开个大模型研究的帖子-如果将pdf文件扔给大模型,然后问大模型关于文档里的内容,
现在的通义千问,文心一言…都是怎么做的呢,将pdf上传,就可以问答案了,我要是自己想实现的例子,现在一点思路都没有
3 个赞
中间件读取内容再丢给模型
有哪些大神,或者做过的技术大佬给些思路和方式吗?
指的是将pdf解析,一段一段的扔给大模型吗?然后大模型把一个pdf内容全部接受后,再允许问问题是吗?
现在大模型都是首先将pdf的内容先转换为文本内容(有的会自动应用OCR),然后喂给大模型
最简单将pdf的内容解析后生成提示词
1 个赞
按段落或者每页扔给大模型,大模型每次可接受的文本总数是有限制的,内部将文本进行切割,一点一点喂,是吗?可接受的文本总数就和大模型以及硬件条件有关了?
import os
import streamlit as st
from langchain.chains import RetrievalQA
from PyPDF2 import PdfReader
from langchain.callbacks.base import BaseCallbackHandler
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Neo4jVector
from streamlit.logger import get_logger
from chains import (
load_embedding_model,
load_llm,
)
# load api key lib
from dotenv import load_dotenv
load_dotenv(".env")
url = os.getenv("NEO4J_URI")
username = os.getenv("NEO4J_USERNAME")
password = os.getenv("NEO4J_PASSWORD")
ollama_base_url = os.getenv("OLLAMA_BASE_URL")
embedding_model_name = os.getenv("EMBEDDING_MODEL")
llm_name = os.getenv("LLM")
# Remapping for Langchain Neo4j integration
os.environ["NEO4J_URL"] = url
logger = get_logger(__name__)
embeddings, dimension = load_embedding_model(
embedding_model_name, config={"ollama_base_url": ollama_base_url}, logger=logger
)
class StreamHandler(BaseCallbackHandler):
def __init__(self, container, initial_text=""):
self.container = container
self.text = initial_text
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.text += token
self.container.markdown(self.text)
llm = load_llm(llm_name, logger=logger, config={"ollama_base_url": ollama_base_url})
def main():
st.header("📄Chat with your pdf file")
# upload a your pdf file
pdf = st.file_uploader("Upload your PDF", type="pdf")
if pdf is not None:
pdf_reader = PdfReader(pdf)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
# langchain_textspliter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, length_function=len
)
chunks = text_splitter.split_text(text=text)
# Store the chunks part in db (vector)
vectorstore = Neo4jVector.from_texts(
chunks,
url=url,
username=username,
password=password,
embedding=embeddings,
index_name="pdf_bot",
node_label="PdfBotChunk",
pre_delete_collection=True, # Delete existing PDF data
)
qa = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever()
)
# Accept user questions/query
query = st.text_input("Ask questions about your PDF file")
if query:
stream_handler = StreamHandler(st.empty())
qa.run(query, callbacks=[stream_handler])
if __name__ == "__main__":
main()
大佬,这就是个例子对吗?
kimi不是之前就这么宣传的吗
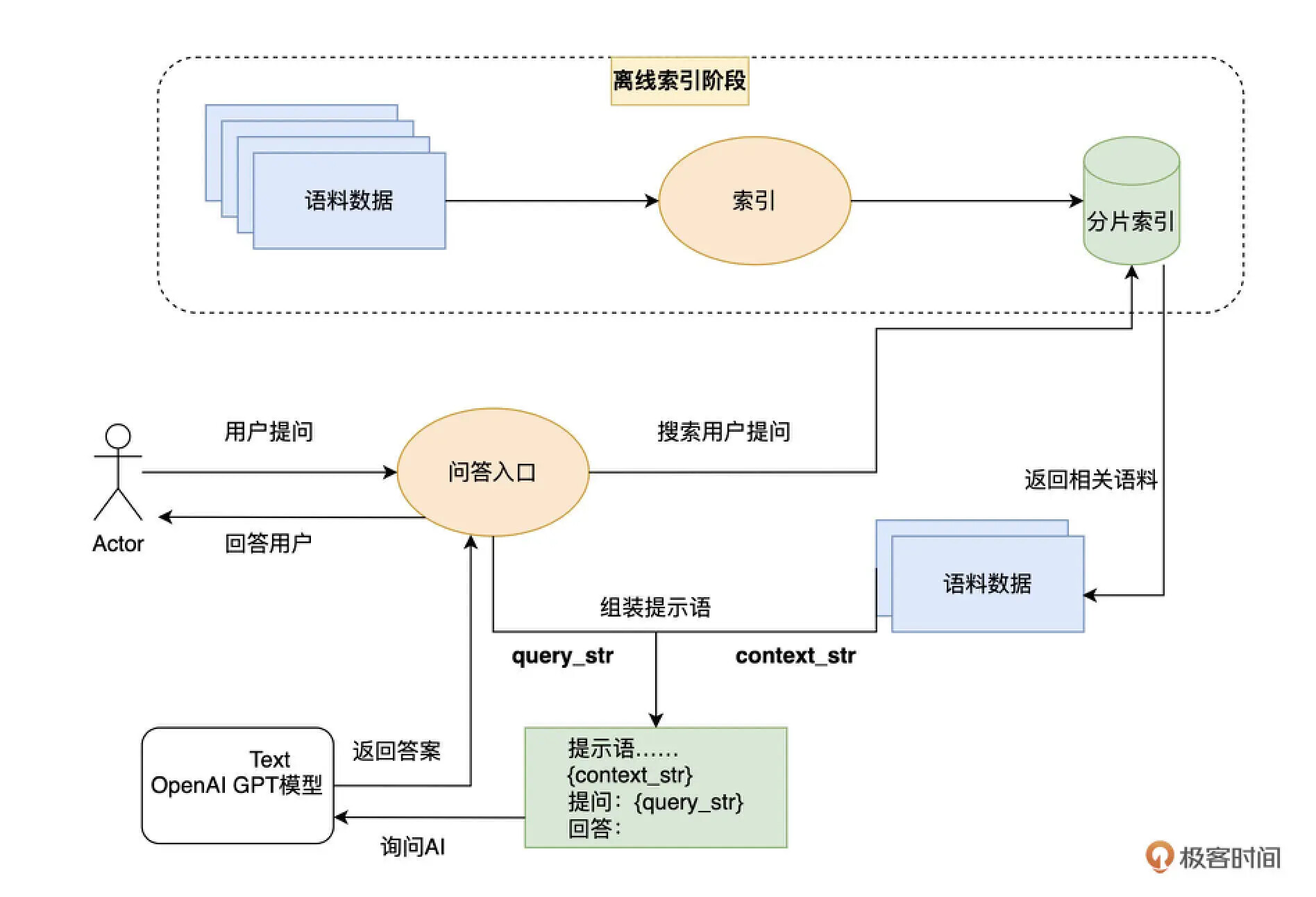
llama-index 其实给出了一种使用大语言模型的设计模式,我称之为“第二大脑”模式。通过先将外部的资料库索引,然后每次提问的时候,先从资料库里通过搜索找到有相关性的材料,然后再通过 AI 的语义理解能力让 AI 基于搜索到的结果来回答问题。
类似的技术或其他方案不少,自己不懂就摘一段课程内容吧。
3 个赞
关键词是RAG,可以尝试一下dify,langchain之类的东西
3 个赞
这图不错
佬 早上号。
中午好,bro
有哪些相关的帖子或资料吗,我作为一个小白,想大体了解一下,做个简单的例子,来实现我的需求,本地将pdf扔给大模型,然后问问题
fastgpt?
我看到一个obsidian插件:
感觉和你说的功能类似。就是他读取是mardown格式文件。这是一种方案可以看下他的方案怎么设计的。
这个是Python的一个实现,genai stack github