GPT-SoVITS :GitHub - RVC-Boss/GPT-SoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
官方demo介绍:耗时两个月自主研发的低成本AI音色克隆软件,免费送给大家!【GPT-SoVITS】_哔哩哔哩_bilibili
功能:
- 零样本文本到语音(TTS): 输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS: 仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持: 支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
- WebUI 工具: 集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
使用过程简介:
- 数据处理
- UVR5 人声处理
- 音频切割
- 音频降噪
- 音频打标
- 校对标注
- 训练
- 数据集准备
- 微调训练
- 推理
教程
环境:Ubuntu 22.04,NVIDIA RTX A6000
采用docker形式部署
docker-compose.yaml文件:https://raw.githubusercontent.com/RVC-Boss/GPT-SoVITS/main/docker-compose.yaml
0. 准备工作
在主目录下创建GPT-SoVITS,并下载docker-compose.yaml,之后模型的镜像大小5G左右
cd ~
mkdir GPT-SoVITS
cd GPT-SoVITS
mkdir logs output reference SoVITS_weights GPT_weights
curl -o docker-compose.yaml https://raw.githubusercontent.com/RVC-Boss/GPT-SoVITS/main/docker-compose.yaml
默认docker-compose.yaml需要做一下调整,需要将 GPT_weights文件夹映射出来。
原始内容:
volumes:
- ./output:/workspace/output
- ./logs:/workspace/logs
- ./SoVITS_weights:/workspace/SoVITS_weights
- ./reference:/workspace/reference
修改后的内容(增加GPT_weights一行映射):
volumes:
- ./output:/workspace/output
- ./logs:/workspace/logs
- ./SoVITS_weights:/workspace/SoVITS_weights
- ./GPT_weights:/workspace/GPT_weights
- ./reference:/workspace/reference
修改完成后,搞启
docker compose up -d
如果是服务器需要开放9874、9873、9872、9871、9880,如果端口有冲突需要修改docker-compose.yaml里的端口映射
用Chrome登陆GPT-SoVITS的WebUI(9874端口):http://0.0.0.0:9874/
1. 数据处理
1.1 UVR5 人声处理

点击Open UVR5-WebUI,看见右边显示UVR5 opened,就可以进入等UVR5处理界面了(端口9873)http://0.0.0.0:9873/
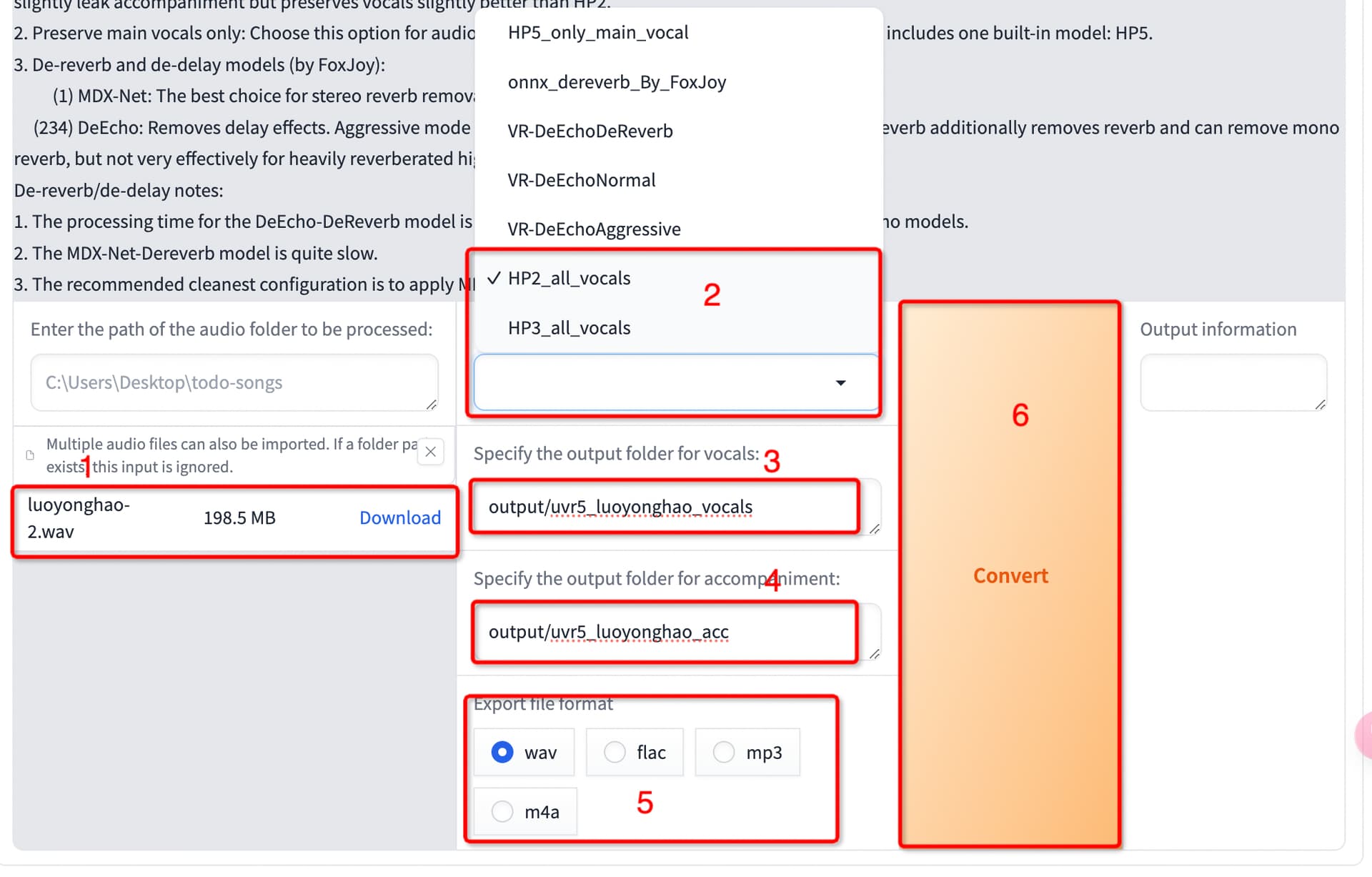
- 上传上面处理的音频文件
- 选择处理人声的模型,我选的是HP2,功能上面有介绍模型
- 修改输出人声目录(output/uvr5_luoyonghao_vocals),一定要在output下面,后续有用到此目录,别用默认,需要训练多个模型区分不开
- 修改输出伴奏目录,不要和人声目录一样
- 选择wav格式
- 开始处理,处理完成后在右侧会有提示
- 关闭界面,回到主界面,把Open UVR5-WebUI勾去掉,关掉UVR服务
1.2 音频切割

- 音频切割的输入目录(output/uvr5_luoyonghao_vocals)
- 音频切割的输出目录(output/slicer_luoyonghao),别用默认,需要训练多个模型区分不开,打标的输入目录
- 其他默认,点击开始分割
1.3 音频降噪

一般不需要
1.4 音频打标

- 输入目录(output/slicer_luoyonghao),切割的输出目录
- 输出目录,默认
- 选择达摩ASR(阿里出品),达摩ASR只能用于识别中文,效果也最好。fast whisper可以标注99种语言,是目前最好的英语和日语识别,模型尺寸选large V3,语种选auto自动就好了
- 开始批量处理
这里如果模型没有会有一个下载过程,等待完成即可
1.5 校对标注

- 打标list文件路径(output/asr_opt/slicer_luoyonghao.list),不是目录,目录为打标的输出目录,文件名为音频切割的输出目录+list(slicer_luoyonghao.list)
- 启动校对服务(端口9871)http://0.0.0.0:9871/
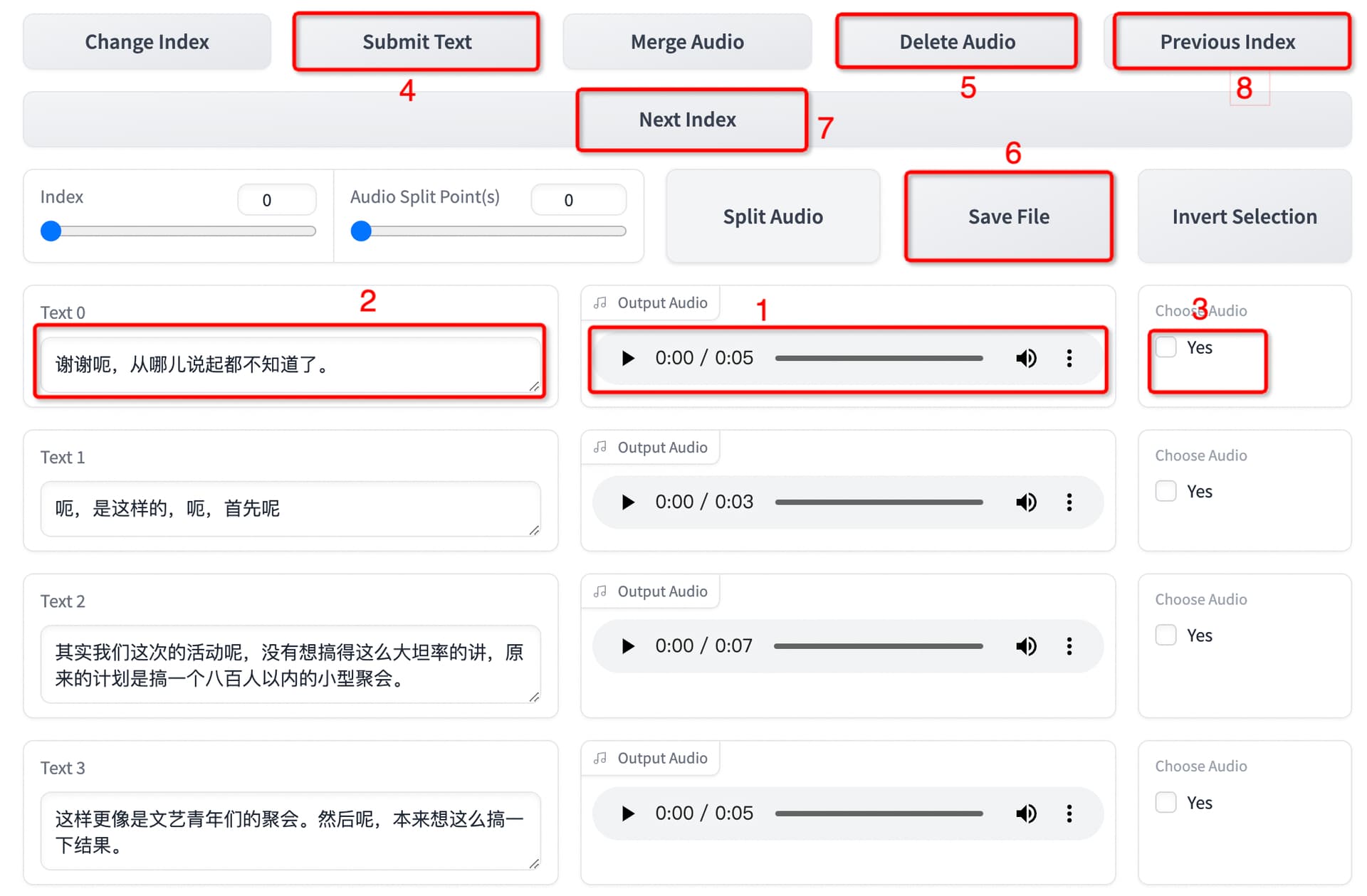
这个步骤比较耗时,主要戴上耳机听音频质量,对照文本校对,如果要求不高,可以跳过。
- 播放音频,听质量,有杂音在后选择
- 文本内容,主要核对文本内容,还有停顿点是否正确
- 选择需要删除音频
- 提交文本修改,在第2步修改了文本,需要先提交,再保存文件
- 删除音频,删音频前有修改文本的,要先提交,再删除
- 保存文件,删除后一定要记得先保存,要不重新搞一遍
- 下一组音频,一定要记得先保存,要不重新搞一遍
- 上一组音频,一定要记得先保存,要不重新搞一遍
校对完成之后,再次确认保存,回到主界面,关闭校对服务。
到这里数据步骤完成。
2. 训练
2.1 数据集准备
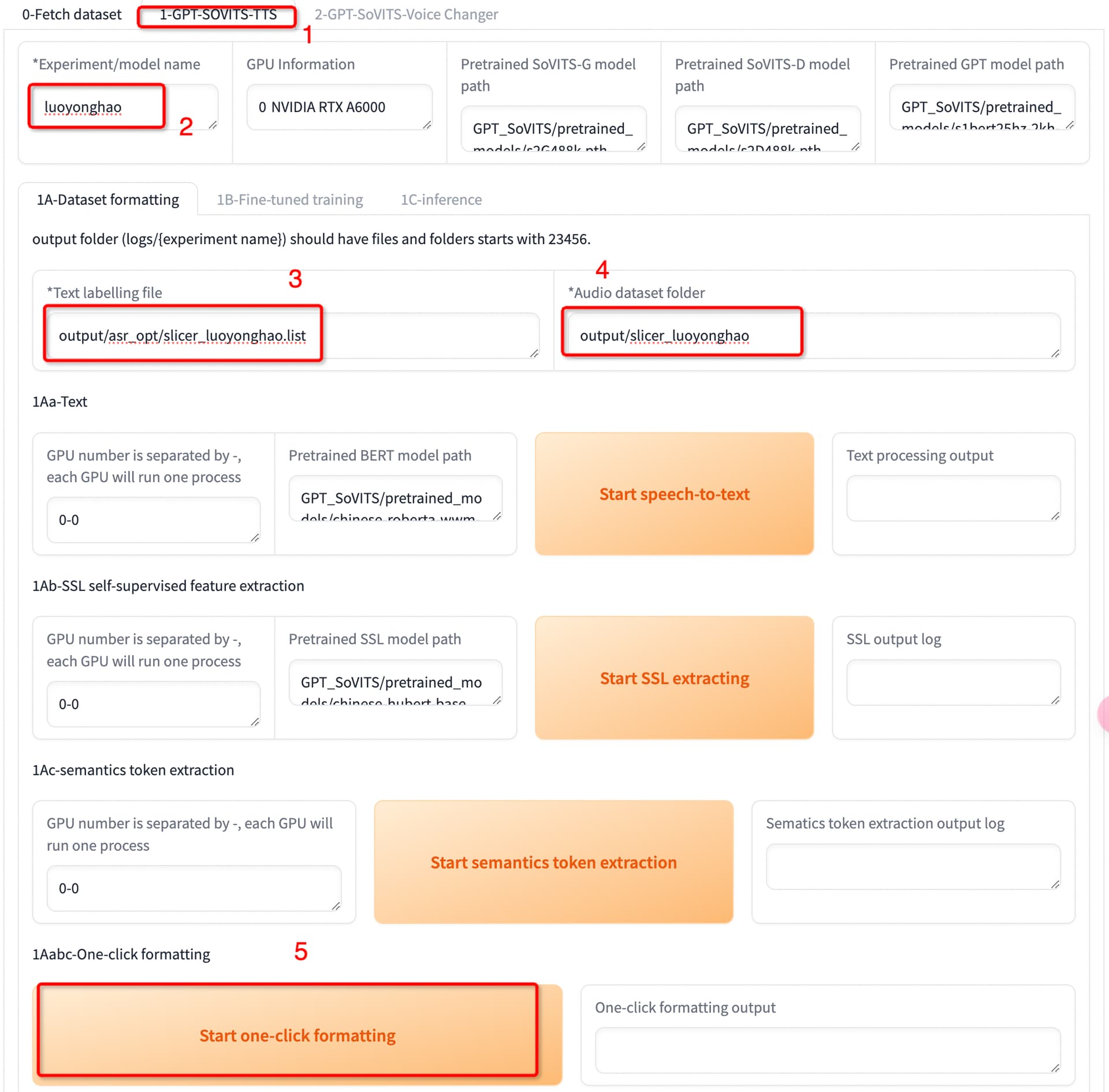
- 切换到训练标签
- 模型名称(luoyonghao)
- 打标list文件路径(output/asr_opt/slicer_luoyonghao.list)
- 切割音频目录(output/slicer_luoyonghao)
- 一键三连进行数据准备
2.1 模型微调
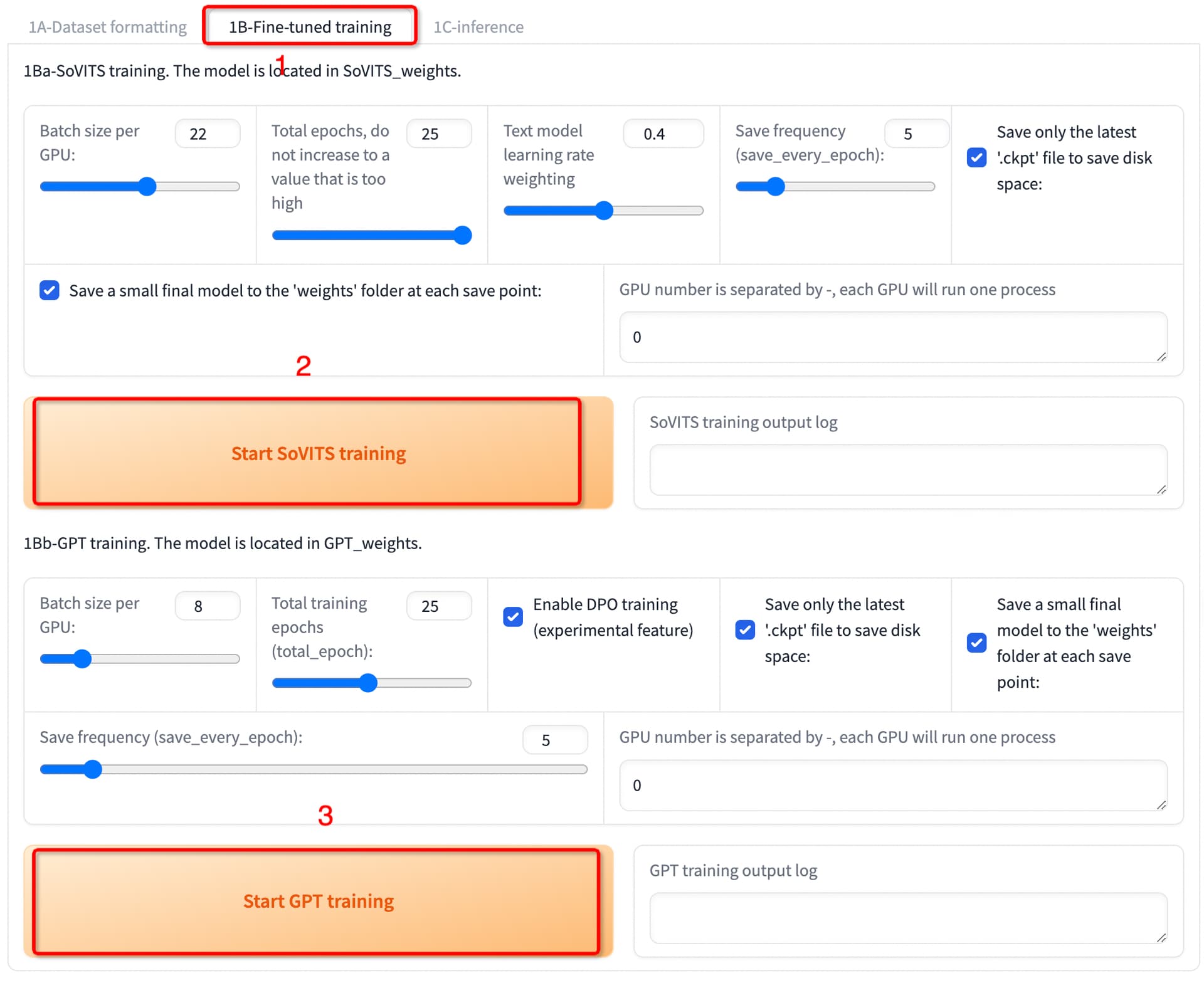
- 切换到微调训练标签
- 开始SoVITS训练,通常默认参数,显卡跑崩了,可以吧Batch size调小一下,训练轮数根据质量再调整训练
- 开始** GPT**训练,如开启DPO训练,Batch size要调整
别两个训练一起执行,一个一个执行
到这里模型的训练就结束了,下面就是期待已久的推理啦 ![]()
3. 推理
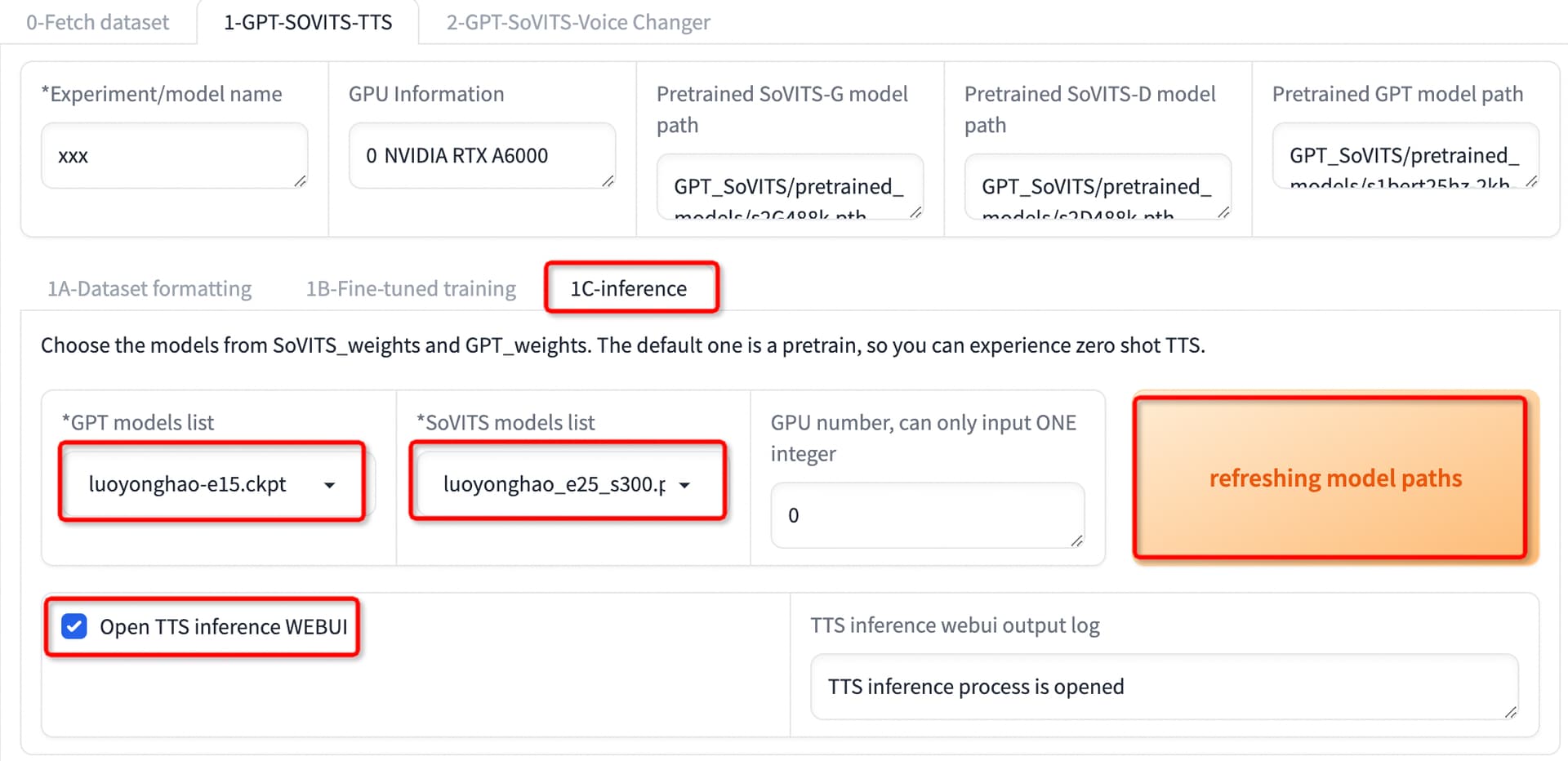
- 切换到推理标签
- 刷新模型
- 选择训练好的GPT模型
- 选择训练好的SoVITS模型,与GPT模型要配对使用
- 启动推理服务(端口9872)http://0.0.0.0:9872/
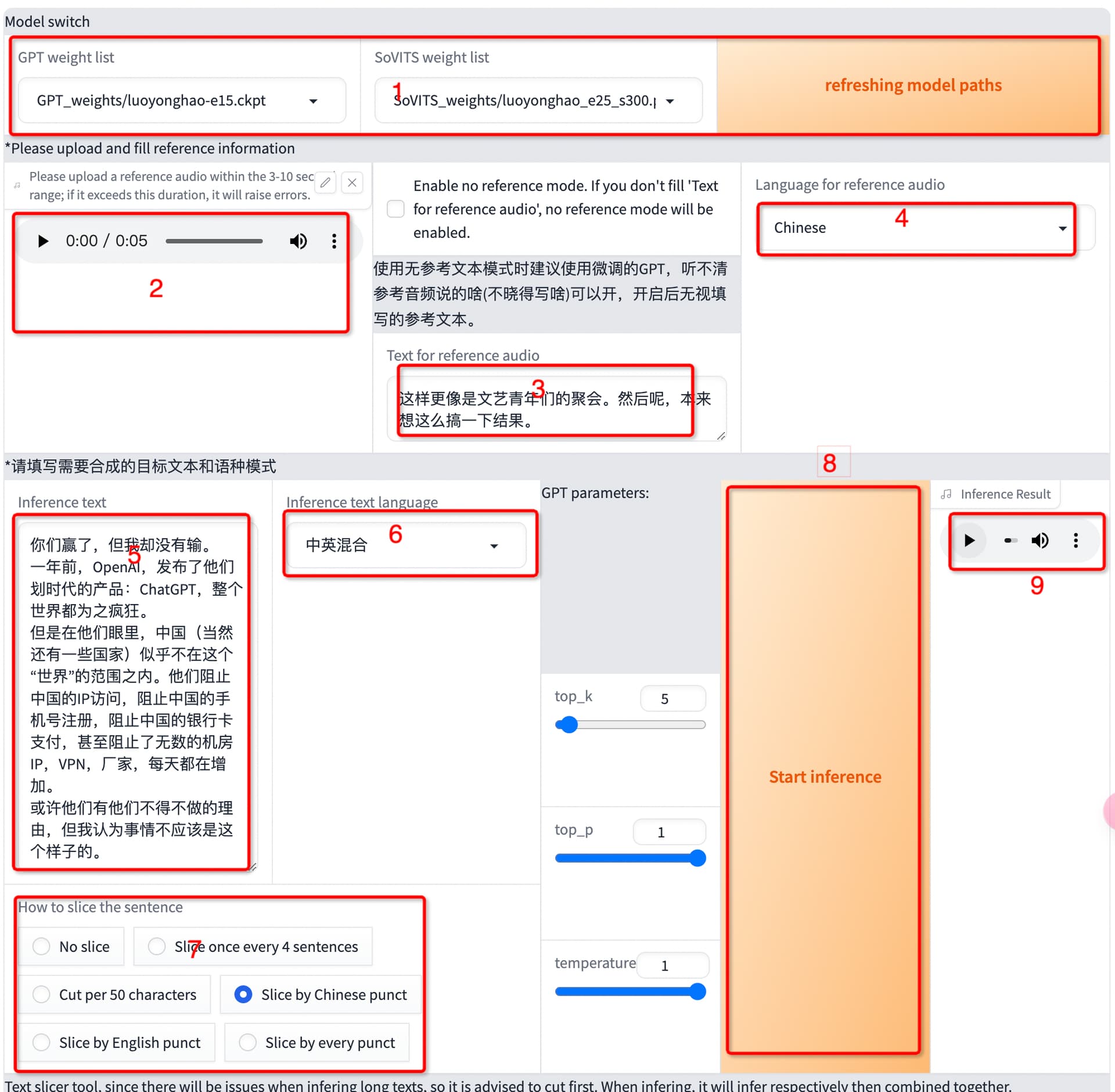
- 这个界面还可以更换模型
- 可以从校对标注服务里找一个音频上传到这里
- 对应的音频文本
- 上面传的音频的语言,训练的基本是中文
- 需要推理的文本填到这里
- 推理的语言,如果文本中包含中文、英文,可以选择中英混合
- 内置的断句方法,可以都试试效果
- 运行推理大法
- 推理后的语音,可以右键下载,推理的结果和上传的音频也有关系
模型分享
分享需要的模型都在SoVITS_weights 和GPT_weights 这两个文件夹,看需要取。
看成果
测试1:
原音:原音
AI推理:AI推理
测试2:
原音:原音
AI推理:AI推理
没有找到好的音频托管,不知道听的效果这么样,相似度还需要再调,尤其中英混合的内容不是很理想,也有可能应用的时候参数等没有微调 ![]() ,欢迎交流。
,欢迎交流。
本帖内容仅为研究分享,如对您的权利造成了影响,请私信联系,我会在第一时间将内容进行删除。