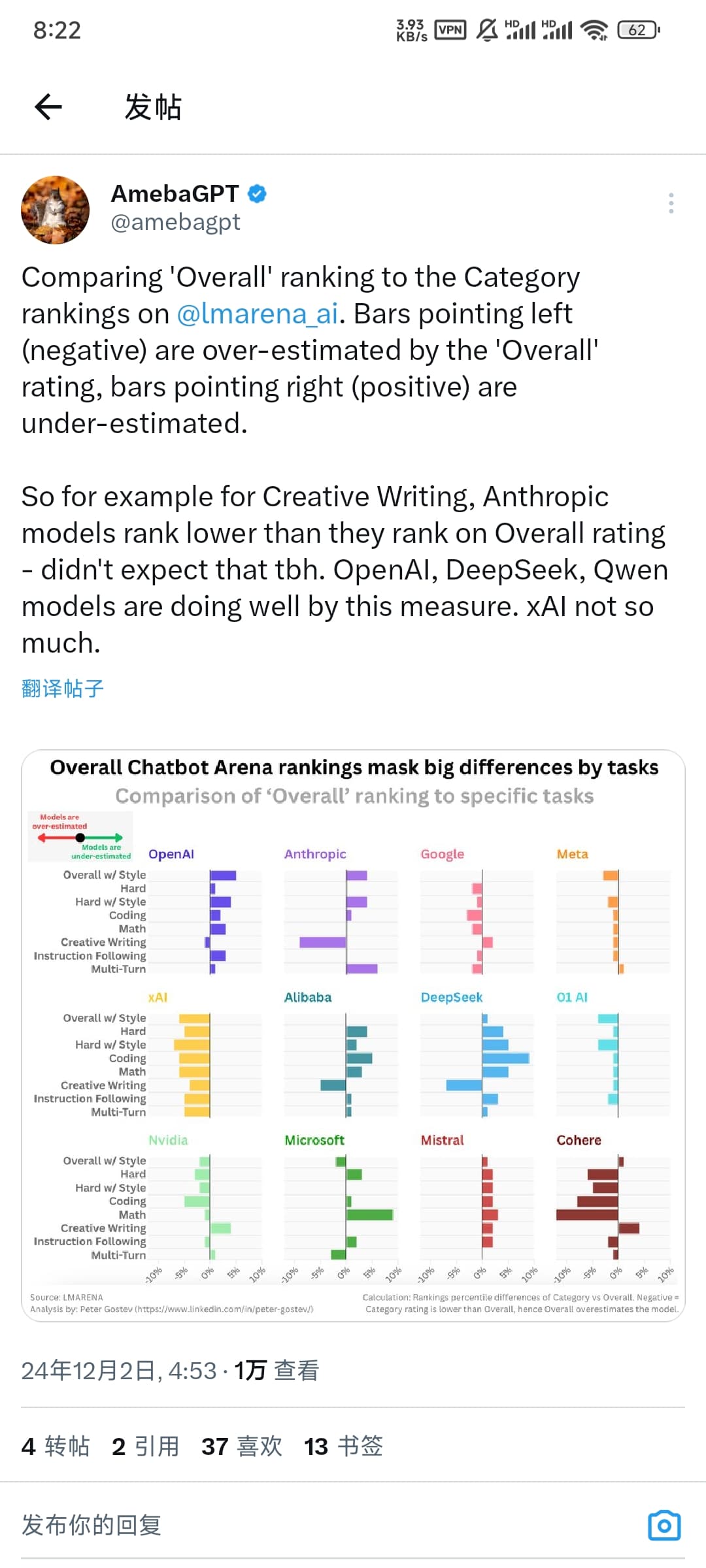
lmarena转发了下图
左侧被高估,右侧被低估
国内模型不错啊
最近我在写论文,正好对比了下
总体感觉还是claude最好
国内qwen,deep,glm plus, 01,感觉差不多
plus并没有特别优势
01感觉说的很多,很像人说的(看图也被高估了)
gemini 1121没看出优势,没感受到大家说的更人性化
xai感觉不错,感觉比1121好
可这图也太扯了
感觉和实际不符合
lmarena转发了下图
左侧被高估,右侧被低估
国内模型不错啊
最近我在写论文,正好对比了下
总体感觉还是claude最好
国内qwen,deep,glm plus, 01,感觉差不多
plus并没有特别优势
01感觉说的很多,很像人说的(看图也被高估了)
gemini 1121没看出优势,没感受到大家说的更人性化
xai感觉不错,感觉比1121好
可这图也太扯了
感觉和实际不符合
xai算了吧,国内的step还行,跟kimi差不多
可我实际感觉xai还不错,感觉比1121好
可能嫌弃1121太慢了
哈哈
lmarea有个问题是
你不知道他的温度和top p是怎么设置的,有没有添加特殊的system prompt。
我用来给文章总结,4o 1120的回复一骑绝尘
然而实际用起来,同样的问题回答的很一般
到底是lm还是im?
你的感觉是不是。。。有点多了 ![]()
是Lm,手滑打错了
lmarena.ai是通过用户投票来排名的,这种本身就不具备专业性
有没啥专业点的排名???
livebench,aider llm
从我的使用来看,感觉livebench.ai要更准确一些
我感觉差点意思,但无审诶
看着挺主观的评分。自己感觉上Gemini, Claude, GPT似乎还略符合。Claude英语写作是不差,但是遣词造句还没GPT好用。Gemini其他能力一般,写作system prompt做好的话其实手动调整一下就好了,不需要反复生成好几遍。 别的用的少就没啥心得了。Grok这样是说喂原题刷分了吗 ![]()
这图比较的是各家模型的分项排名与总体排名的关系吧,基准是模型的总体排名。低估与高估也是相较于自己的总体排名而言的。
意思是选择模型用于特定任务(如编程、数学、创意写作等)的时候,应该关注模型在该任务类别的具体表现,而不要只看总体排名。
这里面的 microsoft 指的是 phi 把?
我自己用的感觉还是 chatgpt 和 claude 最好
microsoft 的 copilot 应该用的是 chatgpt?反正也比谷歌的好用
gemini 无论是 flash 还是 1121 都感觉一般般,可能是因为我用中文。