这里用的是豆包 Doubao-pro-32k 速度挺快的
内联聊天补全
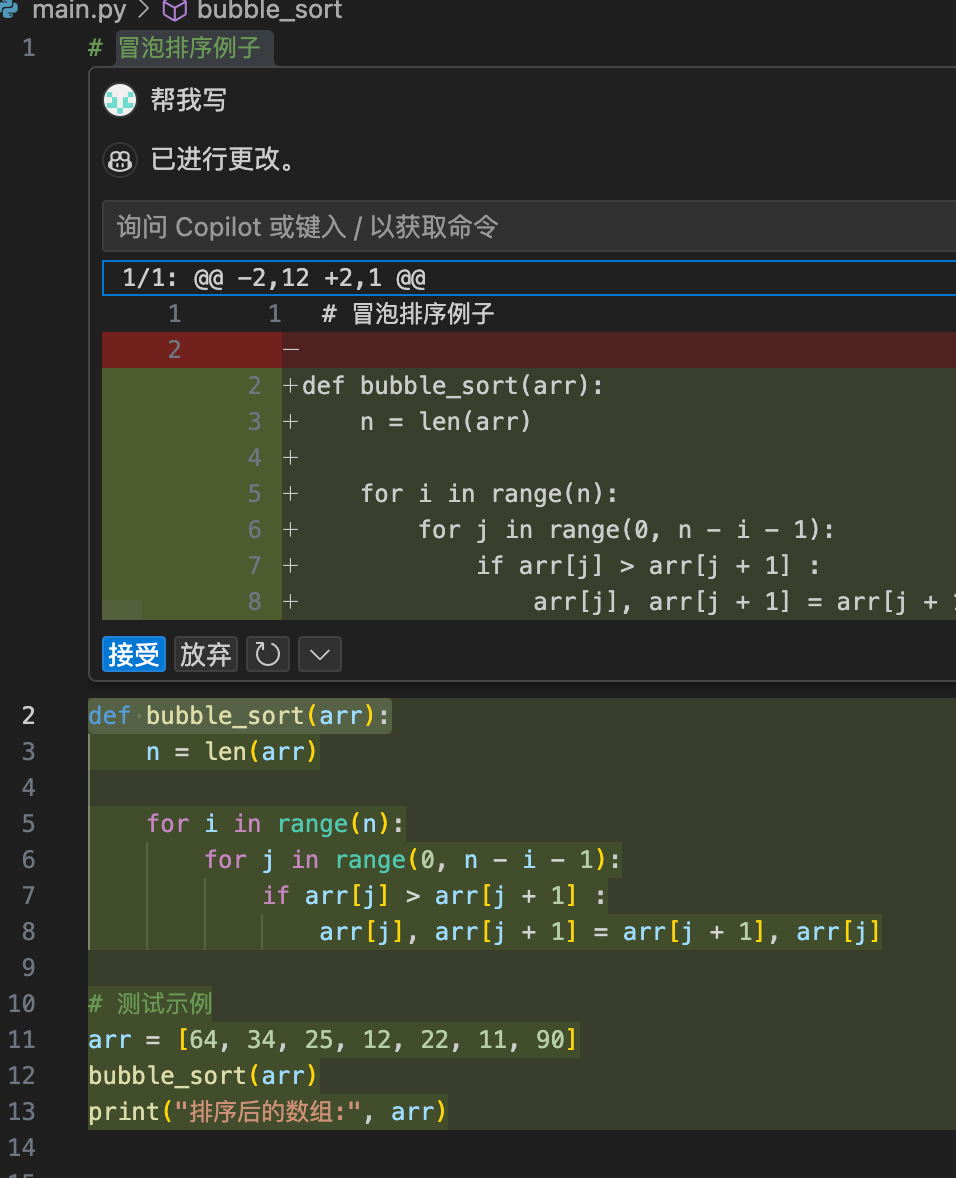
代码补全
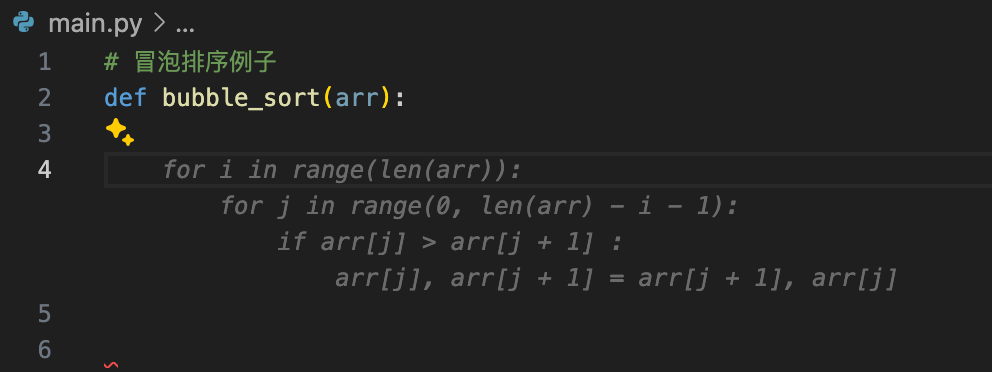
左侧聊天

python 代码
玩的开心
Agently这个库支持一大堆模型自己看文档接入 ollama 本地模型之流也可以接入的
此处无利益相关
阿里通义千问 Qwen - Agently AI应用开发框架
比如使用本地的ollama模型调用qwen2:7b就这样子写 效果和速度也蛮快的
agent_factory = (
Agently.AgentFactory()
.set_settings("current_model", "OAIClient")
.set_settings("model.OAIClient.auth", {"api_key": "abc"})
.set_settings("model.OAIClient.options", {"model": "qwen2:7b"})
.set_settings("model.OAIClient.url", "http://127.0.0.1:11434/v1")
)
完整代码
from flask import Flask, request, Response, stream_with_context
import json
import time
import uuid
import Agently
app = Flask(__name__)
# logging.basicConfig(level=logging.DEBUG)
agent_factory = (
Agently.AgentFactory()
.set_settings("current_model", "OAIClient")
.set_settings("model.OAIClient.auth", {"api_key": "sk-UwGrkEwoeCAwf6Bc3d10C21aCaD34434A23d426a9aB11677"})
.set_settings("model.OAIClient.options", {"model": "Doubao-pro-32k"})
.set_settings("model.OAIClient.url", "http://192.168.100.1:18300/v1")
)
agent = agent_factory.create_agent()
def complete_code(djson):
# prompt = djson['prompt']
# print("prompt",prompt)
prompt = djson # 效果更好
suffix = djson['suffix']
max_tokens = djson['max_tokens']
temperature = djson['temperature']
top_p = djson['top_p']
n = djson['n']
stop = djson['stop']
stream = djson['stream']
model = djson['model']
result = (
agent
.general("""您正在协助完成代码。以下是主要指导原则:
{{input}} 中 # Path: 是文件的路径,请检查后缀名确定编程语言
stop: 这是一个包含停止符的列表,用来告诉模型在生成到这些符号时停止。
suffix: 这是给模型的输入后缀,通常用来提供代码的后续部分,以帮助模型更好地理解上下文。
completion输出内容应像直接写入代码编辑器一样。
completion输出内容可以是代码、注释或字符串。
completion不要提供现有的和重复的代码。
completion始终提供非空的输出。
如果提供的前缀和后缀包含不完整的代码或语句,响应内容应该能直接连接到提供的前缀和后缀。
我可能会告诉你我想在注释中写什么,你需要根据这些指示提供内容。
""")
.info("suffix", suffix)
.info("stop", stop)
.input(prompt)
.set_settings("model.OAIClient.options.temperature", temperature)
.set_settings("model.OAIClient.options.top_p", top_p)
.set_settings("model.OAIClient.options.max_tokens", max_tokens)
.output({
"completion": ("str", "Code Completion Results"),
})
.start()
)
try:
return [result["completion"]]
except:
return [""]
def complete_chat(djson):
# djson = ujson.loads(prompt)
# print(djson)
max_tokens = djson['max_tokens']
temperature = djson['temperature']
top_p = djson['top_p']
n = djson['n']
stream = djson['stream']
model = djson['model']
messages = djson['messages']
# 提取 messages 最后一句话
last_message = messages[-1]['content']
result = (
agent
.chat_history(messages)
.input(last_message)
.set_settings("model.OAIClient.options.temperature", temperature)
.set_settings("model.OAIClient.options.top_p", top_p)
.set_settings("model.OAIClient.options.max_tokens", max_tokens)
.start()
)
# print(result)
return result
def out_text_completion(chat_response, original_model):
chat_contents = []
for i, text in enumerate(chat_response):
chat_content = {
"index": i,
"text": text
}
chat_contents.append(chat_content)
m_uuid = str(uuid.uuid4())
completion_response = {
"id": m_uuid,
"object": "text_completion",
"created": int(time.time()),
"model": original_model,
"choices": chat_contents,
"usage": {'completion_tokens': 10, 'prompt_tokens': 10, 'total_tokens': 10}
}
return completion_response
def out_chat_completion_chunk(chat_response, original_model):
completion_responses = []
m_uuid = str(uuid.uuid4())
for i, text in enumerate(chat_response):
completion_response = {
"id": m_uuid,
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": original_model,
"choices": [{
"index": 0,
"delta": {
"content": text
},
"finish_reason": None
}],
}
if i == len(chat_response) - 1:
completion_response["choices"][0]["finish_reason"] = "stop"
# 加入 usage
completion_response["usage"] = {
"prompt_tokens": 10,
"completion_tokens": 10,
"total_tokens": 10
}
completion_responses.append(completion_response)
ctext = ""
for i, completion_response in enumerate(completion_responses):
ctext = ctext + "data: " + json.dumps(completion_response) + "\n"
return ctext
@app.route('/v1/chat/completions', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH'])
def proxy_chat():
completion_request = request.json
print("得到数据", completion_request)
completion = complete_chat(completion_request)
print("得到回答", completion)
completion_response = out_chat_completion_chunk([completion], completion_request.get('model', 'gpt-4o-mini'))
if not completion_request.get('stream', False):
return json.dumps(completion_response), 200, {'Content-Type': 'application/json'}
def generate():
yield completion_response
yield "data: [DONE]\n\n"
return Response(stream_with_context(generate()), content_type='text/event-stream')
@app.route('/', defaults={'path': ''}, methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH'])
@app.route('/<path:path>', methods=['GET', 'POST', 'PUT', 'DELETE', 'PATCH'])
def proxy(path):
if request.method != 'POST' or 'completions' not in path:
return "This proxy only supports POST requests to completions endpoints", 400
completion_request = request.json
# print("得到数据", json.dumps(completion_request))
print("得到数据", completion_request)
completion = complete_code(completion_request)
print("得到回答", completion)
completion_response = out_text_completion(completion, completion_request.get('model', 'gpt-4o-mini'))
if not completion_request.get('stream', True):
return json.dumps(completion_response), 200, {'Content-Type': 'application/json'}
def generate():
yield f"data: {json.dumps(completion_response)}\n\n"
yield "data: [DONE]\n\n"
return Response(stream_with_context(generate()), content_type='text/event-stream')
if __name__ == '__main__':
app.run(debug=False, host='0.0.0.0', port=5001)
override 配置
{
"bind": "0.0.0.0:8181",
"proxy_url": "",
"timeout": 600,
"codex_api_base": "http://127.0.0.1:5001/v1",
"codex_api_key": "sk-abc",
"codex_api_organization": "",
"codex_api_project": "",
"codex_max_tokens": 500,
"code_instruct_model": "deepseek-coder",
"chat_api_base": "http://127.0.0.1:5001/v1",
"chat_api_key": "sk-abc",
"chat_api_organization": "",
"chat_api_project": "",
"chat_max_tokens": 4096,
"chat_model_default": "deepseek-chat",
"chat_model_map": {
},
"chat_locale": "zh_CN",
"auth_token": ""
}
配置教程1
让Copilot用上DeepSeek总于搞明白了vscode和JetBrainsIDE都能用 - 常规话题 / 人工智能 - LINUX DO
配置教程2 最简单
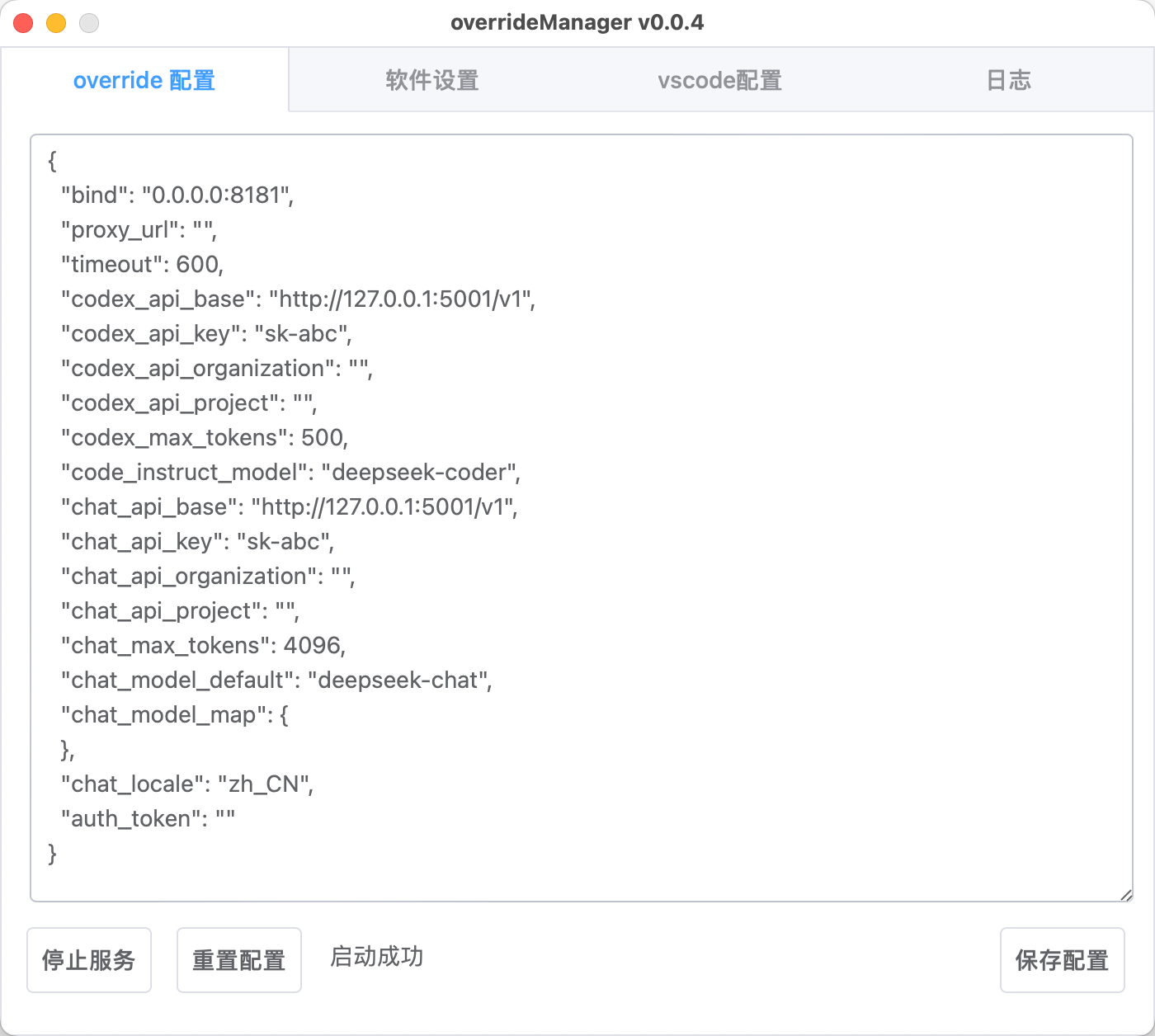
全新玩具,支持window和macos填key就可以直接运行免docker