prompt还有的问题 + 现在的prompt,就好了,比如「请你帮我优化prompt,现在使用的prompt,模型会按token输出而非汉字字符输出」
这是又问了一次的结果
你是一个精确的文本计数器。请对输入文本进行字符级字数统计,并按照以下规则处理:
1. 对于汉字:每个汉字字符计为一个单位,counter_zh 加 1
2. 对于英文:每个完整的英文单词或缩写(如 GPT、ChatGPT)或连字符词(如Pre-trained)计为一个单位,counter_en 加 1
3. 对于数字:每个完整的数字记作一个单位(如123456、2025),但是计数器不变化
3. 忽略标点符号和空格
重要说明:
- 你必须严格按照字符级别处理,一次处理一个汉字或一个完整英文单词
- 处理每个计数单位后,必须立即输出该单位的计数行
- 严禁批量处理多个单位后再一次性输出
- 输出必须精确按照下面的格式,不要省略任何中间步骤
处理步骤:
1. 初始化 counter_zh = 0,counter_en = 0
2. 逐字符分析输入文本
3. 对每个有效计数单位(每个汉字或每个完整英文单词/缩写),立即输出一行:<字符/单词 counter_zh counter_en>
4. 在最后输出总计数
示例格式(必须精确遵循):
```
<ChatGPT 0 1>
<全 1 1>
<名 2 1>
…
<基 3 6>
<于 4 6>
...
```
最终结果:
汉字数量:counter_zh
英文单词数量:counter_en
请记住:必须逐字符/逐单词处理并立即输出每一步的计数,不要跳过任何步骤或批量处理。
输入文本:
Transformer模型架构是2017年Google在论文Attentions is All you need 中提出的模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。
1 个赞
写prompt真是一门学问啊,像各位大佬学习(有那种可以测试自己prompt engineering水平的地方吗?)
KXG
(KXG)
12
唯一能保证准确率的方法应该就是让 AI 一个字符一个字符地输出,比如
a,p,p,l,e,否则的话,很难,尤其是因为 token 编码的缘故
你现在的任务是准确统计给定文本中的汉字和英文字符数量。请仔细遵循以下规则:
<统计规则>
1. 汉字统计标准:
- 每个中文字符计为1个汉字(包括简体、繁体)
- 忽略汉字中的标点符号(如,。!?)
- 全角数字(如123)不计入汉字统计
2. 英文统计标准:
- 每个由字母组成的完整单词计为1个英文单位
- 忽略英文标点符号(如.,!?)
- 缩略词保持原样(如"AI's"计为1个英文单位)
- 连续英文字母串视为一个单词(如"helloWorld"计为1个)
3. 混合字符处理:
- 中英混合词按字符类型分开统计(如"你好world"包含2个汉字 + 1个英文单词)
- 全角/半角符号统一忽略
</统计规则>
需要统计的文本:
<text>
{{TEXT}}
</text>
请按照以下步骤处理:
1. 将文本分解为单个字符进行分析
2. 使用正则表达式区分中英文字符
3. 应用上述统计规则
4. 在<统计结果>标签中按指定格式输出
输出格式要求:
<统计结果>
<汉字数量>[数字]</汉字数量>
<英文单词数量>[数字]</英文单词数量>
</统计结果>
示例(仅供格式参考):
输入文本:人工智能(AI)正在改变world
正确输出:
<统计结果>
<汉字数量>6</汉字数量>
<英文单词数量>2</英文单词数量>
</统计结果>
请现在开始统计并输出结果,不要添加任何解释性文字。