版权声明
这些笔记基于《Python for Data Analysis, 3rd Edition》一书的内容总结和理解。原书由 Wes McKinney 编写,出版商为 O’Reilly,ISBN 978-1-098-10403-0。版权声明如下:
MIT License
Original work Copyright (c) 2024 Wes McKinney
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
起来晚了,终于可以开始新的知识了Numpy 我大概浏览了一遍,知识点太多了,就先学如何创建 numpy.ndarray 数组对象吧,以及创建对象的一些常用函数,大体上也十分简单,就是将可迭代对象转为数组,有些函数可以默认值全 0 全 1 或 全随机 还有自定义默认值 和 对角线全 1 ,可能也是受基础知识的影响,理解起来没难度
剩余的时间除了练习今天的知识,我想也应该象征性的练习一下昨天的基础内容,这样,加深印象,我才能了解这本书在讲些什么?
The NumPy ndarray: A Multidimensional Array Object
主要知识点
-
NumPy 简介:
- NumPy(音标:/ˈnʌmˌpaɪ/),全称 Numerical Python(音标:/njuːˈmɛrɪkəl ˈpaɪθɑːn/),是用于 Python 的重要数值计算库。
- 许多科学计算包使用 NumPy 的数组对象作为数据交换的标准接口。
-
NumPy 的主要功能:
ndarray:高效的多维数组,提供快速的数组运算和灵活的广播功能。- 数学函数:可以在整个数组上进行快速操作,而无需编写循环。
- 读/写数组数据的工具和处理内存映射文件的能力。
- 线性代数、随机数生成和傅里叶变换功能。
- C API:与 C、C++ 或 FORTRAN 编写的库连接。
-
NumPy 的优点:
- 存储效率高:数据存储在连续的内存块中。
- 计算效率高:无需 Python 的循环,直接对整个数组进行复杂计算。
-
NumPy 的历史背景:
- NumPy 的前身是 Numeric 库,由 Jim Hugunin 于 1995 年创建。2005 年,Travis Oliphant 将 Numeric 和 Numarray 项目整合,创建了 NumPy 项目。
-
NumPy 的效率:
- NumPy 通过将数据存储在连续的内存块中,并使用 C 语言编写的高效算法,减少了类型检查和其他开销,因此计算速度比普通 Python 代码快很多。
Creating ndarrays
一些主要的 NumPy 数组创建函数
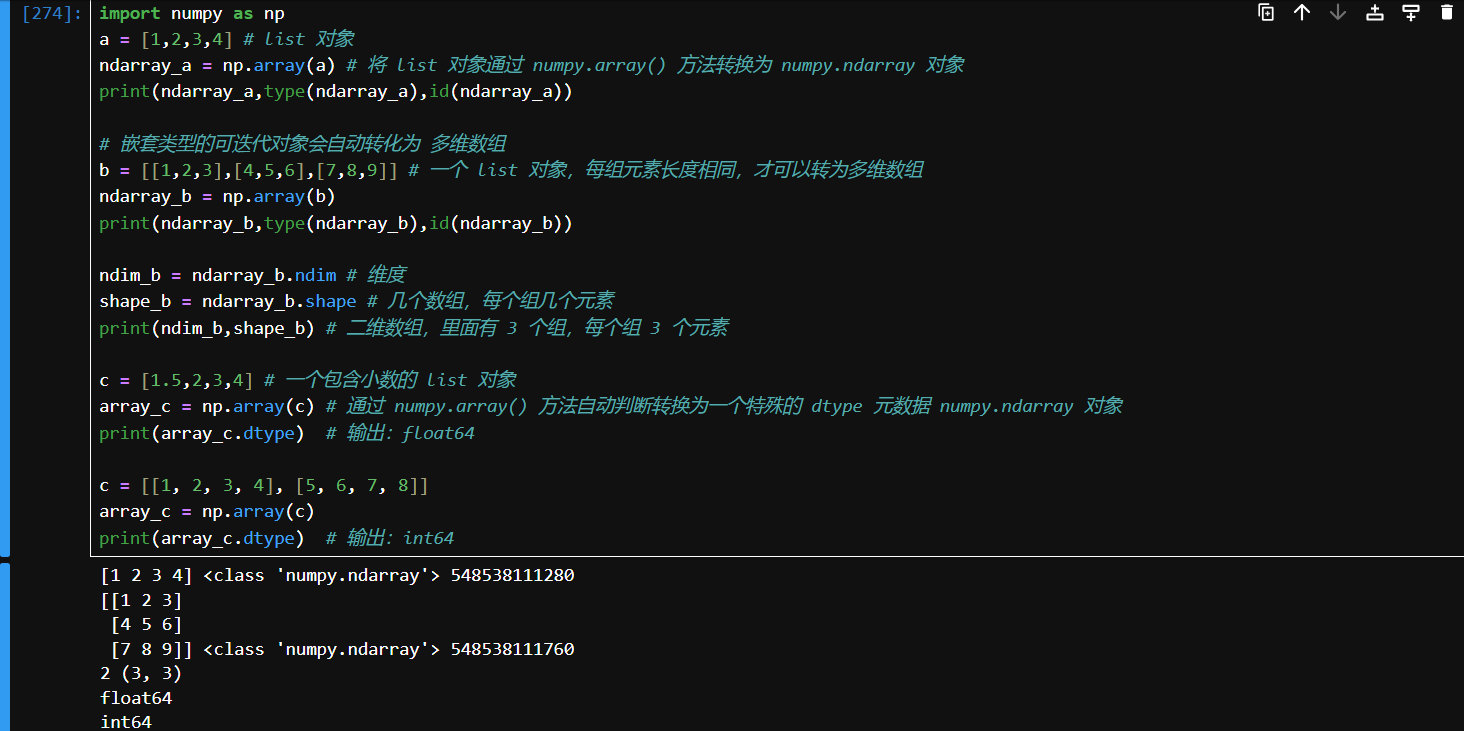
array
- 将输入数据(列表、元组、数组或其他序列类型)转换为 ndarray 对象,可以通过推断或明确指定数据类型;默认情况下会复制输入数据。
- 嵌套类型的输入数据(列表、元组、数组或其他序列类型)将会转为多维 ndarray 对象,需要注意的是嵌套类型的输入数据每组对象元素的个数需要相同,这是因为 NumPy 需要创建一个形状一致的多维数组。如果每组对象的元素个数不同,NumPy 无法推断出合适的数组形状,就会报错。
- 可肉眼通过打印的排列形状判断是几维数组以及包含几组,每个组包含了多少元素,书中也提供了
ndim和shape属性来确认这一点。- 数据类型存储在一个特殊的
dtype元数据 ndarray 对象中。- 如果没有显式指定数据类型 (
dtype),numpy.array()会尝试为所创建的数组推断一个合适的数据类型。
import numpy as np
a = [1,2,3,4] # list 对象
ndarray_a = np.array(a) # 将 list 对象通过 numpy.array() 方法转换为 numpy.ndarray 对象
print(ndarray_a,type(ndarray_a),id(ndarray_a))
# 嵌套类型的可迭代对象会自动转化为 多维数组
b = [[1,2,3],[4,5,6],[7,8,9]] # 一个 list 对象,每组元素长度相同,才可以转为多维数组
ndarray_b = np.array(b)
print(ndarray_b,type(ndarray_b),id(ndarray_b))
ndim_b = ndarray_b.ndim # 维度
shape_b = ndarray_b.shape # 几个数组,每个组几个元素
print(ndim_b,shape_b) # 二维数组,里面有 3 个组,每个组 3 个元素
c = [1.5,2,3,4] # 一个包含小数的 list 对象
array_c = np.array(c) # 通过 numpy.array() 方法自动判断转换为一个特殊的 dtype 元数据 numpy.ndarray 对象
print(array_c.dtype) # 输出:float64
c = [[1, 2, 3, 4], [5, 6, 7, 8]]
array_c = np.array(c)
print(array_c.dtype) # 输出:int64
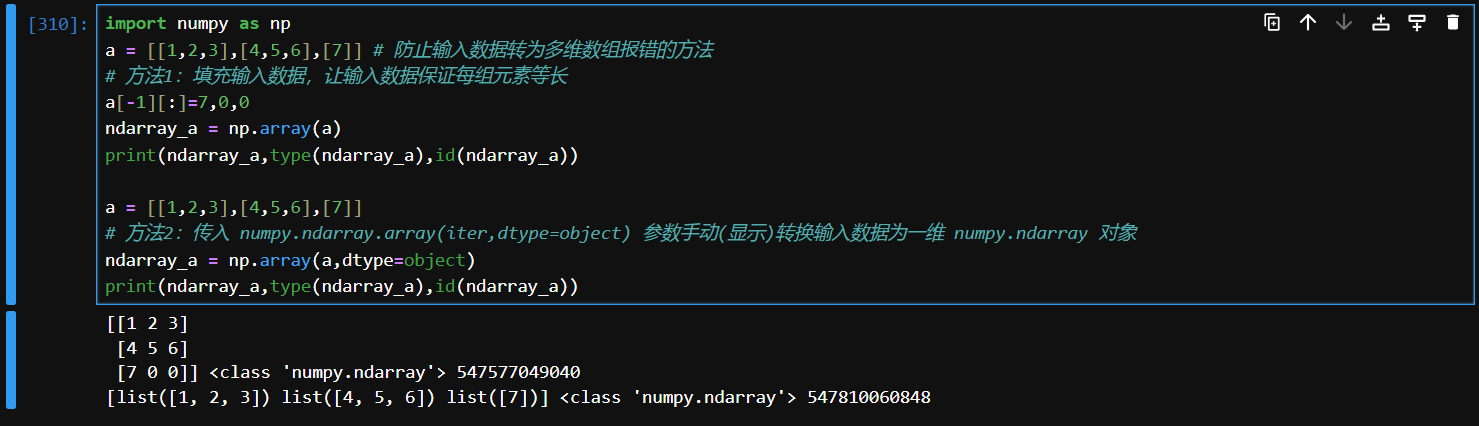
如果需要将不同长度的嵌套列表转换为 NumPy 数组,可以考虑以下几种方法:
- 填充嵌套列表:将所有内部列表填充到相同长度。
- 使用对象数组:将
dtype指定为object类型。
- 将
dtype=object参数传入 numpy.array() 手动(显示)转换输入数据为一维 numpy.ndarray 对象
import numpy as np
a = [[1,2,3],[4,5,6],[7]] # 防止输入数据转为多维数组报错的方法
# 方法1:填充输入数据,让输入数据保证每组元素等长
a[-1][:]=7,0,0
ndarray_a = np.array(a)
print(ndarray_a,type(ndarray_a),id(ndarray_a))
a = [[1,2,3],[4,5,6],[7]]
# 方法2:传入 numpy.ndarray.array(iter,dtype=object) 参数手动(显示)转换输入数据为一维 numpy.ndarray 对象
ndarray_a = np.array(a,dtype=object)
print(ndarray_a,type(ndarray_a),id(ndarray_a))
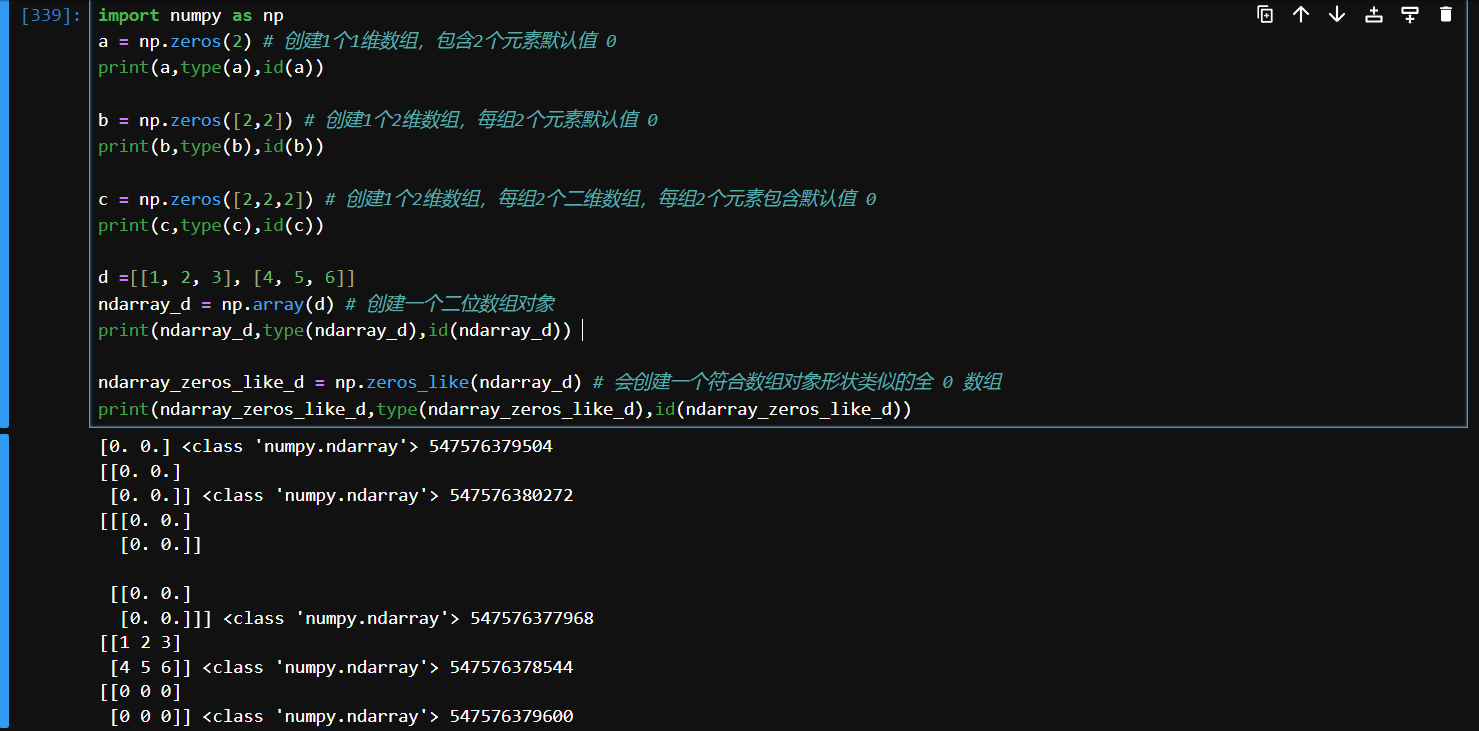
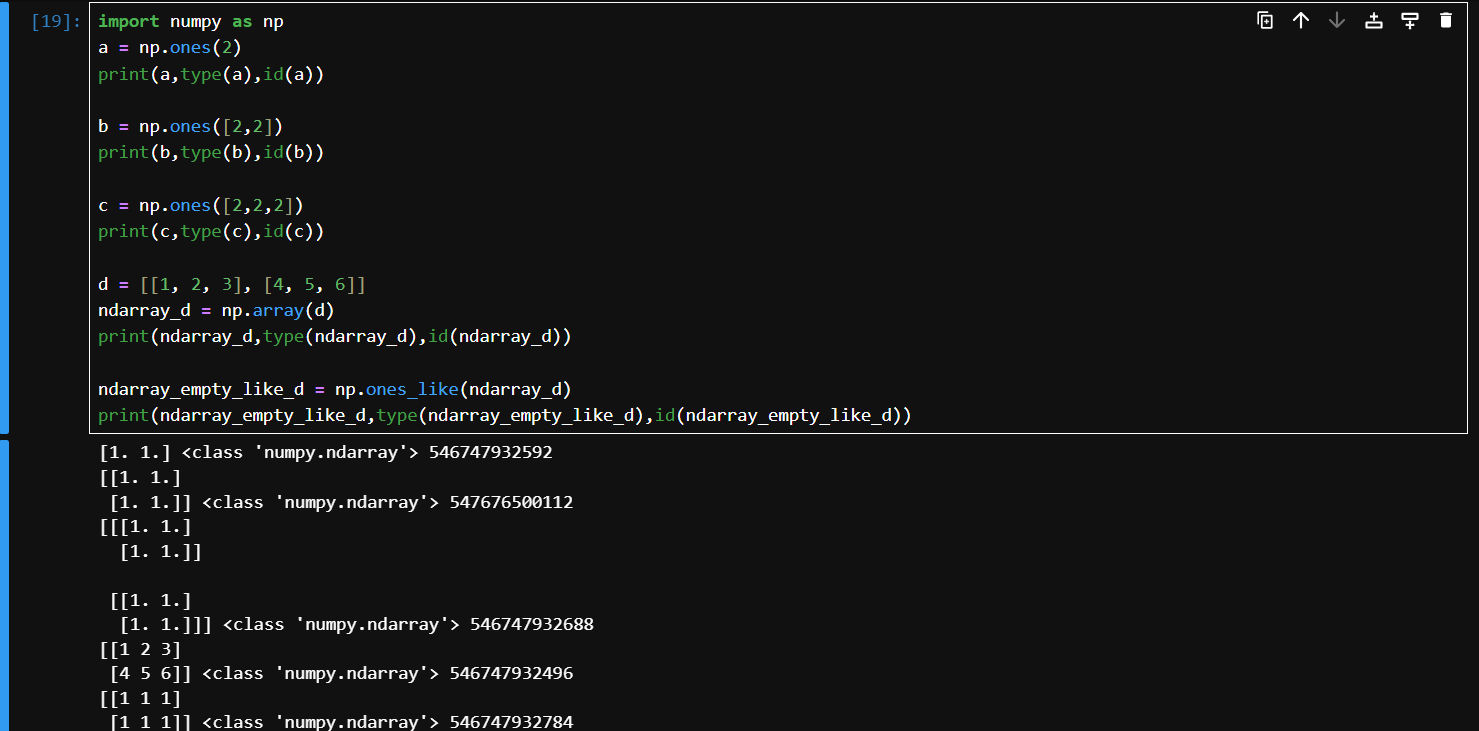
zeros, zeros_like
numpy.zeros()生成具有给定形状和数据类型的全 0 数组;numpy.zeros_like()根据另一个数组生成相同形状和数据类型的全 0 数组。
import numpy as np
a = np.zeros(2) # 创建1个1维数组,包含2个元素默认值 0
print(a,type(a),id(a))
b = np.zeros([2,2]) # 创建1个2维数组,每组2个元素默认值 0
print(b,type(b),id(b))
c = np.zeros([2,2,2]) # 创建1个2维数组,每组2个二维数组,每组2个元素包含默认值 0
print(c,type(c),id(c))
d =[[1, 2, 3], [4, 5, 6]]
ndarray_d = np.array(d) # 创建一个二位数组对象
print(ndarray_d,type(ndarray_d),id(ndarray_d))
ndarray_zeros_like_d = np.zeros_like(ndarray_d) # 会创建一个符合数组对象形状类似的全 0 数组
print(ndarray_zeros_like_d,type(ndarray_zeros_like_d),id(ndarray_zeros_like_d))
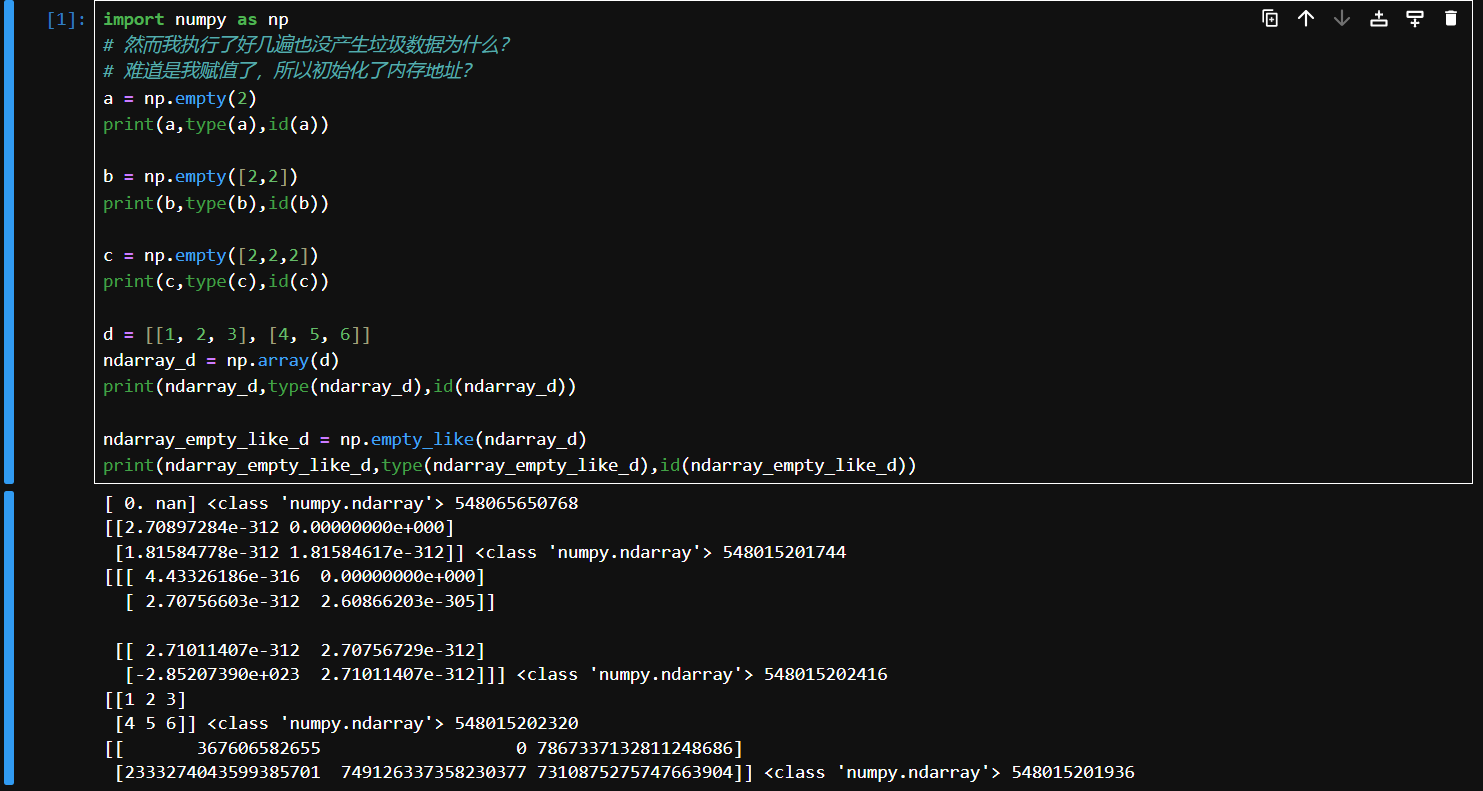
empty, empty_like
- 通过分配新内存创建新数组,
numpy.empty()生成具有给定形状和数据类型的数组;numpy.empty_like()根据另一个数组生成相同形状和数据类型的数组。但不像numpy.ones()和numpy.zeros()那样初始化数值。numpy.empty()并不会返回一个全零数组。这个函数返回的是未初始化的内存,因此数组可能包含伪随机非零的“垃圾”值。只有当你打算为新数组填充数据时,才应该使用这个函数
import numpy as np
a = np.empty(2) # 创建1个1维数组,包含2个元素默认值随机
print(a,type(a),id(a))
b = np.empty([2,2]) # 创建1个2维数组,每组2个元素默认值随机
print(b,type(b),id(b))
c = np.empty([2,2,2]) # 创建1个2维数组,每组2个二维数组,每组2个元素包含默认值随机
print(c,type(c),id(c))
d = [[1, 2, 3], [4, 5, 6]]
ndarray_d = np.array(d) # 创建一个二位数组对象
print(ndarray_d,type(ndarray_d),id(ndarray_d))
ndarray_empty_like_d = np.empty_like(ndarray_d) # 会创建一个符合数组对象形状类似的随机值的数组
print(ndarray_empty_like_d,type(ndarray_empty_like_d),id(ndarray_empty_like_d))
arange
- 类似于内置的 range 函数,但返回 ndarray 对象而不是 list 对象。
import numpy as np
ndarray_a = np.arange(10)
print(ndarray_a,type(ndarray_a),id(ndarray_a))

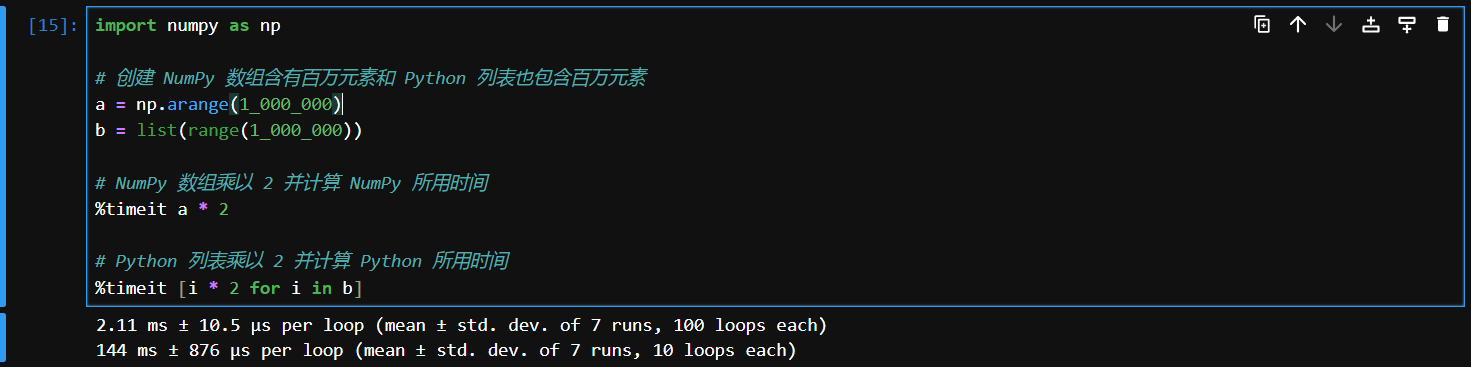
%timeit
%timeit是一个 IPython 解释器的魔法命令,用于测量一段代码的执行时间。它会自动多次运行代码片段并报告其平均执行时间。解释
%timeit a * 2:测量 NumPy 数组的运算时间。%timeit [i * 2 for i in b]:测量 Python 列表的运算时间。注意事项
%timeit会多次运行代码并输出平均执行时间及标准偏差。- 在使用
%timeit时,请确保代码片段不会改变全局状态,因为它会多次执行。这段代码也证明在同样海量数据前提下 NumPy 数组对象处理数据速度远高于 Python 的 list 对象
import numpy as np
# 创建 NumPy 数组含有百万元素和 Python 列表也包含百万元素
a = np.arange(1_000_000)
b = list(range(1_000_000))
# NumPy 数组乘以 2 并计算 NumPy 所用时间
%timeit a * 2
# Python 列表乘以 2 并计算 Python 所用时间
%timeit [i * 2 for i in b]
ones, ones_like
numpy.ones()生成具有给定形状和数据类型的全 1 数组;numpy.ones_like()根据另一个数组生成相同形状和数据类型的全 1 数组。
import numpy as np
a = np.ones(2) # 创建1个1维数组,包含2个元素默认值 1
print(a,type(a),id(a))
b = np.ones([2,2])# 创建1个2维数组,每组2个元素默认值 1
print(b,type(b),id(b))
c = np.ones([2,2,2])# 创建1个2维数组,每组2个二维数组,每组2个元素包含默认值 1
print(c,type(c),id(c))
d = [[1, 2, 3], [4, 5, 6]]
ndarray_d = np.array(d)# 创建一个二位数组对象
print(ndarray_d,type(ndarray_d),id(ndarray_d))
ndarray_empty_like_d = np.ones_like(ndarray_d)# 会创建一个符合数组对象形状类似的全 1 数组
print(ndarray_empty_like_d,type(ndarray_empty_like_d),id(ndarray_empty_like_d))
asarray
- 将输入转换为 ndarray,如果输入已经是 ndarray,则不进行复制。
import numpy as np
a = [1, 2, 3, 4, 5]
ndarray_a = np.asarray(a) # 将可迭代对象转为 numpy 数组对象
print(ndarray_a,type(ndarray_a),id(ndarray_a))
ndarray_a = np.asarray(ndarray_a) # 如果可迭代对象是 numpy 数组对象,则不复制
print(ndarray_a,type(ndarray_a),id(ndarray_a))

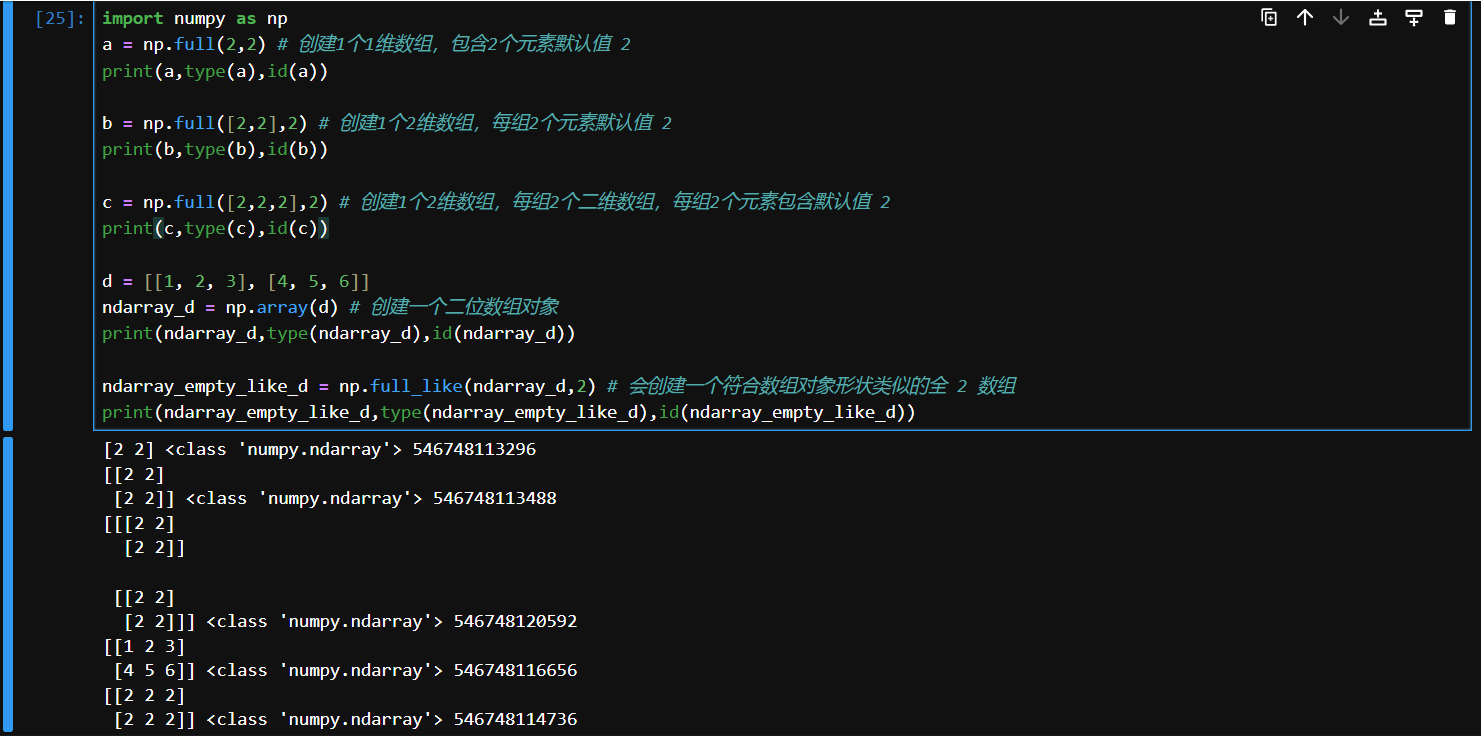
full, full_like
numpy.full()生成具有给定形状和数据类型的数组,所有值都设置为指定的填充值;numpy.full_like()根据另一个数组生成相同形状和数据类型的填充数组。
import numpy as np
a = np.full(2,2) # 创建1个1维数组,包含2个元素默认值 2
print(a,type(a),id(a))
b = np.full([2,2],2) # 创建1个2维数组,每组2个元素默认值 2
print(b,type(b),id(b))
c = np.full([2,2,2],2) # 创建1个2维数组,每组2个二维数组,每组2个元素包含默认值 2
print(c,type(c),id(c))
d = [[1, 2, 3], [4, 5, 6]]
ndarray_d = np.array(d) # 创建一个二位数组对象
print(ndarray_d,type(ndarray_d),id(ndarray_d))
ndarray_empty_like_d = np.full_like(ndarray_d,2) # 会创建一个符合数组对象形状类似的全 2 数组
print(ndarray_empty_like_d,type(ndarray_empty_like_d),id(ndarray_empty_like_d))
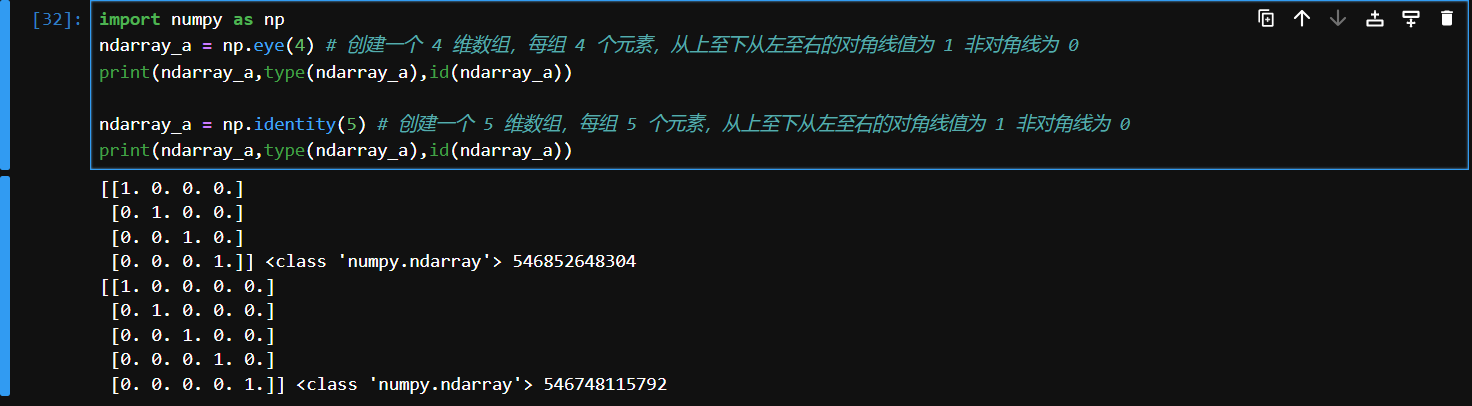
eye, identity
- 创建一个 N x N 的单位矩阵(对角线为 1,其他位置为 0)。
import numpy as np
ndarray_a = np.eye(4) # 创建一个 4 维数组,每组 4 个元素,从上至下从左至右的对角线值为 1 非对角线为 0
print(ndarray_a,type(ndarray_a),id(ndarray_a))
ndarray_a = np.identity(5) # 创建一个 5 维数组,每组 5 个元素,从上至下从左至右的对角线值为 1 非对角线为 0
print(ndarray_a,type(ndarray_a),id(ndarray_a))
参考
The NumPy ndarray: A Multidimensional Array Object
Creating ndarrays