https://cloud.sambanova.ai/apis 高速度的Qwen2.5-72B-Instruct和Qwen2.5-Coder-32B-Instruct,可以用于沉浸式翻译,20rpm
沉浸式调成最大token 2600,最大段落1000 ,体验很好
70 个赞
感谢大佬!!!
3 个赞
之前用llama3.1 405b,最开始的时候是逆向的它家的网页版。后来限制必须登陆了,就申请了它家的key,真没想到它家也有qwen了,就是不知道仍然免费不?
2 个赞
免费 rpm20
5 个赞
这么点小公司,我以为它早就被薅秃了,没想到还活着![]()
还没有付费计划,估计和groq一样花风投的钱换市场
风投:我成冤大头了![]()
多谢分享,对于不用于生产的用途,体验很好
2 个赞
感谢分享,现在这俩我用的是cloudflare worker部署的huggingface转api,个人给nextchat用感觉也够了
2 个赞
这个上下文长度限制了8k,适合做翻译,速度特别快
qwen现在推理还是qwq好吧
我去快到起飞![]()
1 个赞
我基本用的都是官网 “qwen-max” 模型
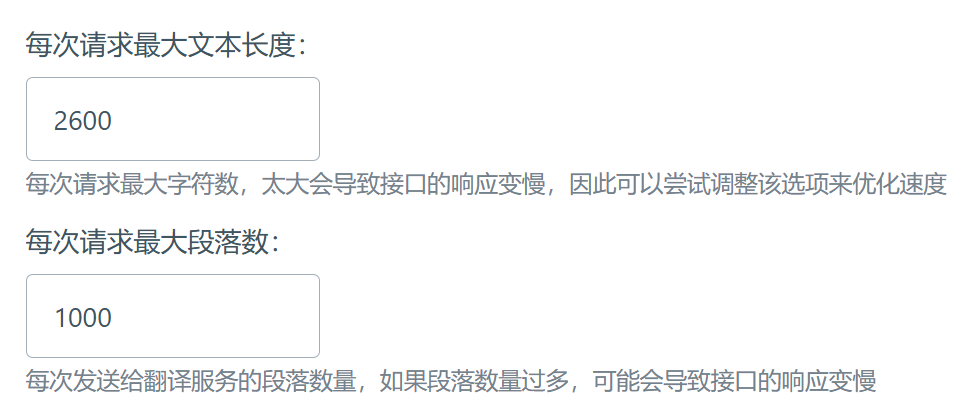
我也是这样…
2 个赞
看起来很香,感谢分享
他这个rpm只有20,最后弄三四个号的密钥一起填进去,轮训
用,分离就可以
他这个rpm只有20,最后弄三四个号的密钥一起填进去,轮训
用,分离就可以了
1 个赞
那是沉浸式翻译的问题
就算设了最大段落,仍然会因为网站的元素判定做单独请求
可以在开发者设置那边设置只翻译部分元素作为缓解
或者用Cursor撸个代码,把单独的元素引导到别的AI或者不翻译
看起来很香,感谢分享