佬用硅基的话一般用哪个模型?
从代码补全来说,我个人体验阿里云的qwen已经能满足我的需求了,遇到有错误的我就用cline调用deepseek读一下文件找问题,然后再配合其他模型解决问题,我觉得这是比较具有性价比不折腾的方法 ![]()
![]()
但是涨价四倍确实有点太多了,我昨天消耗了3464317 tokens,折合0.78RMB大概,如果翻四倍就是三块钱,好贵啊 ![]()
1 个赞
我用deepseek因为我不是专业写程序的
偶尔用用,还行
按量计算的好
插个眼,观望一下
主要是jb上面好用的补全插件就copilot
还是deepseek用的多一点
佬可以按照涨价后的价格算一下,我自己算了一下是比买copilot贵的,但是比cursor便宜点。按照你这个token用量来算的话价格都比的上cursor了
用这个做补全的真是富哥 目前没涨价,我说的是涨价之后的结论
3 个赞
如果是代码补全的情况,大部分消耗应该都是输入,应该还会命中缓存,只不过它缓存输入涨了5倍…
1 个赞
按照我昨天短时间内的测试来看的话,命中缓存和不命中缓存概率大概1:1
即使是 Cursor 也不是用最高端的模型做 FIM 补全的 补全这种小任务用小点的 Qwen-Coder 即可
1 个赞
我用学习的小项目 chat问了4个排序
31w token 消费0.08元
这要是上正式项目,超大上下文输入,token直接起飞
难以想象这要是用起来,一天不得千万token 十几块
1 个赞
轻度项目, 这一周的花销, 最高那个峰后面就用佬友分享的白嫖key所以少了:
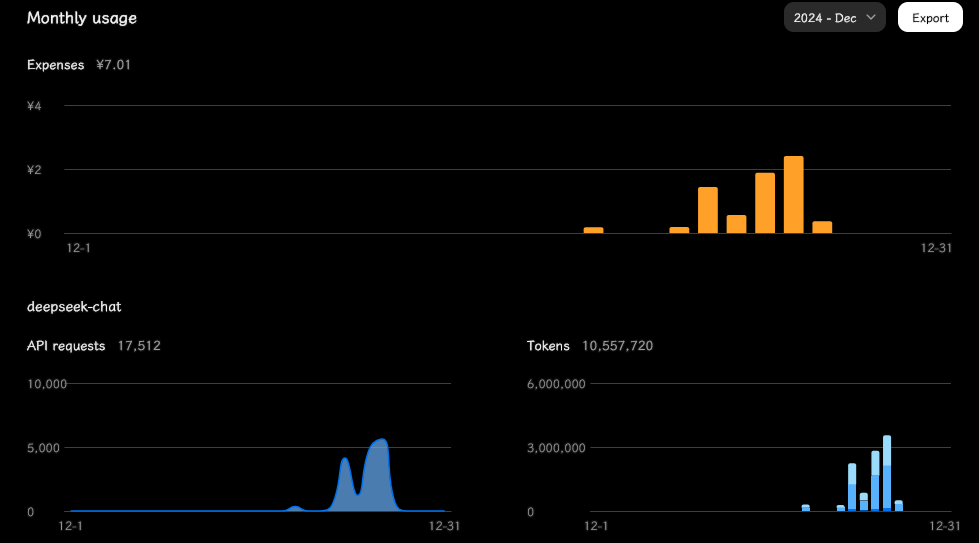
如果涨价 4 倍左右, 可能确实不如原版 Copilot 10刀一个月了, 毕竟我重度使用()
所以为什么 Coder 不能保留 v2.5, 好不容易找到个性价比超高的模型, 阿里那个还是不行(但免费就不要求这么多了)
就按涨价算了一下确实贵,特别是做项目的时候,后面看看能不能有更好的模型把价格压下来一点,不然过了三个月优惠期调用API就太贵了
这个项目更新了可以精简上下文的配置项,可以试试效果
后续出lite,code 这些版本应该会好些
1 个赞
用embedding嵌入额外代码呗,哪有每次全发过去的道理
1 个赞
收到 感谢佬友
试试看,设置改一下,最大token改小一些,触发时间改大一点,减少调用次数。
和最大token无关,因为输出本来就占比很少