最流畅的听书方案(但是不能多角色)
操作比较友好的多角色听书方案(不过是闭源应用))
tts server效果最好llm分析多角色听书方案,是靠很好的想法绕过了本地显示文本标注的插件,但是对长段落和硅基的相性不好,多角色效果展示
llm朗读规则分配
//填兼容openai格式的key,顺便把下面的https://…………/v1/chat/completions和模型改成你自己要用的
var API_KEY = ''; //你对应的key
let SpeechRuleJS = {
name: "ai朗读规则-书名",
id: "ttsrv.multi_voice",
author: "TTS Server",
version: 5,
zdfp: 1, //1为自动分配,0为不自动分配
tags: {
narration: "旁白",
duihua: "对话",
duihuaA: "男",
duihuaB: "女",
juese0: "你看的主角名", //创建指定角色列表,可填指定角色名或正则表达式
//路人
juese9999:"少年路人男|右边可以填别名",
juese9998:"青年路人男|男蛊师|路人男|男路人",
juese9997:"中年路人男|",
juese9996:"老年路人男|",
juese9995:"少年路人女|",
juese9994:"青年路人女|女蛊师|路人女|女路人",
juese9993:"中年路人女|",
juese9992:"老年路人女|",
},
handleText(text) {
if (!!this.zdfp) {
text = fx(text);
let val = post(text);
text = thhs(val, text);
text = text.split("\n");
} else {
text = text.replace(/(“.*?”)/g, "\n$1\n").split("\n");
}
let list = [];
let tmpStr = "";
let endTag = "narration";
let reverseMap = {};
let roleMap = this.tags;
let js = [];
let 女 = new RegExp(".*[女寰婷媛氏婕婧姝娴妮妹娜娥妍娟娣茵婉莎琴莲娇娅梅霞倩花茶莉菊翠茹姣薇囡萍蕊丽玲素兰淑蓉芬萱珍恬芹茜玫姿雯粉芷卉芯滢香菡琬馨蓓珊丝仙曼侠钗姑甜莹艳枚荷伶芊妃秀雅影燕英美彩蕙晴巧芳莺琼姬朵蔓樱漫容芝女绒改怡玥静杏苒凤绮荟枝俐芙依菲盈语苹筱悠芸霜珠腊紫碧璇汐漪伊慧换瑶桃沫丹瑛洁桂梨苓月棉歆颖柔彤琳筠爱微雪梦瑄凝俏惠变艾绘柠圆岚悦韵鸽蕾幼铃兮带央妙诺虹么璐恋分仪菁米惜苗霏露苑荧红采玛麦吟含宛沁贞瑾欣闪环佩晶鲜秋柳诗盼净园舒芮转第珺音咏停穗飘若澜靓灵格蓝密招蜜嘎玉心葵扣会敏萌引晚竹涵细颜单屏琪沙函连忆贝勤群色情钰目慈雁雨予淇莫优俞豆艮笑风缘真蕴术尹冉早艺亭欢绿妞鸾奶玟烟眉汝瞳菱针潞湾晞夕草銮羚宜拿纳芽云因雲鱼如尔范璠漩指思朦橙愉榕唯丛喻沅爽皖娘妈嫂婶姐姨婆]+.*");
let 男 = new RegExp(".*[男锴策罡焜标坡铖彪勃栋柱翔豪强滔虎鼎鹏猛铠阔魁将韬鉴闯烽潮刚森洲城钢骥嵩震锋侃浩壮啸旺帅龙泰骁昊权钊铎豹翀骏亮勇皓楼山涛斌桓灏耿臣仓财峰峻煌镇序政铁统兵磊纲榜雄诚丞雍法昶宾霆挺威晟赐武朋键蛟滨枭超腾麟岗创拓冲骐翰昆凯博通乾岳竣植康达炯瀚军剑健呈坚梁雷港升生炜民州恺楷科河哲驰隆毅野盛湖泉勋展堃劲济川松振耀昂恒奎璋求才攀锟航库冠征奇屹奔帝骋淞骅夫琨战彬巨彧东举高宽喆江庚堂蓬印伟基功良经轲翼舟祥铮深邦迅涌朔弘舜秉波钧积更淦浚智源羿浪峥忠辉众团富丰寅任尧义致垒亨泽轶行敦委声杭北麒胜成谦孔际殿进志全旭炳章顶特程伯坤柏列吾起铭原昌占晖渊重宇曙发业巍周钟鸣旗谋裕衡力硕承拥国上飞赫彭杰付增洋申赞佑珩前骞玺晋禄佐禹次圣广厚天余录省甫建为帆锐劼中理跃纬观泓崇桥普福光璞聚俊用添名燚轩远佰鸿能宏望庭衍炼首尚炎仁实治宸旻明仲陆校根响典兴扬嗣礼繁尊信流岐均伦樟位阳锁德鑫祯见常傲闻争郑辰甲欧保合图体顺土汉赟公庄霖忱朗逢竞启星遵现祖贵记主岸嵘石宪琛默胤岭友捷得家贺林游临集有官煜寿永训向选长太延葛冶毕动宗齐大聪奥兆钦留修照朝鲁淳绍计克烈戈道枫元正玮初相锡玖恩伍庆芃其鹤久焱养善昭非唐谷万焰灼同臻洪继士世村加立铨仑铸昇棚烜苟焘号樑府逊敢海仕燊火舰操材登盟栓颢帮淮淏疆鲲渤坦宙社魏本水珲召浦传驹渠泳显怀茂澍斗学日冀来献应辽树木澎槐胡开卫季模安九里和孝冬师农慰弛徽牧运都纪领译备喜收党沛干千地韩放于要洵潘就育昱未曾术熠熹绪祁炀张丙布尘灯满池栩古钱定新文杨交六韦陵宝田乐廷颂人京让睿益郡袁愚革关]+.*");
// 生成反向映射
Object.keys(roleMap).forEach(key => {
const names = roleMap[key].split('|'); // 按竖线分割成数组
names.forEach(name => {
reverseMap[name] = key; // 每个名称单独作为键
});
})
text.forEach(tmpStr => {
tmpStr = tmpStr.trim();
if (!tmpStr) return;
if (tmpStr[0] === "“") {
js = [];
js = tmpStr.match(/【(.*?)】/) || [];
if (js.length > 1) {
endTag = reverseMap[js[1]] || -1;
if (endTag === -1) {
endTag = js[1].search(男) > -1 ? "duihuaA" : "duihuaB";
}
tmpStr = tmpStr.replace(/【.*?】/, "");
} else {
endTag = "duihua"
}
list.push({
text: tmpStr,
tag: endTag
});
} else {
endTag = "narration";
list.push({
text: tmpStr,
tag: endTag
});
}
});
return list;
},
fx = (input) => {
let counter = 1;
return input.replace(/["“](.*?)["”]/g, (match, p1) => {
return `\n“【${counter++}】 ${p1}”\n`;
});
},
thhs = (val, tet) => {
let wj = "jss.json"
let jss = yjs(ttsrv.readTxtFile(wj));
val = val.replace(/[^:\d\[\u2E80-\u9FFF\]\n]/g, "");
val = val.replace(/(\d+):([\u2E80-\u9FFF]+)/g, "【$1】:【$2】");
let a = val.split("\n");
try {
for (let x of a) {
let c = x.split(":") || [];
if (c.length > 1) {
jss[c[1]] = (jss[c[1]] || 0) + 1;
let r = new RegExp(c[0], "g");
tet = tet.replace(r, c[1]);
}
}
ttsrv.writeTxtFile(wj, JSON.stringify(jss));
return tet
} catch (e) {
console.log("错误", e);
}
},
post = (textContent) => {
const selectedModel = "gemini-2.0-flash";
const prompt = `~
# 小说对话角色理解提示词:
1. 对每个说话人:
- 如果能从对话中提取明确的角色名/绰号(如"学堂家老"、"方源"),则填入"姓名"
- 如果完全无法提取角色信息,则根据说话内容从以下 8 种标签选最合适的:
* 少年路人男 / 青年路人男 / 中年路人男 / 老年路人男
* 少年路人女 / 青年路人女 / 中年路人女 / 老年路人女
- (选择角色要灵活运用llm的语言理解能力)
- (禁止创造其他路人标签)
2. 群体场景时,合理分配不同性别标签(避免全部同性别)
# 输出格式(严格JSON):
{
"1": "姓名或路人标签",
"2": "姓名或路人标签",
...
}
# 关键说明:
- "姓名"字段直接填内容,不要额外说明或引用
- 在提取角色信息时,如果单句对话无法确定角色身份,请参考上下文的描述和情节发展判断。
- 角色提取优先级
第一优先级:充分使用你的llm文字理解能力,选择姓名/称谓(如"方源"、"学堂家老")
第二优先级:当且仅当第一优先级找不到时,从以下8个选项中选择最匹配的路人标签。
~
`;
const requestData = {
model: selectedModel,
messages: [{
role: 'user',
content: prompt + textContent
}]
};
const headers = {
'Content-Type': 'application/json',
'Authorization': `Bearer ${API_KEY}` // 建议从环境变量获取
};
try {
const response = ttsrv.httpPost(
'https://kbtit25-gspk2api.hf.space/v1/chat/completions',
JSON.stringify(requestData),
headers
);
const result = JSON.parse(response.body().string());
return result.choices[0]?.message?.content || {};
} catch (error) {
console.error('API请求失败:', error);
return {
error: '分析失败'
};
}
},
};
var yjs = (jsonString) => {
try {
return JSON.parse(jsonString)
} catch {
return {};
}
}
var qjs = () => {
let jss = yjs(ttsrv.readTxtFile("jss.json"));
let a2 = [];
for (let x in jss) {
a2.push([x, jss[x]])
}
a1 = {};
let iu = "";
a2.sort((a, b) => b[1] - a[1]);
a2.forEach((x, i) => {
iu += `juese${i}:"${x}",\n`;
});
iu = iu.replace(/\【|\】/g, "");
console.log(iu);
}
qjs();
在tts server,下载dev版apk
添加导入向硅基发出创建tts请求的插件就能在安卓上听书了。
tts server插件:
server tts插件.zip (9.9 KB)
解压后导入json,或者直接打开方式选择tts server。
除了硅基的插件,还有可白嫖的豆包和火山翻译插件,以及跃阶星辰的插件。
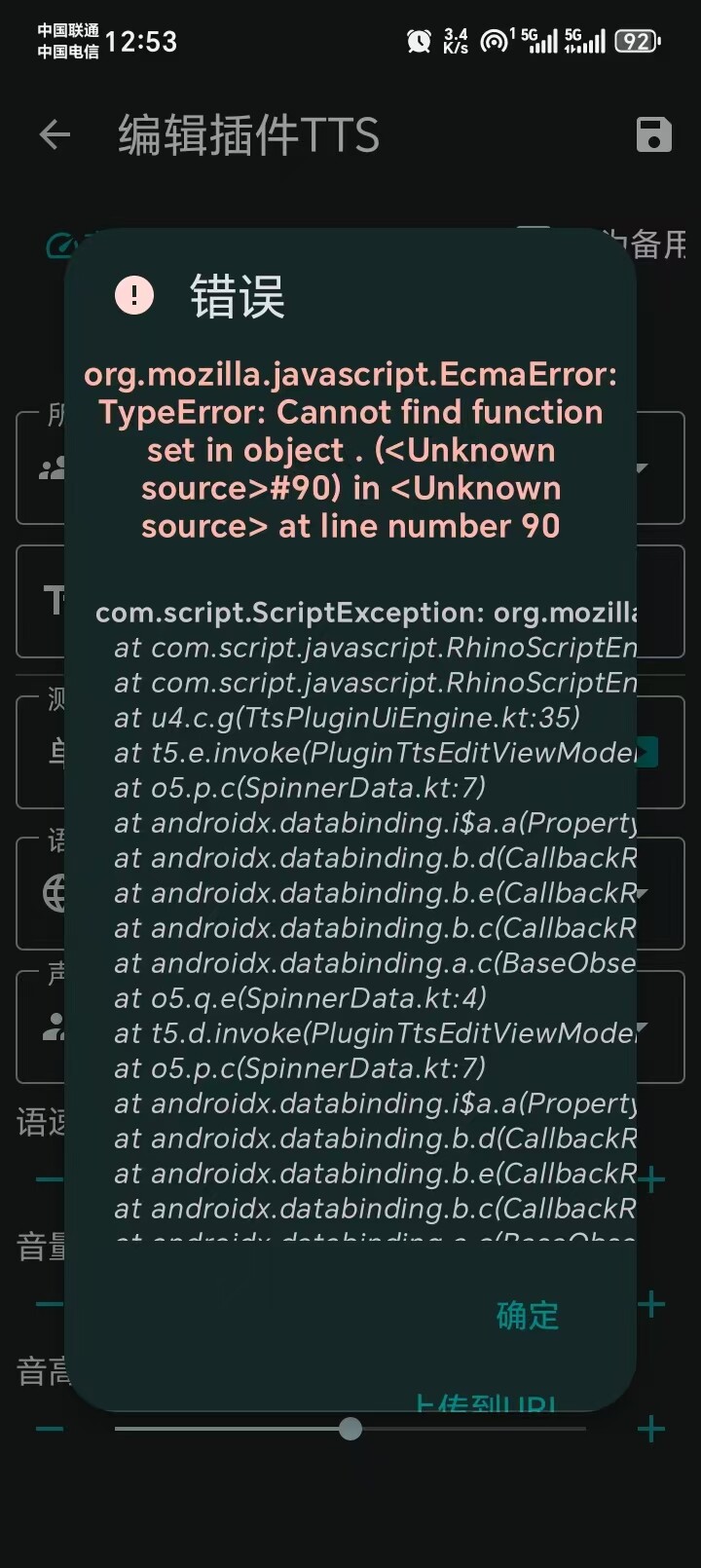
硅基的插件是我把硅基的api手册文档里的接入格式给ai,然后鞭打它催它改的,不懂一点CS,看不懂一行代码,有些地方和tts server配合不是很好,比如流式传播的时候可能会有bug所以默认关的,需要大佬来帮改一下(更改插件代码然后保存后需要退出应用再进才生效)。还有不知道安卓有什么tts方法能缓存预加载音频文件,看可否对系统TTS加入预缓存功能? · Issue #36 · jing332/tts-server-android · GitHub
好像有什么限制?但是应该是很简单的功能吧,如果有人知道的话可以说一下。
配合大佬慷慨的
四万元额度硅基tts,体验最佳。用自己的硅基key的话,需要账号已实名,然后在自定义那里填对应自己的key克隆的音色id,key和音色id是绑定的并不能用别人key克隆的音色。
下面是我这小白的一些使用体验,写给同样小白的
——————
克隆声音,硅基官方的api使用手册页面就支持发出请求
点右边try it,能直接填key,选Opition 2能直接传mp3和wav,然后填你上传的音频对应的文字,右上角按钮发送。查看已克隆音色id列表和删除之类的也都在相应的硅基手册页面直接操作。有了音色id,在tts server自定义音色id那里填就行。如果想要获得mp3,wav之类的音频文件可以本地或者用谷歌的colab发送请求。
克隆对象的参考音频基本决定了你能生成的声音,选择参考音频好像非常有讲究,我完全没掌握到什么是好的参考音频,只能硬试,不过就像抽卡一样也抽到了好的ssr,木成老师(给蛊真人配音热度很高那个)的

自适应非常好感情充沛,但是读应该平淡语气的时候也感情很充沛,用<|endofprompt|>加入分隔的提示词效果一坨,并不好用。用木成老师普通情绪的声音素材克隆的声音明显更适合平淡语气的。木成老师明确说过不准用他的声音ai克隆,不过我们只自己用应该没事。
讲讲我自己的克隆体验,在克隆马保国老师时候,效果最好的参谋音频就是“这两个年轻人不讲武德,来,骗!来,偷袭!我六十九岁的老同志”这句话,保留了大部分我印象中的马保国的声音,但是合成有爆音电流音,不知道如何给参考音频处理能解决这个问题。用"我劝这些年轻人好好反思,耗子尾汁"这句效果又完全没马保国的风格。
克隆木成和马保国的素材的时候,我都是直接找他们没背景音乐的视频,录音或者录屏然后提取音频。
克隆

的方法,是去Fish Audio: 最佳且免费的生成式AI文本转语音和语音克隆
直接克隆别人的克隆,情感自适应感觉不好,可能是素材本就没什么情感,但是音色还行挺像。
希望有听书需求的都可以去试试克隆,同一人不同声音素材克隆出来的效果差别很大,如果你也抽出ssr声音可以分享出来。
目前支持声音克隆的,除了白嫖云端gpu自己搭语音合成模型,就属嫖硅基最好,就算不用大佬的四万元额度tts,一个汉字0.00015额度,从头听完一本700万字的蛊真人要1050,14额度邀请奖励如果用论坛里大佬的方法自己接码成本0.1元,闲鱼买也就0.2以下,十块钱左右听完一本蛊真人。不过如果嫖硅基的人多了肯定就限速或不让薅了。所以最好就我们薅。