2021 年写来自用的脚本,今天翻出来居然还能 work,贴出来分享给佬友们
baiduOCR.py
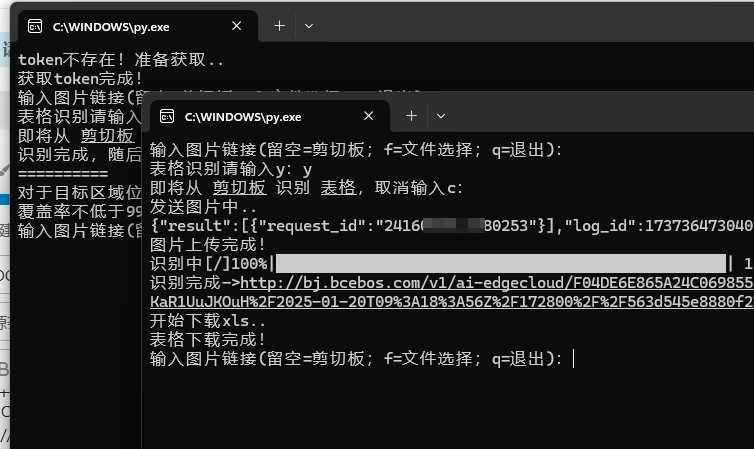
功能特点:
- 识别图片链接、剪切板或图片文件中的纯文字或表格文字
- 纯文字自动粘贴到剪切板,表格弹出 excel 文件下载
- 从 api 自动获取 token 并保存
食用方法:
- 自己申请或搜索公共 api_id 和 api_key。
- 确保本地安装了 python3,安装必要的包
pip3 install requests pillow。 - 保存脚本到本地,双击执行。或者建立快捷方式,使用 Listary、Alfred 等快捷启动工具。
alt+A、shift+cmd+4等工具截取图片,或输入图片链接。- 识别。
- token 失效的话删除同目录下 token 文件重新运行。
测试系统:
Win11/10 MacOS
准确率感觉还可以,特别是表格识别比较方便。有用的话不妨点个赞![]()
佬友们有更好用的方案也欢迎分享~ 最好是截完图直接保存结果到剪切板 ![]()