众所周知O1发布了, 但我看了一下L站跑的test case似乎与Science, technology, engineering, and mathematics (STEM)专业关系不大, 换句话说就是不够难也不够能体现模型的实力, 那有没有什么我们又能看懂又能体现模型实力的测试呢?
当然有, 我们这里介绍两个benchmark: SWE-verify和OlympicArena
这里放一些例子来解释一下这两个数据集:
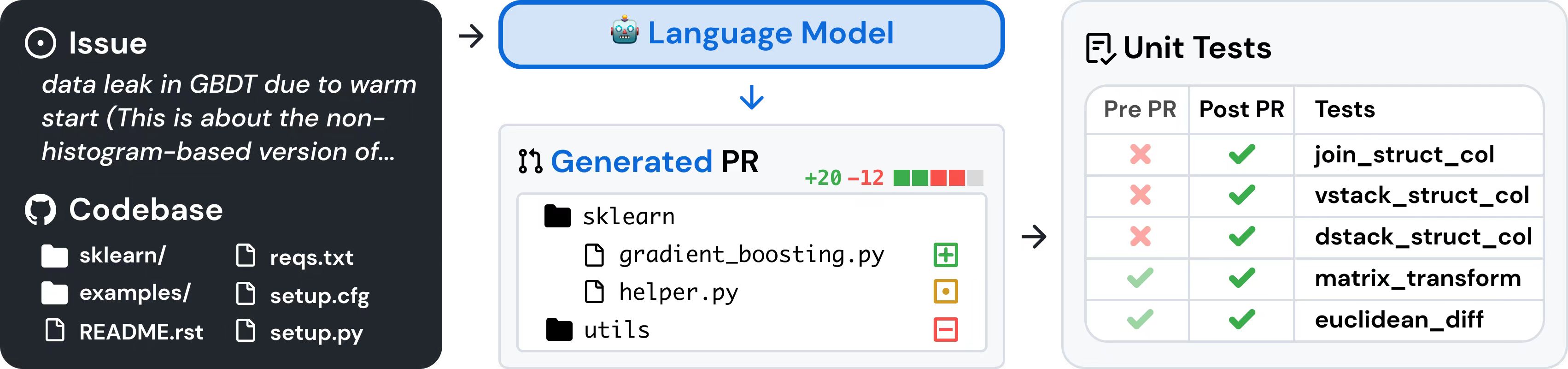
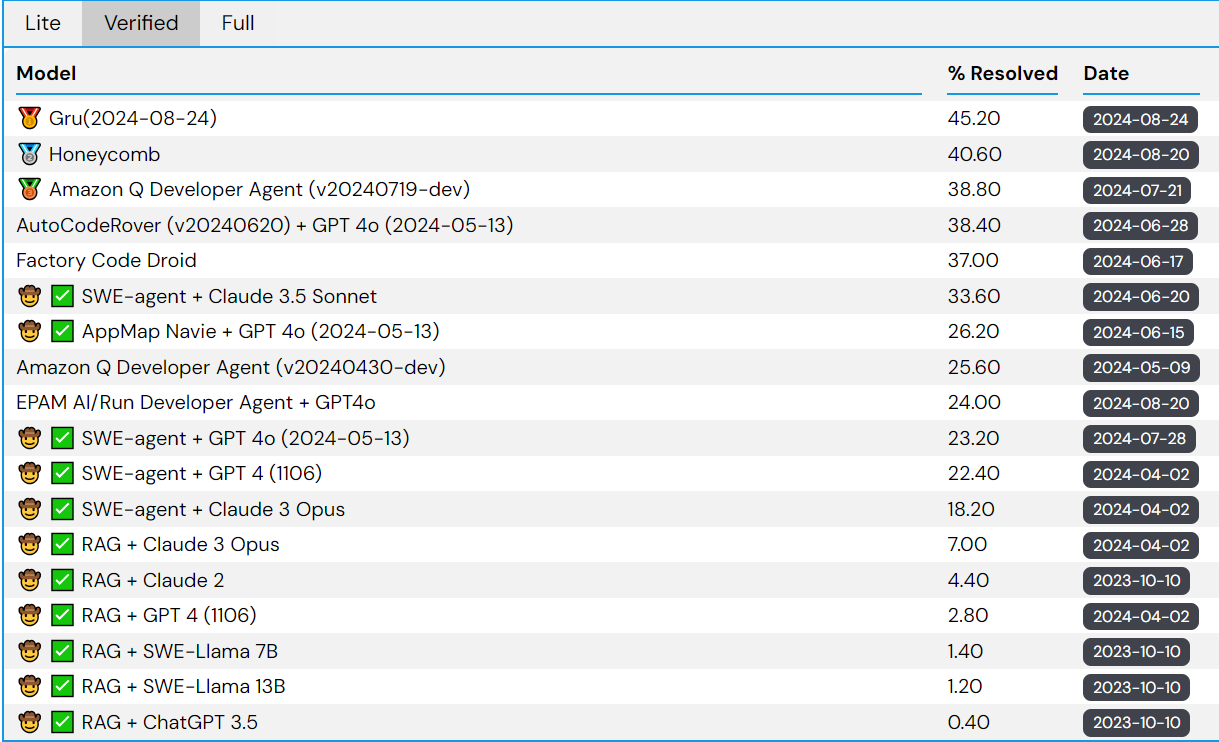
SWE-bench是一个测试系统解决GitHub问题能力的数据集 自动发出问题。该数据集收集了 2,294 个 Issue-Pull 请求 来自 12 个流行 Python 存储库的对。评估是通过使用 PR 后行为作为参考解决方案的单元测试验证来进行的。
在o1之前的模型能力:
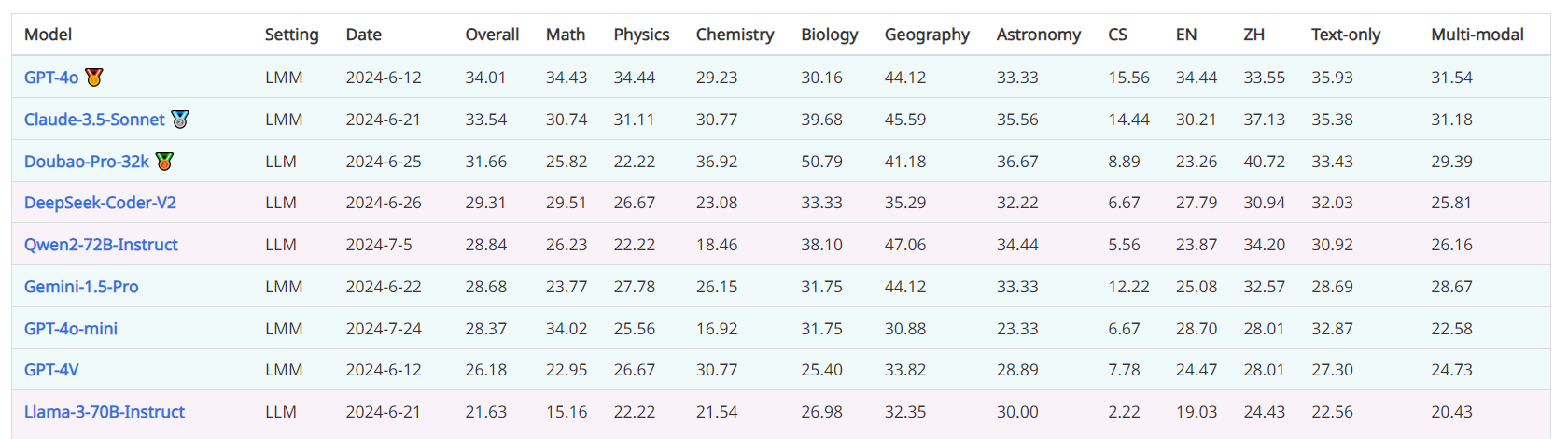
OlympicArena, 一个奥林匹克级别的科学基准
在o1之前的模型能力:
23 个赞
JayNing
标签 更新
4
ChatGPT, OpenAI, #人工智能添加,#纯水移除
应该是没那么快的 快的话可以去看aider,那个应该是测的最快的且比较有信服力的第三方code测评(大概北京时间的早上就出来了差不多), Aider LLM Leaderboards | aider
D-J
(空心人)
7
已知定义在 $R^{+}$上的函数 f(x) 为 f(x)=\left\{\begin{array}{cc}\left|\log _{3} x-1\right|, & 0<x \leq 9 \\ 4-\sqrt{x}, & x>9\end{array}\right.. 设 a, b, c 是三个互不相同的实数, 满足 f(a)=f(b)=f(c), 求 a b c 的取值范围.
这题答对了,81到144
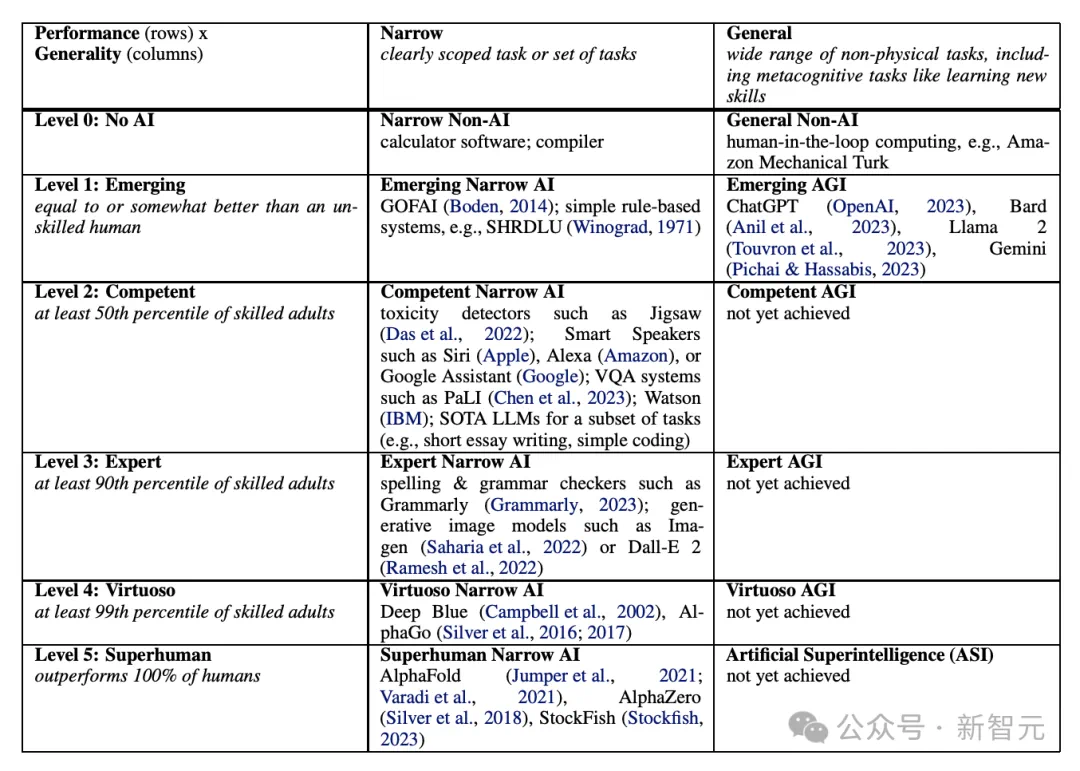
你这个大概率是做不到的,oai 目前的目标是攻克从 L1 到 L2 的路线(彭博独家报道,OpenAI一位高管表示,目前正处在第一级别,不过很快会达到第二个级别,即推理者。所谓推理者,也就是指可以解决博士水平的基本问题的系统。),而数学建模这种东西大概是 L3 级别的
L1:聊天机器人,具有对话能力的AI。
L2:推理者,像人类一样能够解决问题的AI。
L3:智能体,不仅能思考,还可以采取行动的AI系统。
L4:创新者,能够协助发明创造的AI。
L5:组织者,可以完成组织工作的AI。
1 个赞
分数终于能直接算对了,之前给我用代码解释器写代码运行
关于o1 目前 Plus 用户有使用次数的限制吗?
ChatGPT Plus 和团队用户今天开始可以访问 o1 模型。o1-preview 和 o1-mini 可以在模型选择器中手动选择,启动时,o1-preview 每周限制为 30 条消息,o1-mini 为 50 条。我们正在努力提高这些限制,并使 ChatGPT 能够自动选择给定提示的正确模型。
aider
很有意思的结果,o1 的 diff 较差,但 whole 是目前最高,这可以引起一些写代码的思考,比如说这个模型更适合用来重构代码而不是填充代码
1 个赞
不是whole最高,是他的diff不好所以搞个whole看看,diff好的我记得paul是不会去测whole的,因为给whole在日常使用中不管是速度、成本还是上下文能容纳的量,都是非常差的
2 个赞