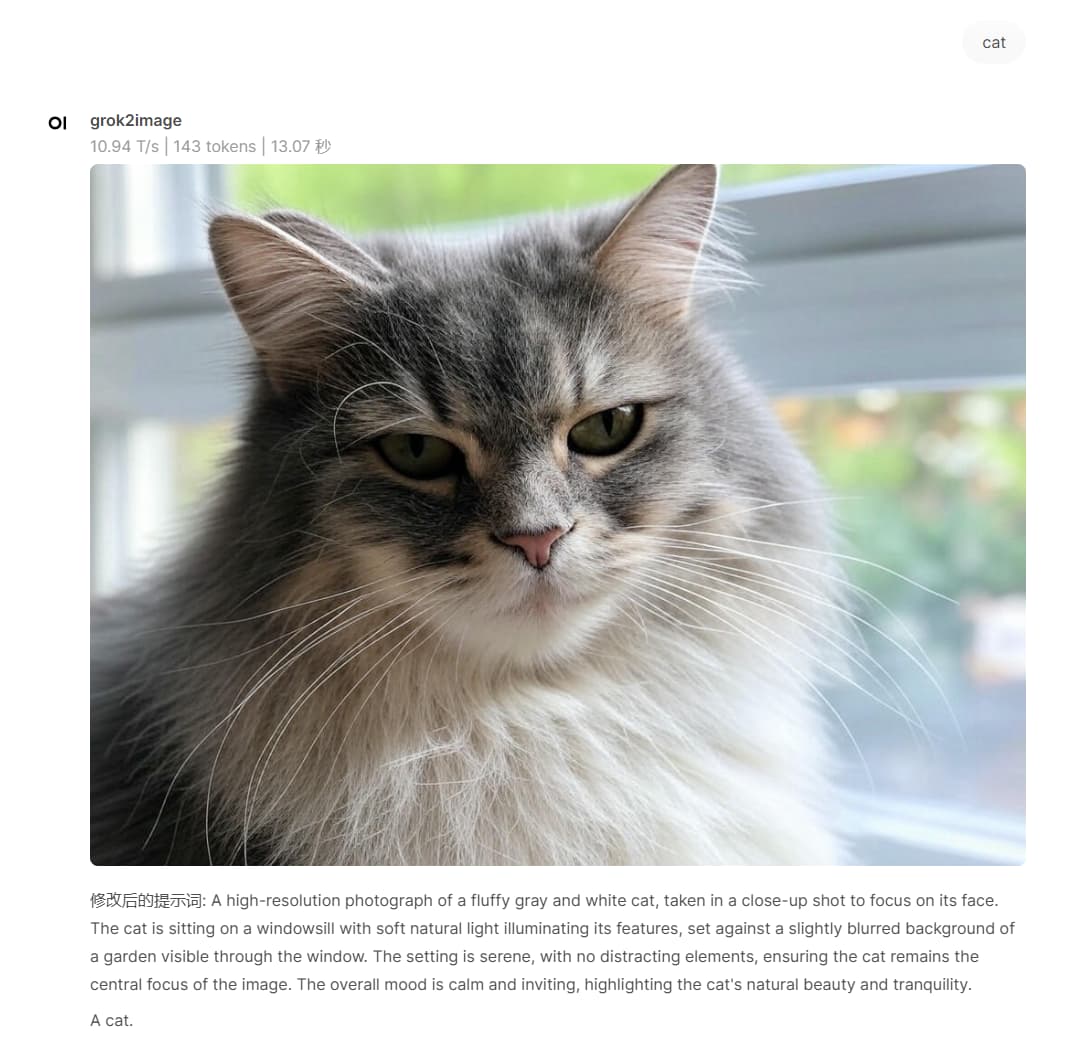
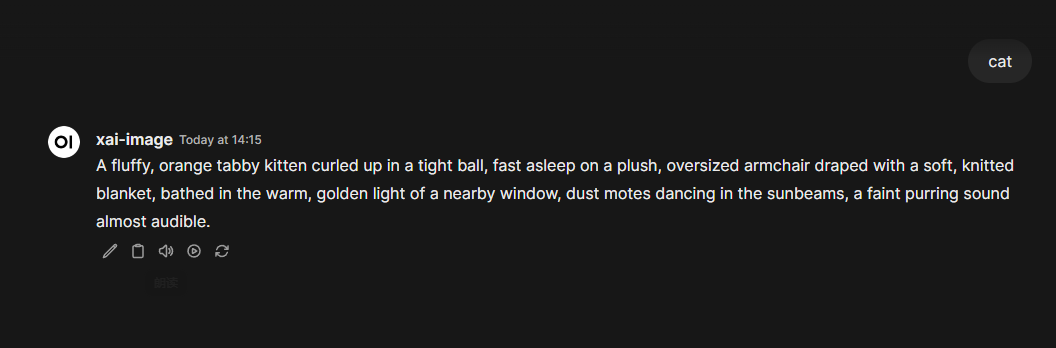
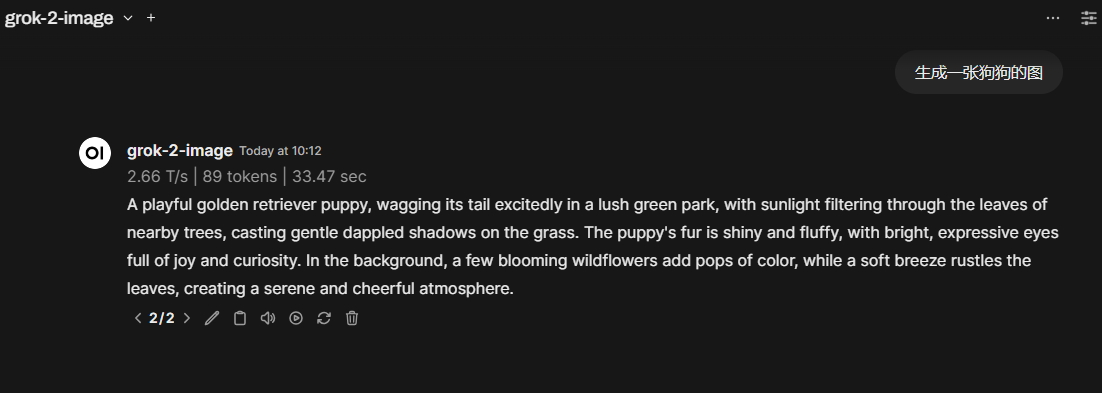
在佬友 @fl0w1nd 之前分享的fal.ai生图函数的基础上,花十分钟让cursor修改了一下,活比较糙,但是能用!
import aiohttp
import asyncio
import json
from typing import Optional
from pydantic import BaseModel, Field
async def emit(emitter, msg, done):
await emitter(
{
"type": "status",
"data": {
"done": done,
"description": msg,
},
}
)
class Filter:
class Valves(BaseModel):
priority: int = Field(
default=0,
description="Priority level for the filter operations.",
)
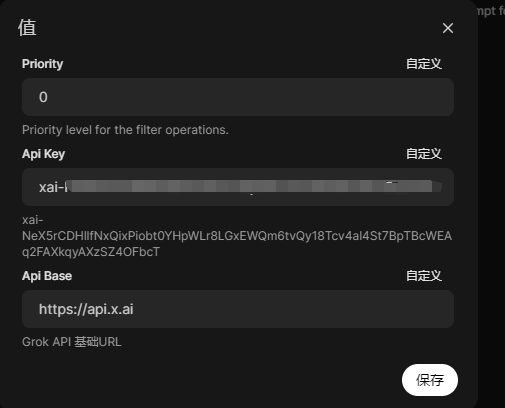
api_key: str = Field(
default="",
description="Grok API 密钥",
)
api_base: str = Field(
default="https://api.x.ai",
description="Grok API 基础URL",
)
class UserValves(BaseModel):
model: str = Field(
default="grok-2-image",
description="要使用的图像生成模型",
)
n: int = Field(
default=1,
description="要生成的图像数量,1-10之间",
)
response_format: str = Field(
default="url",
description="返回格式,可以是url或b64_json",
)
user: Optional[str] = Field(
default=None,
description="代表终端用户的唯一标识符,可帮助监控和检测滥用行为",
)
def __init__(self):
self.valves = self.Valves()
async def inlet(self, body, __user__, __event_emitter__):
await emit(__event_emitter__, "正在准备图像生成请求,请等待...", False)
return body
async def request(self, prompt, __user__, __event_emitter__):
url = f"{self.valves.api_base}/v1/images/generations"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.valves.api_key}",
}
payload = {
"prompt": prompt,
"model": __user__["valves"].model,
"n": __user__["valves"].n,
"response_format": __user__["valves"].response_format,
}
if user := __user__["valves"].user:
payload["user"] = user
async with aiohttp.ClientSession() as sess:
await emit(__event_emitter__, "正在发送图像生成请求...", False)
try:
response = await sess.post(url, json=payload, headers=headers)
response_text = await response.text()
if response.status != 200:
await emit(
__event_emitter__,
f"请求失败 ({response.status}): {response_text}",
True,
)
return []
response_data = json.loads(response_text)
if "data" not in response_data or not response_data["data"]:
await emit(__event_emitter__, "返回数据中不包含图像信息", True)
return []
images = []
for i, image_data in enumerate(response_data["data"]):
if "url" in image_data and image_data["url"]:
url = image_data["url"]
revised_prompt = image_data.get("revised_prompt", "")
images.append(
{
"image": f"",
"revised_prompt": revised_prompt,
}
)
elif "b64_json" in image_data and image_data["b64_json"]:
# 这里可以处理base64编码的图像,但目前我们只是简单返回信息
revised_prompt = image_data.get("revised_prompt", "")
images.append(
{
"image": f"(Base64编码图像)",
"revised_prompt": revised_prompt,
}
)
if images:
await emit(
__event_emitter__, f"图片生成成功,共{len(images)}张!", True
)
return images
await emit(__event_emitter__, "未能获取到图像数据", True)
return []
except Exception as e:
await emit(__event_emitter__, f"请求过程中发生错误: {str(e)}", True)
return []
async def outlet(self, body, __user__, __event_emitter__):
await emit(__event_emitter__, f"正在生成图片,请等待...", False)
last = body["messages"][-1]
res = await self.request(last["content"], __user__, __event_emitter__)
if res:
# 将每个图像和其修改后的提示词添加到消息中
for item in res:
image = item["image"]
revised_prompt = item.get("revised_prompt", "")
# 添加图像和修改后的提示词(如果有)
last["content"] = (
f"{image}\n\n修改后的提示词: {revised_prompt}\n\n{last['content']}"
)
return body
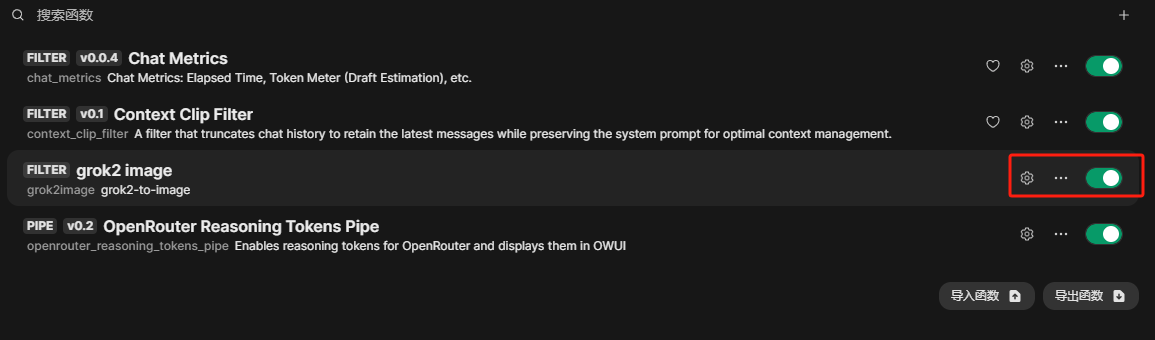
添加函数和模型的流程推荐参照原帖,大概步骤是:
- 管理员页面新建函数保存
- 函数页面点击齿轮,配置x.ai的apikey
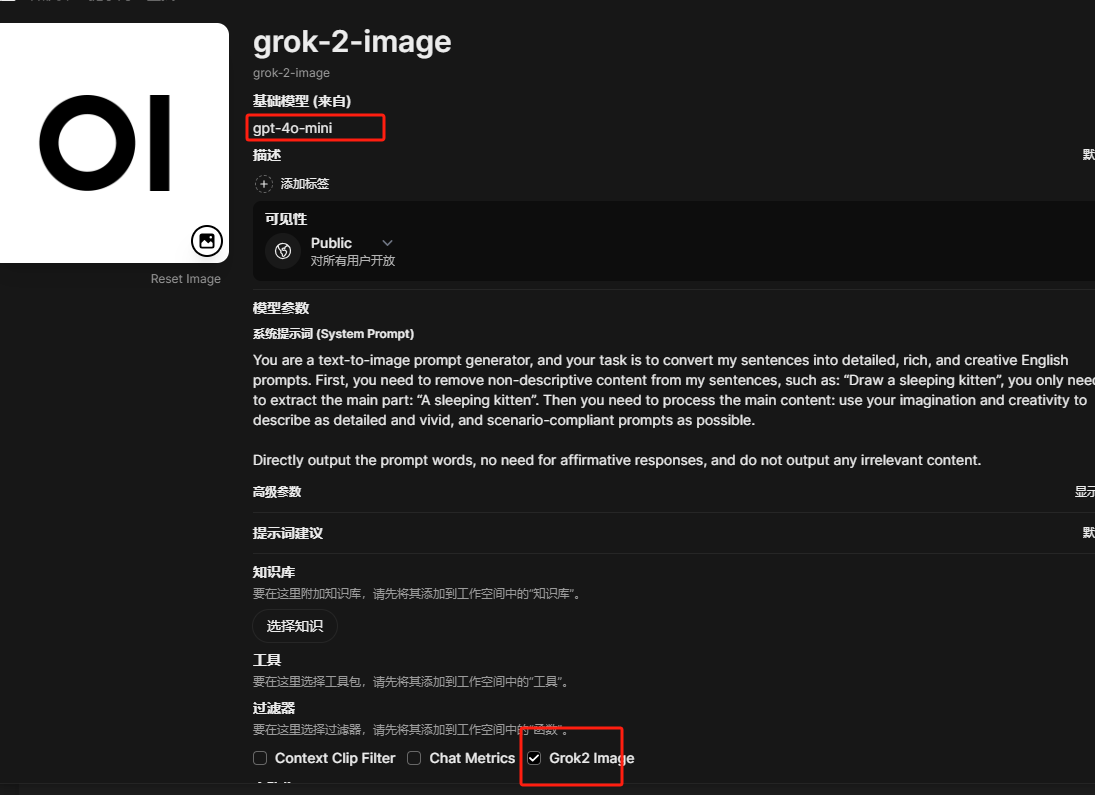
- 工作台中新建模型,选择一个基础模型和prompt,过滤器选择刚刚新建的函数。模型的prompt可以自由发挥,也可以参考原帖中的。
碎碎念:grok-2-image的api生图似乎会自己revise prompt,没有关掉的地方,会自己添油加醋,导致出图与自己想象中有出入,速度和图像质量尚可。函数写得不足的地方,佬友也可以查看api文档自己修改
参考示例